







本文将针对UNIX磁盘缓冲的原理及分配回收展开讨论,并在最后用OO观点来对缓冲进行建模。
概述
在UNIX家族的内核中,
都有一个buffer cache,用于缓冲磁盘与文件系统之间的数据交换。这是个模块不仅包含内存管理功能,还提供了一套算法来管理该内存中缓冲的数据,如延迟写等等。
为了减少内存碎片,提高访问效率,减少系统调用的次数,在大多数复杂/庞大的软件系统中都会用到内存池或者对象缓冲等来管理内存。然而,内存是一片雷区,在管理内存时,需要特别小心,如果造成泄漏,就会导致系统内存耗尽。在应用程序中,这不算大问题,因为它总要退出运行。退出后,其未释放的资源会被系统自动回收。在内核中情况就不一样了,泄露了一块内存,就少掉了一块,通常只有通过reboot来回收了。
对于内核而言,还有一个重要的问题就是同步问题。这是任何一个内核开发者都需要时刻注意的问题:抢占、中断等都是导致需要同步的一个重要原因。同步还带来了内核函数/系统调用的重入问题,因此在开发内核时需要时刻小心。因为UNIX System V是非抢占式内核,也就是内核执行期间不会被其他进程抢占,除非进程自动让出处理器,因此不需要特别考虑同步,但是中断是必须考虑的。
说到中断和抢占,有几个概念需要了解:进程上下文、中断上下文;用户态、内核态。一个进程执行中,可以在内核态或用户态执行,但处于进程上下文;中断是一个特例:不属于任何进程,处于中断上下文,运行在内核态。……有点扯远了……咳…… 罗嗦了这么半天,下面言归正传。
原理及实现
UNIX System V的磁盘缓冲称为buffer cache,
该缓冲位于文件系统和磁盘驱动层中间,用于缓冲系统对磁盘的访问,并降低对磁盘操作的频度。系统初始化时分配了一些缓冲形成缓冲池,每个缓冲元素包括两部分:数据和缓冲描述。有些时候将数据及其描述合称为缓冲。一块缓冲可以由逻辑设备号以及其映射的磁盘块的块号来标识。
磁盘块与缓冲池中的元素是一一对应关系,否则将导致数据不一致。当需要读一个磁盘块时,内核首先从该缓冲池中查找,如果找到,则直接读取缓冲,如果未找到,则分配一个缓冲,并从磁盘中读取数据。这就需要一个最近最少使用算法来决定分配哪个缓冲。当需要写一块磁盘时,首先写到缓冲池中以便后续访问能够高效地进行。当找不到可用的缓冲时,先将某个缓冲写到磁盘(延迟写),然后再写到该缓冲。
为了管理该缓冲池,利用了两种数据结构:哈希队列(hash Q)和双向链表(double-linked list)。这两个数据结构中存放的元素是称为buffer header的结构体,该结构体如图所示:

其中,状态包括:
1、buffer的闲/忙(锁住/解锁);
2、数据有效;
3、延迟写;
4、正在读/写;
5、有进程在等待该buffer的释放。
对于hash Q和free list的使用也比较简单:hash Q存放已经分配的buffer,而free list上存的都是空闲的buffer。如果某空闲buffer是回收利用的,那么,其不但链在free list上,还链在了hash Q上(注:初始化后buffer都存放在free list上,并没有链到hash Q上)。
那么,这些buffer将如何进行分配和回收呢?原理很简单,就是一些hash Q和double-linked list的操作。只不过这些操作涉及到一些分配逻辑(算法)。下面是典型的两种状态:

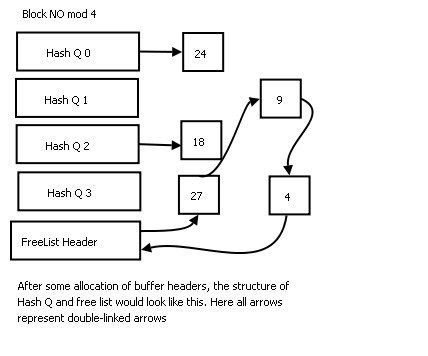
在分配buffer时,有5种典型的情况:
1、在hash Q上找到需要的buffer(代表一个磁盘块),且该buffer可用;
2、在hash Q上找到需要的buffer,但该buffer正忙;
3、没有在hash Q上找到需要的buffer,从free list分配;
4、没有在hash Q上找到需要的buffer,从free list分配,但该buffer状态为delay-write;
5、没有在hash Q上找到需要的buffer,free list也为空;
这样我们就得到getblk实现的伪代码:
struct buffer header * getblk(文件系统号,块号)
{
while ( 没有找到buffer )
{
if (该block在hash Q上)
{
if (buffer正忙) /* 第2种情况 */
{
sleep_on(buffer释放的事件); /* 参考UNIX的加锁解锁:等待事件及唤醒 */
}
else
{
将buffer标记为正忙; /* 第1种情况 */
从free list中删除该buffer;
返回该buffer的指针;
}
}
else
{
if (free list上没有可用buffer) /* 第5种情况 */
{
sleep_on(buffer释放的事件);
continue;
}
从free list删除该buffer;
if (该buffer状态是delay-write) /* 第4种情况 */
{
异步将该缓冲写到磁盘;
continue;
}
/* 第3种情况 */
