







前言
这个是笔者参考了很多算法写出来的,目测可以挖掘最小支持度为0.01的数据,但是还有很多不足,最大的缺点就是太慢了,因为用的数据结构不是很好,如果有更好的可以自己修改,笔者摆烂不想改了。跑完整个8万条数据大概要1000秒。
一、专业名词解释
假如现在有一组购物数据,共4条记录,每条记录都是一个顾客在超市购买商品产生的数据(我们只关心顾客买的种类,不关心它买了这类商品的数量,因为我们要找到是商品种类之间的关联,不是数量的关联)。
现在假设有5种商品,A B C D E,为了程序实现,把它换成数字表示更好一点A–>1, B–>2, C–>3, D–>4, E–>5 。
下面是这4条数据,把种类ABCDE换成数字 1 2 3 4 5。
[A C D] --> 1 3 4
[B C E] --> 2 3 5
[A B C E] --> 1 2 3 5
[B E] --> 2 5
1、什么是关联规则
现在有一个人,超市老板小红,她拿到了这组数据,想找出哪些商品是有关联的,关联是什么意思呢?举个例子,比如,你想买个泡面,你一桶面不够吃,两桶吃不了,你是不是就想,要不我在顺便买个香肠?还不够!在加个蛋呢?实在不行,再加个鸡腿!
好了,现在你就明白了,泡面、香肠、鸡蛋、鸡腿,这4个商品可能就是关联的,如果超市把这几个放在一起,你在买泡面的时候,是不是一不小心就多消费了(万恶的资本家啊),你就会不由感受到,现在连泡面都吃不起了。
2、支持度
继续思考怎样找出这些关联商品,小红现在有4条数据记录(实际的超市,每天产生的数据可能上千,我们这里就简化一点,方便理解),小红很聪明,她认为,如果某一种商品组合(这个组合,可以是1个,或者2个,甚至3个以上的不同种类商品的组合),在整条数据库中出现的次数太少,那我就认为他们没有关联, 这个道理很显然,比如,商品组合AB,假如A是白酒,B是头孢(不要问我为什么超市会卖药,反正它现在就得卖→_→),这两个一起吃可能会中毒,那么你在买酒的时候肯定不会刻意去买头孢吧(不要说是给女朋友买的 ̄へ ̄,来自单身狗的怨念),换句话说,如果你买了A,大概率不会买B,甚至会刻意不去买B,那么AB同时出现在一条购物记录的次数必然不会太多,因此可以认为两者没有关联。
那小红又在想,这个商品组合出现的次数小于多少,我才认为它是无关联的呢?
这个次数可以随意规定,我们称为支持度。但你试想一下,如果这个数定的太小,连 酒 和 头孢 您都认为有关联,然后 你把这两个摆在一起卖,显然不合适,算法意义也不大。如果定的太高,很多商品本来有关联,结果你定的太高,这些商品组合出现次数都不能满足这个数,那么这些商品组合你也就找不出来,算法也就失去了意义。所以这个值一定要取的合适才好。
这个取值就称为 最小支持度。
对应于我们文中的例子,
A在四条记录中出现了2次,它的最小支持度min_support(A)=2,这是以它出现的次数作为最小支持度。
还可以用A出现的概率来表示,就是 A出现的次数 ÷ 总记录次数
A出现的次数是2,我们总共有4条数据,最小支持度也可以表示为:
min_support(A)=2/4=0.5
在看一下BE的最小支持度:
BE同时出现的次数为3次,总记录数依旧是4条,
那 min_support(BE)=3 或 min_support(BE)=3/4
(在代码中用那种形式表示都可以,表示的意义是一样的)
3、置信度
小红又要开始想了(前面提到过她很聪明,手动狗头),只用次数大小来确定是否关联,是不是太草率了,假如你去买泡面,这个月钱快见底了(肯定啊,谁有钱会吃泡面),你打算买3或4包,到了地方,里面有很多口味的,比如麻辣,原味,三鲜,酸菜,但你就喜欢麻辣的,本来是想全买麻辣口味的,可惜的是每种口味都只剩2包了,无奈之下,你买了2包麻辣,还有1包酸菜的,走之前还拿了个蛋,,,这个时候你的这条购物信息是 {麻辣, 酸菜, 蛋},前面说了,我们不关心数量,只关心种类。
