







内容来源:https://mp.weixin.qq.com/s/9KishIDAr1NLLtTcXDvEHQ
设计模式
1.单例模式
某一个类在系统中只需要有一个实例对象,而且对象是由这个类自行实例化并提供给系统其它地方使用,这个类称为单例类。
1.1单例模式实现要点
单例模式虽然简单,但是要写出一个能保证在多线程环境下也能保证实例唯一性的单例确不是那么简单,实现一个正确的单例模式有以下几个要点:
- 某个类只能有一个实例,即使是多线程运行环境下;
- 单例类的实例一定是单例类自身创建,而不是在单例类外部用其它方式如new方式创建;
- 单例类需要提供一个方法向整个系统提供这个实例对象。
1.2单例两种模式
单例模式分为饿汉模式和懒汉模式,这两种模式很好理解,懒汉模式的意思就是这个类很懒,只要别人不找它要实例,它都懒得创建。饿汉模式在初始化时,我们就创建了唯一的实例,即便这个实例后面并不会被使用。
1.3懒汉式
下面这种写法的单例是大家最简单最容易写出的一种单例写法,只适用于单线程的系统,也就是说它不是线程安全的。
//懒汉式,线程不安全
class Singleton1{
private static Singleton1 instance;
//构造函数定义为私有,防止外部创建实例
private Singleton1(){
}
//系统使用单例的入口
public static Singleton1 getInstance(){
if (null == instance){
instance = new Singleton1();
}
return instance;
}
}
针对线程不安全的问题,可以通过获取实例的方法添加了synchronized来解决,如下:
//懒汉式,线程安全,效率低
class Singleton2{
private static Singleton2 instance;
//构造函数定义为私有,防止外部创建实例
private Singleton2(){
}
//系统使用单例的入口
public static synchronized Singleton2 getInstance(){
if (null == instance){
instance = new Singleton2();
}
return instance;
}
}
这样一来,确实线程安全了,但是又带来了另一个问题:程序的性能极大的降低了,高并发下多个线程去获取这个实例,现在却要排队。
针对性能问题,有同学想到了减小synchronized的粒度,不加在方法上,而是放在代码块中:
//懒汉式,线程不安全
class Singleton3{
private static Singleton3 instance;
//构造函数定义为私有,防止外部创建实例
private Singleton3(){
}
//系统使用单例的入口
public static Singleton3 getInstance(){
if (null == instance){
synchronized(Singleton3.class) {
instance = new Singleton3();
}
}
return instance;
}
}
但是,很不幸,如果改成这样,又变得线程不安全了,我们试着分析一个代码执行的场景:假设我们有两个线程 T1与T2并发访问getInstance方法。当T1执行完if (instance == null)且instance为null时,其CUP执行时间被T2抢占,所以T1还没有创建实例。T2也执行if (instance == null),此时instance肯定还为null,T2执行创建实例的代码,当T1再次获得CPU执行时间后,其从synchronized 处恢复,又会创建一个实例。
那么有没有一种写法,可以同时兼顾到效率和线程安全两方面了,还真有,就是我们下面将要介绍的double-check的方式。
懒汉式,线程安全,效率还可以
class Singleton4{
//注意加上volatile关键字
private static volatile Singleton4 instance;
//构造函数定义为私有,防止外部创建实例
private Singleton4(){
}
//系统使用单例的入口
public static Singleton4 getInstance(){
//第一次检查提高访问性能
if (null == instance){
synchronized(Singleton4.class) {
//第二次检查为了线程安全
if(instance ==null) {
instance = new Singleton4();
}
}
}
return instance;
}
}
这种单例的写法做了两次 if (null == instance)的判断,因此被称为double-check的方式。
- 第一次check为了提高访问性能。因为一旦实例被创建,后面线程的所有的check都为假,不需要执行synchronized竞争锁了。
- 第二次check是为了线程安全,确保多线程环境下只生成一个实例。
需要注意的是,这种方式,在定义实例时一定需要加上volatile 关键字,禁止虚拟机指令重排,否则,还是有一定几率会生成多个实例,关于volatile 关键字和指令重排的问题这里不过多介绍,后面在多线程安全系列文章中再详细介绍。
1.4饿汉式
使用静态常量在类加载时候就创建了实例,属于饿汉模式。其是线程安全的,这一点由JVM来保证。
//饿汉式,线程安全
class Singleton5{
//
private static final Singleton5 INSTANCE = new Singleton5();
//构造函数定义为私有,防止外部创建实例
private Singleton5(){
}
//系统使用单例的入口
public static Singleton5 getInstance(){
return INSTANCE;
}
}
2.简单工厂模式介绍
2.1概述
工厂模式是一种常见的创建型模式,即讨论的是如何创建一个类的对象的问题。也许你会说,创建一个对象还不简单哈,用new不就可以了吗,好吧,你说的没错,但是如果你能够用一种高逼格的方式将对象创建出来,是不是会让你的leader刮目相看了?掌握了工厂模式就可以让你做到这一点。
工厂模式(Factory Design Pattern)一共分为三种:简单工厂模式、工厂方法和抽象工厂。今天我们来介绍其中最简单的简单工厂模式。
2.2使用场景
学习一种设计模式,我觉得最重要的一点之一就是你需要充分理解每种设计模式的使用场景。
当你想创建一个对象的时候,如果出现了以下几种情况,那么可以考虑是不是该用工厂模式了:
- 不想直接new这个类的对象,防止这个类改变的时候在new的地方到处去改,麻烦且容易遗漏;
- 这个类的对象构建过程非常复杂,不想在代码的各个地方将这么复杂的构建过程反复书写;
- 这个类的对象在构建过程中依赖了很多其他的类,而你无法在调用的地方提供。
2.3UML类图
业务场景:小明是个运动鞋大亨,他承包了耐克和阿迪达斯两个品牌的运动鞋的生产,我们如何用代码实现这个业务呢?