从旧的hash Q上删除该buffer;
将该buffer放到新的hash Q;
返回该buffer的指针;
}
}
}
{
while ( 没有找到buffer )
{
if (该block在hash Q上)
{
if (buffer正忙) /* 第2种情况 */
{
sleep_on(buffer释放的事件); /* 参考UNIX的加锁解锁:等待事件及唤醒 */
}
else
{
将buffer标记为正忙; /* 第1种情况 */
从free list中删除该buffer;
返回该buffer的指针;
}
}
else
{
if (free list上没有可用buffer) /* 第5种情况 */
{
sleep_on(buffer释放的事件);
continue;
}
从free list删除该buffer;
if (该buffer状态是delay-write) /* 第4种情况 */
{
异步将该缓冲写到磁盘;
continue;
}
/* 第3种情况 */
从旧的hash Q上删除该buffer;
将该buffer放到新的hash Q;
返回该buffer的指针;
}
}
}
第一种情况相当简单,不做说明。第三种情况,将从free list队首取出一个buffer(最近最少使用算法),并将其放到对应的hash Q上。第四种情况,kernel发现该buffer标志为delay-write,因此,将执行异步写。而请求该buffer的进程将从free list上下一个元素开始继续查找。第五种情况, 进程将在该buffer池的等待队列上等待任何一个buffer可用。
第二种情况最为复杂,因为这里涉及到多个进程竞争同一个buffer的问题,出现这种情况时,会有多个进程在该buffer的等待队列上等待该buffer(注意与第5种情况的等待的区别)。当进程A得到一个buffer之后进入睡眠。这时,进程B也请求该buffer,发现该buffer忙,因此在对该buffer标记为“in-demand(有需要)”,然后将自己放到该buffer的等待队列上睡眠。同样可能有进程C进行该操作了。这样,当唤醒该队列上的进程时,B和C都被唤醒,当C先执行时,锁定了该buffer,因为其他原因进入睡眠,轮到B执行,这是B应当检查该buffer是否被锁住,同时还要检查该buffer是否被C进程分配给了其他的块。如果是后者,B应该再次查找hash Q甚至free list。
在这里,由内核保证所有睡眠的进程都能够被唤醒,因此不存在永久的睡眠。理论上会有进程“饿死”,永远睡眠(如第四种情况,很多进程在睡眠,然而某个进程却始终没有得到buffer),但由于buffer很多,基本上不会有进程“饿死”。
另外需要留意的是中断问题。因为对于buffer list和hash Q的操作都是对全局数据的操作,需要禁用中断来防止重入——delay-write导致异步写,写完后会在中断中处理buffer的释放。由于这里的算法比较简单,仅仅列出了最主要的矛盾(呵呵,拽一下),因此,一般来说实现都会比较困难。如Linux 2.6.22和0.99.15代码较长,且完成的功能比这里列出的复杂一些。下面是Linux 0.99.15的实现(注:由于Linux 0.99.15的实现与上面的伪代码最相近,因此采用它作为示例。另:省略掉某些不影响说明的代码):
#define BADNESS(bh) (((bh)->b_dirt<<1)+(bh)->b_lock)
struct buffer_head * getblk(dev_t dev, int block, int size)
{
struct buffer_head * bh, * tmp;
int buffers;
static int grow_size = 0;
struct buffer_head * getblk(dev_t dev, int block, int size)
{
struct buffer_head * bh, * tmp;
int buffers;
static int grow_size = 0;
repeat:
bh = get_hash_table(dev, block, size); //在hash Q上查找,找不到则得到NULL,如果找到的buffer忙,则sleep
if (bh) {
if (bh->b_uptodate && !bh->b_dirt) // 第1、2种情况
put_last_free(bh);
return bh;
}
bh = get_hash_table(dev, block, size); //在hash Q上查找,找不到则得到NULL,如果找到的buffer忙,则sleep
if (bh) {
if (bh->b_uptodate && !bh->b_dirt) // 第1、2种情况
put_last_free(bh);
return bh;
}
//在hash Q上没找到。第3、4、5种情况
……
……
for (tmp = free_list; buffers-- > 0 ; tmp = tmp->b_next_free) {
