






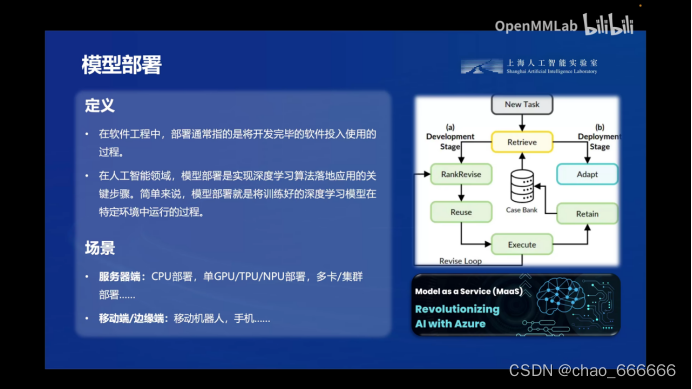
模型部署
模型部署对于任何大模型来说是非常关键的一步。一旦模型经过训练并达到预期的性能指标,就需要将其部署到实际的生产环境中,为最终用户提供服务。但是在部署过程中,大型模型会面临一些独特的挑战。
面临的挑战
大模型在部署方面有一个难题,就是大模型的“大”,导致在很多设备环境很难部署,包括:
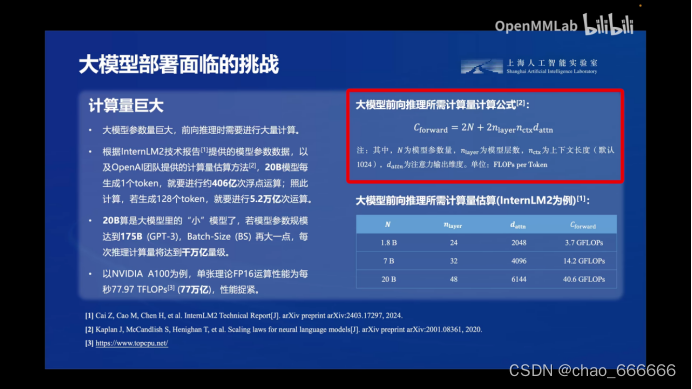
- 1.计算量巨大
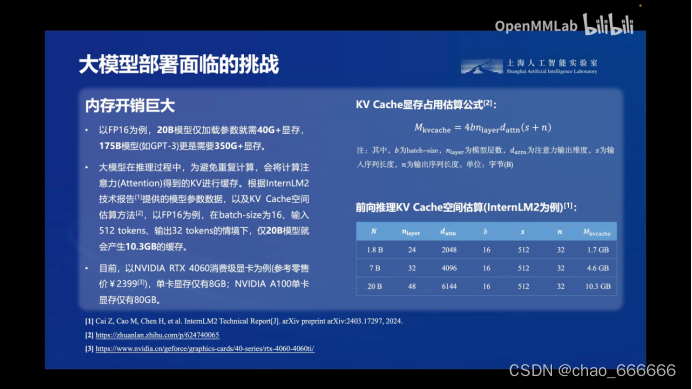
- 2.内存开销大
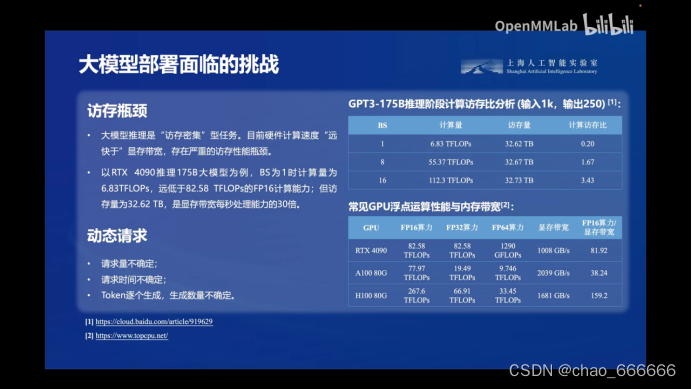
- 3.访存瓶颈
这些问题使得在许多设备和环境中部署大型模型变得非常困难,甚至根本无法实现。因此,如何有效地解决这些挑战,成为了大模型部署中必须解决的关键问题。
部署问题的解决方案
为了应对上述挑战,研究人员和工程师提出了多种解决方案,包括知识蒸馏、模型剪枝和量化等技术。
知识蒸馏的思路是利用大型教师模型来指导小型学生模型的训练,使学生模型能够学习到教师模型的知识,从而在保持较好性能的同时大幅减小模型的规模。
模型剪枝则是通过剔除模型中不重要的参数和计算,来缩小模型的尺寸。
量化技术则是将原始的32位或16位浮点数参数压缩为8位或更低位宽的定点数表示,从而降低模型的内存占用和计算量。



