







python常用方法总结
有时候会用到python,但是不经常使用,所以把一些常用方法记录下拉,方便翻阅使用
常用
保留3位小数
round(data, 3)
列表List
列表长度
len(list)
转字符串
str(xx)
list 拼接
list1 + list2
range()是可迭代对象,但不是迭代器
range(start,stop[,step])
用于生成一系列连续的整数,创建一个整数列表,一般用在 for 循环中。
生成全相等数 list
[2 for _ in range(10)]
>>> [2, 2, 2, 2, 2, 2, 2, 2, 2, 2]
生成顺序数 list
list(range(0, 10))
>>> [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list每个元素加一
[ i+1 for i in [1,2,3]]
>>> [2, 3, 4]
数据分组/分箱统计
1.指定区间
res = pd.cut(list,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False,duplicates='raise')
pd.value_counts(res) # 返回分段计数的结果
x : 一维数组
bins :整数,标量序列或者间隔索引,是进行分组的依据,
如果填入整数n,则表示将x中的数值分成等宽的n份(即每一组内的最大值与最小值之差约相等);
如果是标量序列,序列中的数值表示用来分档的分界值
如果是间隔索引,“ bins”的间隔索引必须不重叠right :布尔值,默认为True表示包含最右侧的数值
当“ right = True”(默认值)时,则“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]
当bins是一个间隔索引时,该参数被忽略。
labels : 数组或布尔值,可选.指定分箱的标签
如果是数组,长度要与分箱个数一致,比如“ bins”=[1、2、3、4]表示(1,2],(2,3],(3,4]一共3个区间,则labels的长度也就是标签的个数也要是3
如果为False,则仅返回分箱的整数指示符,即x中的数据在第几个箱子里
当bins是间隔索引时,将忽略此参数
retbins: 是否显示分箱的分界值。默认为False,当bins取整数时可以设置retbins=True以显示分界值,得到划分后的区间
precision:整数,默认3,存储和显示分箱标签的精度。
include_lowest:布尔值,表示区间的左边是开还是闭,默认为false,也就是不包含区间左边。
duplicates:如果分箱临界值不唯一,则引发ValueError或丢弃非唯一
2.
pd.qcut()
3. 分箱后替换为类别
qcut = pd.qcut(label, bins, labels=list(range(0, bins)))
newData['label'] = qcut
字典Dict
字典添加元素和删除元素
-
- 添加字典元素
方法一:直接添加,给定键值对
aa = {'人才':60,'英语':'english','adress':'here'}
print(aa) # {'人才': 60, '英语': 'english', 'adress': 'here'}
#添加方法一:根据键值对添加
aa['价格'] = 100
print(aa) # {'人才': 60, '英语': 'english', 'adress': 'here', '价格': 100}
方法二:使用update方法
添加方法二:使用update方法添加
xx = {'hhh':'gogogo'}
aa.update(xx)
print(aa) # {'人才': 60, '英语': 'english', 'adress': 'here', '价格': 100, 'hhh': 'gogogo'}
-
- 删除字典元素
删除方法一:使用del函数
del[aa['adress']]
print(aa) # {'人才': 60, '英语': 'english', '价格': 100, 'hhh': 'gogogo'}
删除方法二:使用pop函数,并返回值
vv = aa.pop('人才')
print(vv) # 60
print(aa) # {'英语': 'english', '价格': 100, 'hhh': 'gogogo'}
clear函数
clear方法,删除所有
aa.clear()
print(aa) # {},为空
python中的dict(字典):
- 字典是另一种可变容器模型,每个键值对用冒号 (😃 分割,每个键值对之间用逗号 (,) 分割,整个字典由花括号 {}包围 ;
- 字典中的键一般是唯一的,如果重复则后面的一个键值对会覆盖前面的,不过字典的值不需要唯一;
- 值可以取任意数据类型,但键必须是不可变类型,例如字符串,数字或元组,但不能是列表因为列表可变。
读取/保存 excel / CSV
pip install openpyxl
# read
pd.read_excel('./data1.xlsx', index_col=[0], header=0)
pd.read_csv('data.csv')
# save
df.to_csv('data.csv')
Series 与 DataFrame
Series 数据结构:

