







之前一直是让输出的,然后配置了C++插件后(关于VSCode如何配置C++环境请参考我本篇文章:https://blog.csdn.net/changyana/article/details/122546507)写代码需要手动输入一些变量,结果发现无法输入,记下解决办法:
找出设置,然后输入runInTerminal,在用户和工作区中的Run in Terminal都打上勾。就设置成功。
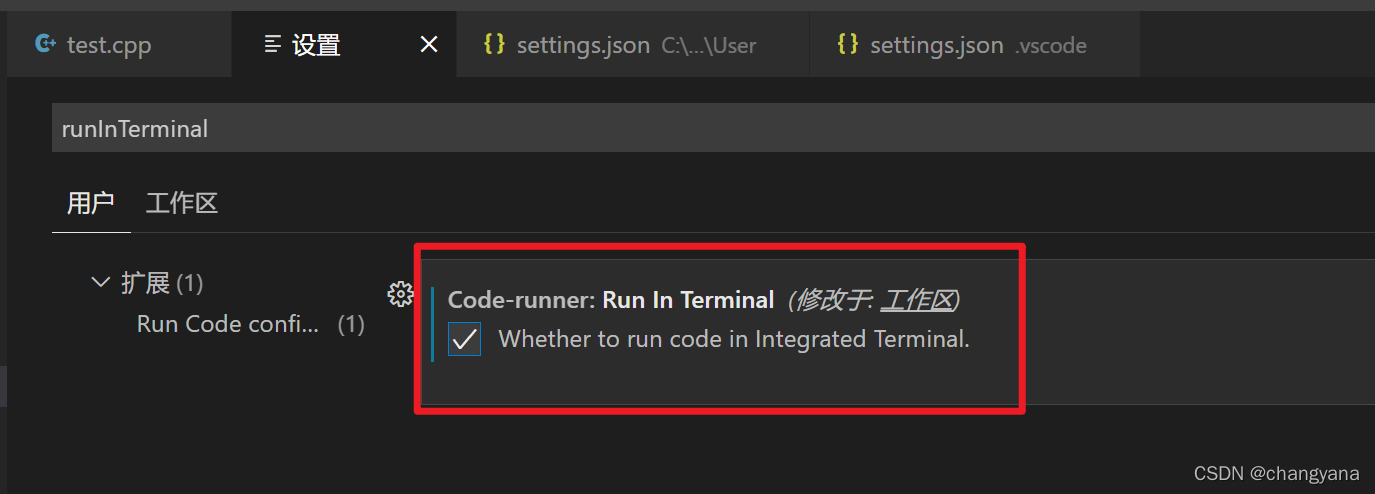
可以看到在setting里的此项设置为true,即可。

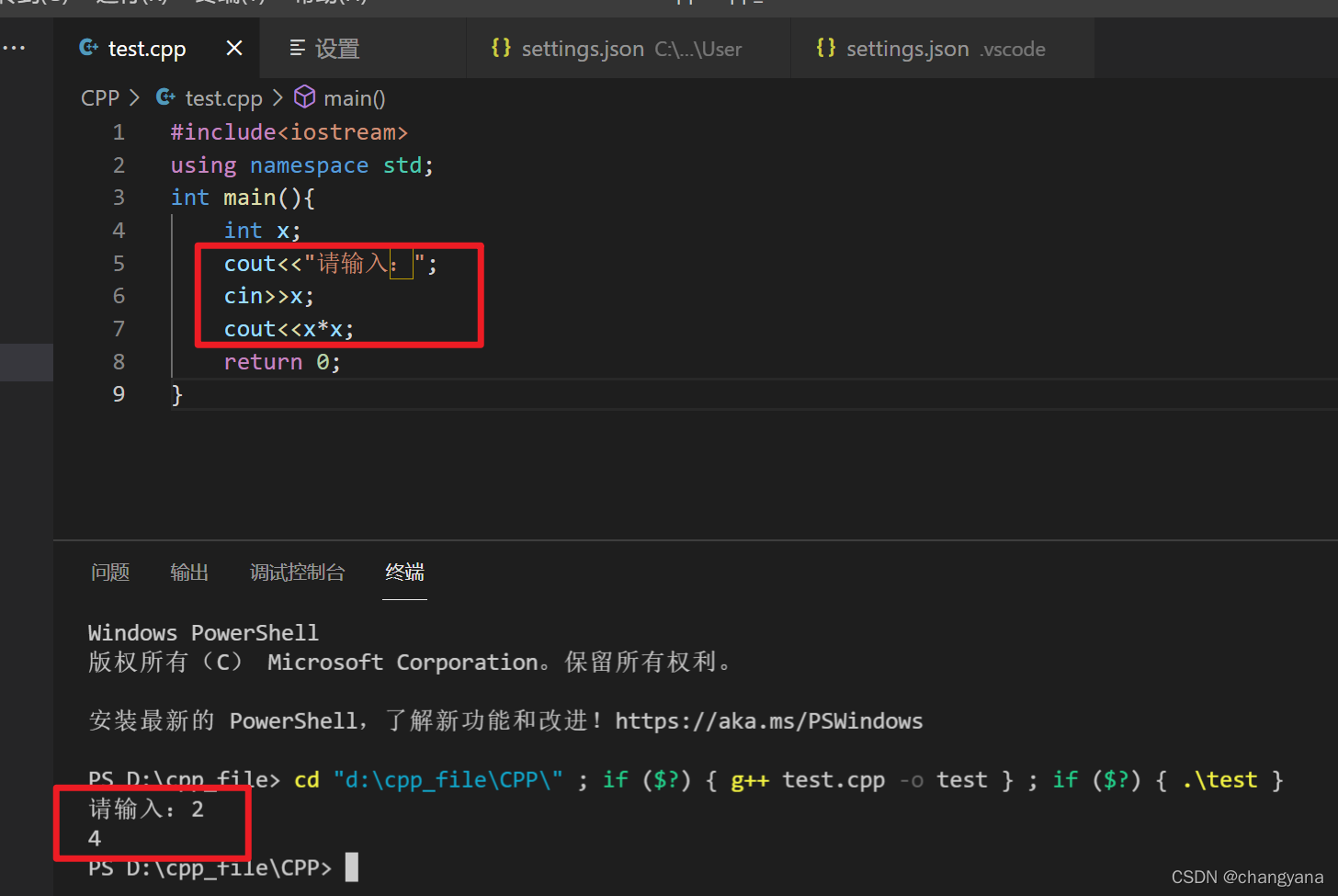
然后运行代码便可以进行输入了! 大功告成!

















07-19
 1144
1144
1144
03-27

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