这个时候,虽然购物记录里面有 麻辣,和酸菜两种物品,但你要知道,你刚开始是想全买麻辣的,是因为麻辣的没了,才买了酸菜。虽然{麻辣,酸菜}同时出现了,且在计算支持度时,还提供了次数,可能会误认为麻辣和酸菜是 相关的,但其实你知道你是无奈才选的酸菜泡面,麻辣和酸菜并不是相关的,甚至顾客在买麻辣口味的时候,刻意不会去购买酸菜口味的泡面,它们是反相关的。
如果能计算出,顾客在买了麻辣的情况下,同时买了酸菜的概率多好啊,如果这个概率大,就表明顾客买了麻辣的,还要买酸菜的情况不是偶然,顾客就是同时喜欢吃这两种口味,每次买泡面,总是同时买这两种口味,两种口味是关联的。如果概率小,就表明顾客只喜欢其中一种口味,买酸菜是因为无奈之举,超市没货了。
现在就清楚了,我们算一下这个概率,很明显是条件概率的计算,用AB表示这两种商品,则 AB同时出现的次数 ÷ A出现的次数,就是顾客在买A的前提下,又买了B的概率,这个概率又称为 置信度,这个式子的意思表示,对于顾客 <买了A,同时又买了B的行为> 有多少自信,有多少把握,认为这个商品组合是有关联的。
和支持度类似,我们也得自己确定一个数,称为最小置信度,大于这个数就认为这个商品组合有关联。
下面对于文章给出的数据计算一下置信度:以BC为例
如:BC同时出现的次数为2,B单独出现的次数为3,
则置信度confidence(C–>B)=2/3,称为顾客 <买了C的情况下,又买了B的这个行为> BC具有关联性质的把握为2/3,换句话说,就是顾客买了C后,有 2/3 的概率去买B。
再算一下 顾客买了B的情况下,又买了C的置信度是多少,
BC同时出现的次数依旧为2,C单独出现的次数为3
confidence(B–>C)=2/3,称为顾客 <买了B的情况下,又买了C的这个行为> 的可信度2/3,换句话说,就是顾客买了C后,有 2/3的概率去买B。
(当然,我们使用的数据太少,有些数据计算出来是100%,这完全是巧合,如果数据足够大,这个概率就就不会这样夸张了)
!!!要注意 :只有当这个商品组合的支持度大于它的最小支持度并且置信度大于最小置信度,我们才认为这个商品组合是强关联的,我们称这个商品组合为频繁项集。(为了简化代码,我仅仅只用了支持度,如果某种商品组合的支持度 大于 最小支持度,就认为是频繁项集。 并没有用到最小置信度,,如果读者有能力,可以自己做出改进,只需要在求频繁项集的时候,在保持这种商品组合的支持度大于最小支持度的情况下,同时保证该商品组合的置信度 大于 最小置信度 即可。)
(从公式可以看出,AB同时出现的次数其实就是AB的支持度,A单独出现的次数就是A的支持度,支持度可以用次数表示,也可以用频率表示,如用概率表示,则置信度confidence公式如下)
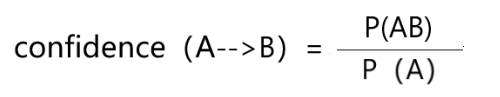
4、提升度
(也是一个度量某种商品组合是否为频繁项集的量(和支持度,置信度类似),大家可以了解一下,这个量我在代码中也没有体现,就是为了简化代码)
这时候小红还觉得不放心,她又思索了一下,发现这样一种情况:假如原来一个商品X,在总记录中出现的概率是80%(也就是支持度),但是XY两种商品同时出现的概率是50%,是不是在一定程度上,Y商品的出现反而降低了原来的商品X的销售额?
我们首先来看一个式子,
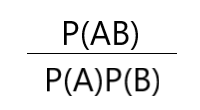
分析这个式子,对于P(AB),
如果A,B两个相互独立,即A发生不会影响到B,那么P(AB)=P(A)P(B),显然,最后这个式子结果为1
如果A,B不独立,即A发生会影响
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6970
6970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