不设置索引, 默认给个序号索引
a = [“Google”, “Runoob”, “Wiki”]
pd.Series(a)
设置索引
pd.Series(a, index = [“x”, “y”, “z”])
Series转np
label = np.array(label, dtype=float)
DataFrame 数据结构:
表格型数据, 可以看作共用一个索引的Series
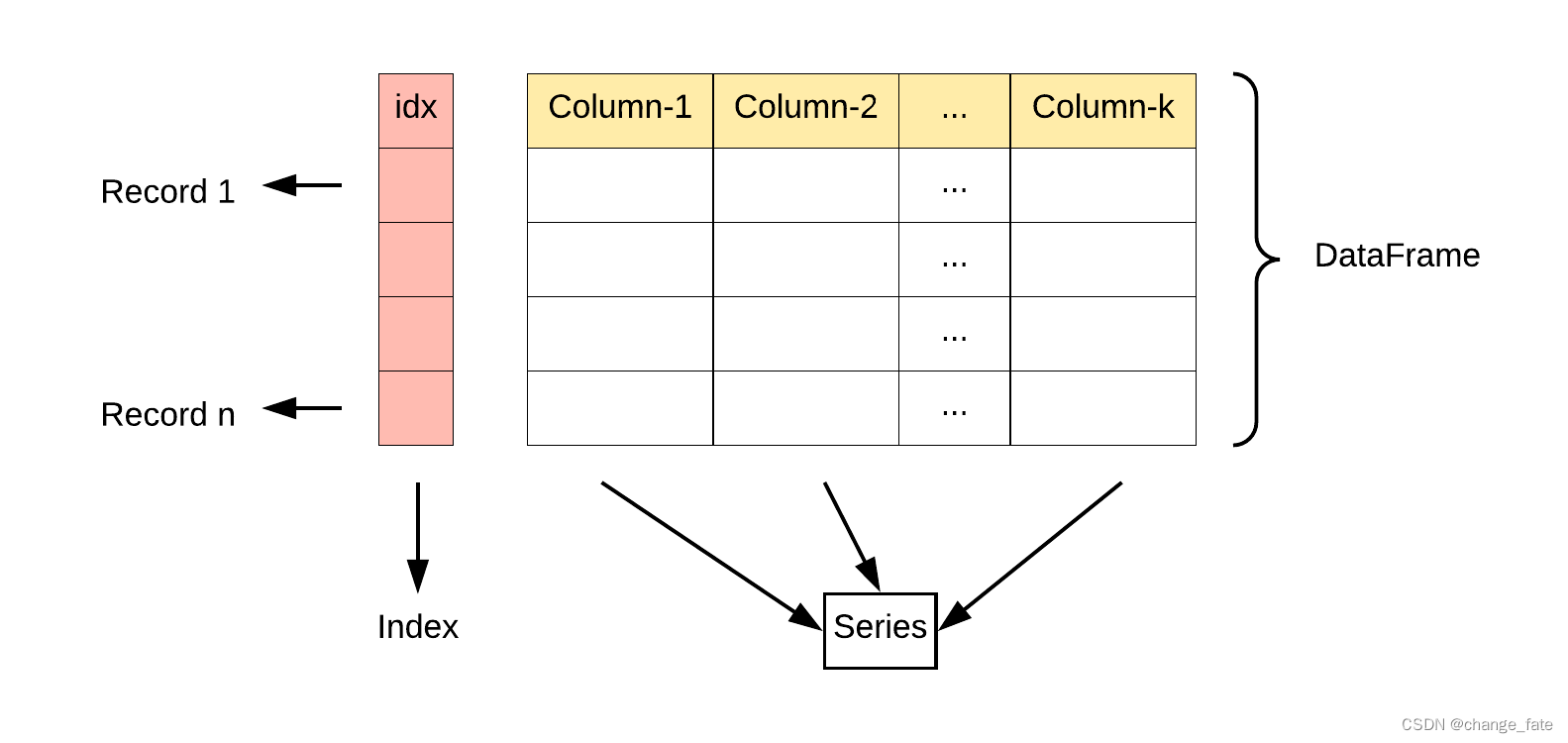
构造方法:
pandas.DataFrame( data, index, columns, dtype, copy)
data:一组数据(ndarray、series, map, lists, dict 等类型)。
index:索引值,或者可以称为行标签。
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
dtype:数据类型。
copy:拷贝数据,默认为 False。
显示dataFrame
zfDf.head()
查看属性
df.columns # 列元素
创建dataframe
pd.DataFrame(data, [index])
数组创建df
df2 = pd.DataFrame([
[1,1,1,1],
[2,2,2,2],
[3,3,3,3],
])
df2.columns = ['label', 'a', 'b', 'c']
df2 = df2.set_index('label')

字典创建df
df = pd.DataFrame({
'label': ['a', 'b', 'c'],
1: [1,1,1],
2: [2,2,2],
3: [3,3,3],
})

属性:
loc : 返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1
df.loc[1]
df.loc[[0, 1, 2, 3]]
设置索引set_index与reset_index:
set_index 将DataFrame中某一列设置为索引,同时丢弃原索引;
reset_index 用于复位索引——将索引加入到数据中作为一列或直接丢弃,可选drop参数。
返回新的df
df = pd.DataFrame({
‘label’: [‘a’, ‘b’, ‘c’],
1: [1,1,1],
2: [2,2,2],
3: [3,3,3],
})
df