量化模型LMDeploy
最关键的就是高效的推理能力。具体来说,包括以下几个方面:
- 高效的推理技术,如Continuous Batch、Blocked K/V Cache等,能够极大提高推理的速度和吞吐量。
- 内存优化,如通过IntermediateFileCache(LMDeploy)技术,大幅减少内存占用,支持在低配GPU(16GB/24GB)上高效部署大模型。
- 支持多种量化类型,如支持Attention的量化,以平衡推理速度和精度。
- 良好的工程能力,如端到端的部署流程、高效的并行计算等,提高了部署效率。

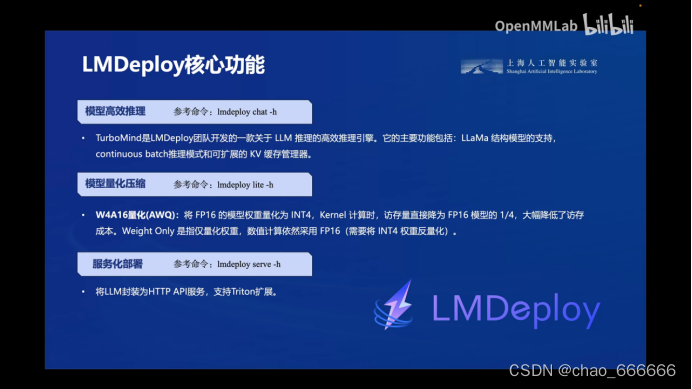
最后可以看到LMDeploy在性能的表现上非常优秀,速度提升明显。
部署LMDeploy并对话
配置LMDeploy运行环境
安装好环境,并成功激活

使用transformer运行大模型

使用LMDeploy模型量化(lite)
KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
使用KV8量化
设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例
上下进行对比,第一个设置为0.8,第二个设置为0.5,发现有明显的显存占用降低


使用W4A16量化
进行量化工作,保存新的HF模型。
KV Cache比例再次调为0.4,进行对话

可以发现推理生成的速度很快

LMDeploy服务(serve)
1 启动API服务器

2 命令行客户端连接API服务器
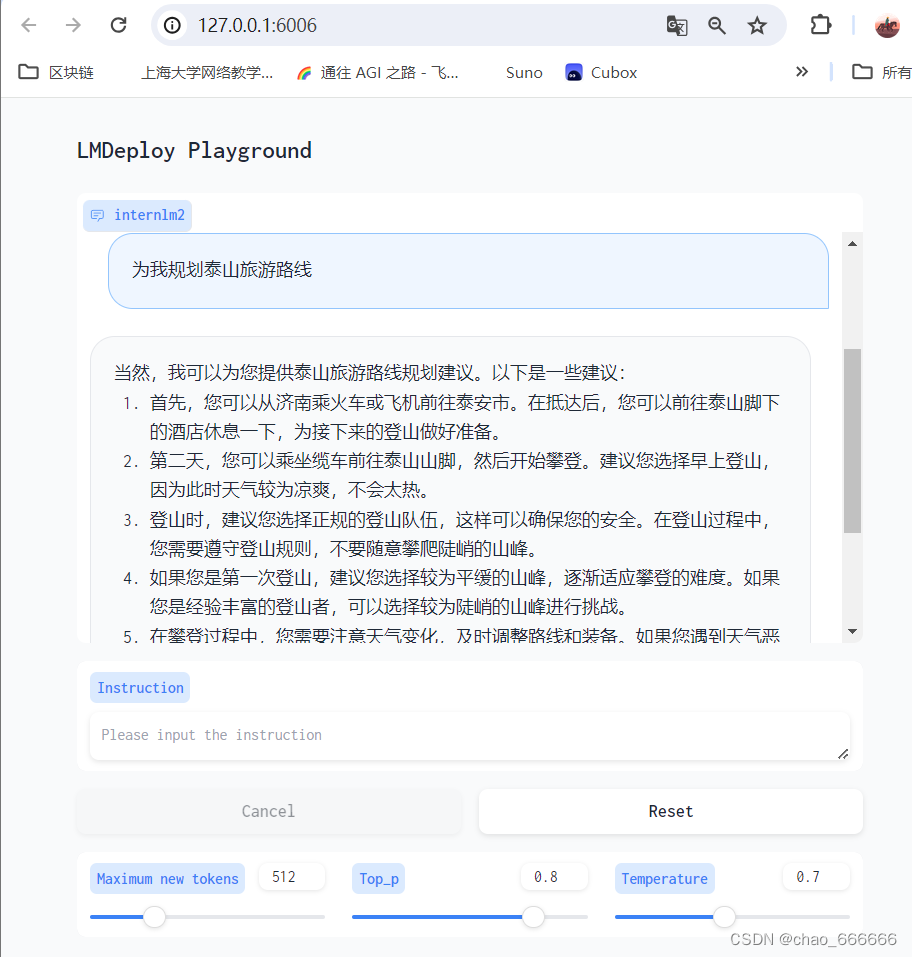
3 网页客户端连接API服务器















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