……
if (!bh || BADNESS(tmp)<BADNESS(bh)) {
bh = tmp;
if (!BADNESS(tmp))
break;
}
……
if (!bh || BADNESS(tmp)<BADNESS(bh)) {
bh = tmp;
if (!BADNESS(tmp))
break;
}
}
……
if (!bh) {
if (!grow_buffers(GFP_ATOMIC, size))
sleep_on(&buffer_wait);
goto repeat;
}
wait_on_buffer(bh);
if (bh->b_count || bh->b_size != size)
goto repeat; // 不符合要求,重试查找,先在hash Q上找,然后是free list
if (bh->b_dirt) { // 延迟写,第4种情况
sync_buffers(0,0);
goto repeat; // 重试查找,先在hash Q上找,然后是free list
}
if (!bh) {
if (!grow_buffers(GFP_ATOMIC, size))
sleep_on(&buffer_wait);
goto repeat;
}
wait_on_buffer(bh);
if (bh->b_count || bh->b_size != size)
goto repeat; // 不符合要求,重试查找,先在hash Q上找,然后是free list
if (bh->b_dirt) { // 延迟写,第4种情况
sync_buffers(0,0);
goto repeat; // 重试查找,先在hash Q上找,然后是free list
}
// 第3种情况:重置该buffer的属性,并作适当的操作。
……
……
remove_from_queues(bh); // 从旧的hash Q上删除该buffer, 并从free list中将其删除
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh); //将该buffer放到新的hash Q
return bh;
}
bh->b_dev=dev;
bh->b_blocknr=block;
insert_into_queues(bh); //将该buffer放到新的hash Q
return bh;
}
使用完buffer之后,必然要归还该buffer:
void brelse(struct buffer header * 要释放的buffer)
{
唤醒所有在等待任意buffer的进程;
唤醒所有在等待该buffer的进程;
禁用中断;
if (buffer内容有效且buffer是新的)
{
将该buffer放到free list尾部;
}
else
{
将该buffer放到free list队首;
}
将该buffer设置为空闲;
开启中断;
}
不多阐述了,下面是Linux 0.99.15的实现:
void brelse(struct buffer_head * buf)
{
if (!buf)
return;
wait_on_buffer(buf); //等待所有共享该buffer的进程释放
if (buf->b_count) {
if (--buf->b_count)
return;
wake_up(&buffer_wait); //唤醒所有等待的进程
return;
}
printk("VFS: brelse: Trying to free free buffer\n");
}
用OO方法建模
{
if (!buf)
return;
wait_on_buffer(buf); //等待所有共享该buffer的进程释放
if (buf->b_count) {
if (--buf->b_count)
return;
wake_up(&buffer_wait); //唤醒所有等待的进程
return;
}
printk("VFS: brelse: Trying to free free buffer\n");
}
用OO方法建模
从OO观点来看buffer的模型——使用hash Q和free list来管理该buffer池——buffer header更像是使用了继承,继承了hash Q和free list的操作,因为buffer header中,指向hash Q元素和free list元素的指针并不是buffer header的属性,因此完全可以将他们分离出来:
因为采用继承的方式,我们对于数据结构的使用就固定为hash Q和free list,不利于修改为其他的数据结构。这样的话也向内核其他部分暴露了缓冲池的内部实现。而使用模板的方式,不但便于修改,而且还可以利用其他的数据结构来实现缓冲模型。对于使用buffer cache的模块来说,只要保留有该数据结构的引用或指针即可。
从图中可以很容易得到继承方式的C++代码,此处大致列出模板的C++代码:
template <class T>
class DLinkedList
{
public:
T * Append(const T * newNode);
T * Insert(const T * newNode);
T * Allocate();
private:
T * elem;
T * pre;
T * next;
};
template <class TElem, class TKey>
class HashQ
{
public:
boolean Enqueue(const TElem * newNode, const TKey * aKey);
TElem * Search(const TKey * aKey);
private:
DLinkedList<TElem> * header[4];
};
可以封装一个buffer cache类:
class BufferCache // Singleton
{
public:
BufferHeader * GetBlock();
BufferHeader * ReleaseBlock();
static BufferCache * GetBufferCache(BufferHeader * pBuf);
private:
BufferCache();
static BufferHeader * pool;
static HashQ<BufferHeader, int> * pHashQ;
static DLinkedList<BufferHeader> * pFreeList;
static Lock * aLock;
statci Interrupt * aIntr;
};
BufferCache也可以定义为一个模板类。
可以执行如下语句来初始化(非构造函数):
BufferHeader * pool = new BufferHeader[n];
HashQ<BufferHeader> * pHashQ = new HashQ<BufferHeader, int>;
DLinkedList<BufferHeader> * pFreeList = new DLinkedList<BufferHeader>;
for (int i = 0; i < n; ++i )
pFreeList->Append(pool +i); // 初始化时所有元素全部在free list上
使用BufferCache来分配/回收buffer:
BufferCache * pBufCache = BufferCache.GetBufferCache();
……
BufferHeader * pBuf = pBufCache.GetBlock();
……
pBufCache.ReleaseBlock(pBuf);
类似的内存/缓冲管理对于应用程序的开发也具有指导意义,因此,研究buffer cache,并在开发应用程序时使用类似的技术,将会得到更加灵活、稳定、健壮的程序。
个人肤浅的理解,且未研究更多的细节,如有偏差,请高手指正!
题外话:对于hash Q和Free List,可以在内部封装iterator用于遍历,当然,可以作为private方法(这两个类的可复用程度将降低),也可以作为public的方法来提高这两个类的可复用程度)
题外话:对于hash Q和Free List,可以在内部封装iterator用于遍历,当然,可以作为private方法(这两个类的可复用程度将降低),也可以作为public的方法来提高这两个类的可复用程度)
参考:
The Design of The UNIX Operation System, by Maurice J. Bach
Linux Kernel Source Code v0.99.15, by Linus Torvalds
Linux Kernel Source Code v2.6.22, by Linux Torvalds and Linux community.
The C++ Programming Language, 3rd, by Bjarne Stroustup
Design Patterns, by GOF
Copyleft (C) raof01.
本文可以用于除商业外的所有用途。此处“用途”包括(但不限于)拷贝/翻译(部分或全部),不包括根据本文描述来产生代码及思想。若用于非商业,请保留此权利声明,并标明文章原始地址和作者信息;若要用于商业,请与作者联系(raof01@gmail.com),否则作者将使用法律来保证权利。
本文可以用于除商业外的所有用途。此处“用途”包括(但不限于)拷贝/翻译(部分或全部),不包括根据本文描述来产生代码及思想。若用于非商业,请保留此权利声明,并标明文章原始地址和作者信息;若要用于商业,请与作者联系(raof01@gmail.com),否则作者将使用法律来保证权利。














 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}