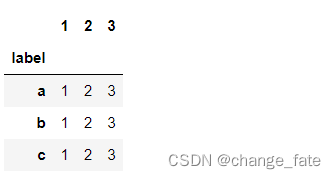
# label 列作索引列
df.set_index('label')
df.reset_index()
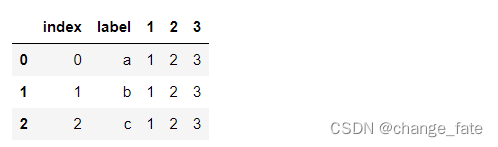
# 新增一个索引列, 常用
df.reset_index(drop=True)

dataFrame 按列名获取列
df['列名']
dataFrame 按列索引获取列
df.iloc[:,2]
dataFrame 删除列
del df[‘列名’] # 按列名
df.drop(columns=‘列名’) # 按列名
df.drop(columns=[‘b’, ‘c’]) # 按列名(多列)
dataFrame 删除行
df.drop(labels=0) # 按列名
df.drop(index=0) # 按索引
dataFrame 在某列插入列
DataFrame.insert(loc, column, value,allow_duplicates = False)
# eg
newData.insert(loc=2, column='label2', value=qcut)
df 设置标签
oneDf.columns = allCol
df修改单个标签
tempList = newData.columns.to_list()
tempList[0] = ‘newLabel’
newData.columns = tempList
删除空值
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
筛选符合条件的列
# 获取第一列, 要求大于0 且小于1
df[zfDf.iloc[:, 1] > 0][zfDf.iloc[:, 1] < 1]
df[zfDf.iloc[:,1].apply(lambda x: 0 < x < 1)] # 推荐
df横向合并
pd.merge(df1, df2, on='合并列标签', how='inner')
df 纵向合并
newData = pd.concat([df1, df2, df3], ignore_index=True)
删除含元素的标签的行
for i in allCol:
newData.drop(newData.index[(newData[i] == '--')], inplace=True) # 删除含'--'行
newData.drop(newData.index[(newData[i] == '----')], inplace=True) # 删除含'--'行
统计series个元素个数
pd.value_counts(values, sort=True, ascending=False, normalize=False, bins=None, dropna=True)
返回一个序列Series,该序列包含每个值的数量
sort: 是否要进行排序(默认进行排序,取值为True)
ascending: 默认降序排序(取值为False),升序排序取值为True
normalize: 是否要对计算结果进行标准化,并且显示标准化后的结果,默认是False
bins: 可以自定义分组区间,默认是否
dropna: 是否包括对NaN进行计数,默认不包括
df属性描述
df.describe()
df最大值
df.describe()['max']
设置随机种子
def setSeed (seed):
# 生成随机数,以便固定后续随机数,方便复现代码
random.seed(seed)
# 没有使用GPU的时候设置的固定生成的随机数
np.random.seed(seed)
# 为CPU设置种子用于生成随机数,以使得结果是确定的
torch.manual_seed(seed)
# torch.cuda.manual_seed()为当前GPU设置随机种子
# torch.cuda.manual_seed(args.seed)
setSeed(0)
可视化
epochsList = np.arange(0, epochs, 1) # [0,1,2,3...]
plt.subplot(211)
plt.plot(epochsList, accArr)
plt.title('acc')
plt.ylabel("acc")
plt.show()
重新生成dataframe
pd.DataFrame(data, index=index,columns=columns)
# pd.DataFrame(df,columns=['a', 'c'])
热力图:
import seaborn
seaborn.heatmap
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annotkws=None, linewidths=0, linecolor='white', cbar=True, cbarkws=None, cbar_ax=None, square=False, ax=None, xticklabels=True, yticklabels=True, mask=None, **kwargs)
data:矩阵数据集,可以使numpy的数组(array),如果是pandas的dataframe,则df的index/column信息会分别对应到heatmap的columns和rows
vmax,vmin, 图例中最大值和最小值的显示值,没有该参数时默认不显示
linewidths,热力图矩阵之间的间隔大小
cmap,热力图颜色
ax,绘制图的坐标轴,否则使用当前活动的坐标轴。
annot,annotate的缩写,annot默认为False,当annot为True时,在heatmap中每个方格写入数据。
annot_kws,当annot为True时,可设置各个参数,包括大小,颜色,加粗,斜体字等:
sns.heatmap(x, annot=True, ax=ax2, annot_kws={‘size’:9,‘weight’:‘bold’, ‘color’:‘blue’})
fmt,格式设置,决定annot注释的数字格式,小数点后几位等;
cbar : 是否画一个颜色条
cbar_kws : 颜色条的参数,关键字同 fig.colorbar,可以参考:matplotlib自定义colorbar颜色条-以及matplotlib中的内置色条。
mask,遮罩
cmap=“YlGnBu”:数字越大,颜色越深
data = [
[1,2,3],
[2,3,4],
[4,5,6]
]
df = pd.DataFrame(data)
sns.heatmap(df, cmap="YlGnBu", annot=True, fmt='.2g')
pytorch相关
某个数出现次数统计
import torch
aa = torch.Tensor([1,2,3,4,1,2,3])
(aa==4).sum().item()
>>> 1















 1770
1770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









