







<?php
/**
** CSDN Blog's Visit Count
** By change
** 2013.11.3
** http://blog.csdn.net/change518
** 首先遍历获取文章列表,提取每篇博客的地址
** 再通过file_get_contents函数访问这些地址
** 将博客中所有文章访问一遍,从而达到刷访问量的目的
** 由于缓存的原因,访问量一段时间后才会更新
**/
echo "grepping URLs...".PHP_EOL;
//正则,用来提取页面中的博客地址
$pattern='/\<span class="link_title"\>\<a href="\/change518\/article\/details\/\d{7,8}"\>/';
//循环遍历所文章列表,提取文章URL,循环次数为博客实际的分页数
for($i=1;$i<11;$i++) {
$url="http://blog.csdn.net/change518/article/list/$i";
$html = file_get_contents($url);
preg_match_all($pattern, $html, $arr);
if($i==1) {
$list=$arr[0];
} else {
//将每个分页中提取的URL合并到一个大数组中,方便处理
$list = array_merge($list,$arr[0]);
}
}
//从提取结果中获得最终的文章地址
$pattern='/\/change518\/article\/details\/\d{7,8}/';
foreach($list as $value) {
preg_match($pattern, $value, $result);
$urllist[]="http://blog.csdn.net".$result[0];
}
echo "grep URLs finshed. Total URL numbers: ".count($urllist).PHP_EOL;
//print_r($urllist);
//循环访问次数
$count=10;
for($i=1;$i<$count+1;$i++) {
foreach($urllist as $value) {
file_get_contents($value);
}
echo "loop time: $i".PHP_EOL;
}
?>Usage:

效果:
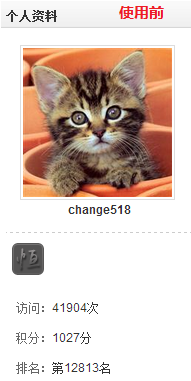

排名的更新需要较长时间才会变化 。。。。















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