下面是简单工厂模式的UML图:
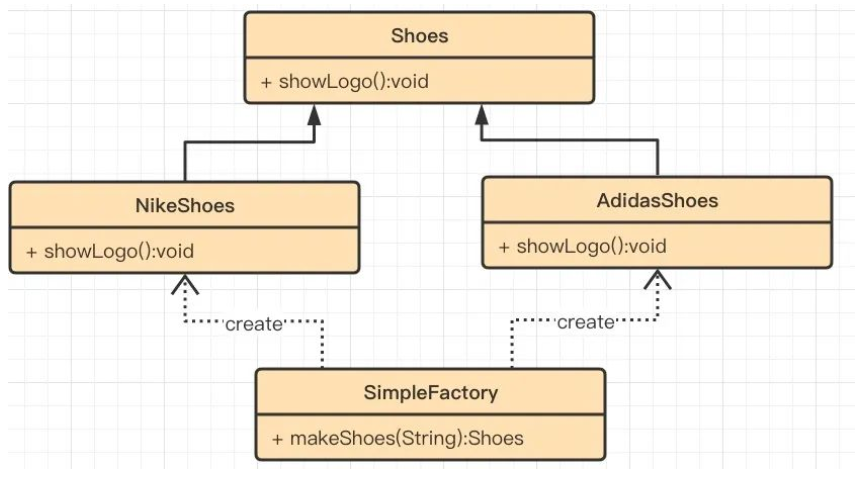
2.4简单工厂模式实现
以上面的业务场景为例,可以按照下面的方式写出对应的简单工厂模式的代码。
//1.定义鞋这种产品的抽象基类
abstract class Shoes{
public abstract void showLogo();
}
//2.定义具体品牌的鞋类,继承鞋抽象基类
class NikeShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是耐克鞋子");
}
}
//2.定义具体品牌的鞋类,继承鞋抽象基类
class AdidasShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是阿迪鞋子");
}
}
//3.定义简单工厂方法类,使用一个静态工厂方法来根据不同的品牌条件来产生不同品牌的鞋
class SimpleFactory {
public static Shoes makeShoes(String brand){
Shoes shoes = null;
switch (brand){
case "nike":
shoes = new NikeShoes();
break;
case "adidas":
shoes = new AdidasShoes();
break;
default:
System.out.println("错误的品牌");
}
return shoes;
}
}
//使用简单工厂模式
public class SimpleFactoryExample{
public static void main(String[] args) {
//使用工厂模式创建耐克品牌的鞋子
Shoes nikeShoes = SimpleFactory.makeShoes("nike");
nikeShoes.showLogo();
//使用工厂模式创建阿迪品牌的鞋子
Shoes adidasShoes = SimpleFactory.makeShoes("adidas");
adidasShoes.showLogo();
}
}
******************【运行结果】******************
我是耐克鞋子
我是阿迪鞋子
可以看出,简单工厂模式的出现,使得我们通过传入不同的参数类型就可以创建不同类型的对象实例,将对象的构建过程完全交给了简单工厂方法类SimpleFactory。
2.5简单工厂模式的特点
简单工厂模式的缺点用一句话介绍就是:违反了开闭原则,(对扩展开放,对修改关闭),破坏其内聚性,给维护带来额外开支。这句话怎么理解了?我们还是举个例子吧。
还是上面这个业务场景,假设现在小明的生意越做越大了,又拓展了安踏这个品牌,那么针对新增加的品牌,需要做如下改动:
//改动1:新增加安踏品牌,需要新增加有一个安踏鞋类继承抽象基类
class AntaShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是安踏鞋子");
}
}
//改动2:工厂方法类中方法增加一个创建安踏鞋子的分支
class SimpleFactory {
public static Shoes makeShoes(String brand){
Shoes shoes = null;
switch (brand){
case "nike":
shoes = new NikeShoes();
break;
case "adidas":
shoes = new AdidasShoes();
break;
case "anta":
shoes = new AntaShoes();
break;
default:
System.out.println("错误的品牌");
}
return shoes;
}
}
可以看到,每当我们增加一种产品的时候就要去修改工厂方法。而不是扩展,这就是所谓的违反了开闭原则。为了克服简单工厂模式的缺点,工厂方法模式就被提了出来,我们下篇文章再介绍。
3.工厂方法模式介绍
3.1使用场景
前面的文章说过学习设计模式最重要的一点之一就是需要充分理解每种设计模式的使用场景。所以即使前面已经介绍了工厂模式的使用场景,重要的话现在重复第二遍。
当你想创建一个对象的时候,如果出现了以下几种情况,那么可以考虑是不是该用工厂模式了:
- 不想直接new这个类的对象,防止这个类改变的时候在new的地方到处去改,麻烦且容易遗漏;
- 这个类的对象构建过程非常复杂,不想在代码的各个地方将这么复杂的构建过程反复书写;
- 这个类的对象在构建过程中依赖了很多其他的类,而你无法在调用的地方提供。
3.2UML类图
业务场景:小明是个运动鞋大亨,他承包了耐克和阿迪达斯两个品牌的运动鞋的生产,我们如何用代码实现这个业务呢?
在前面,我们用简单工厂模式实现了这一业务,但是同时也指出了简单工厂模式的缺陷:违反了开闭原则。本文介绍的工厂方法模式就是为了解决这一缺陷而提出的。
在工厂方法模式中,不再是用简单工厂方法模式中那个静态工厂方法,取而代之的是为每一种要生产的产品配备一个工厂,就是说每个工厂只生产一种特定的产品。这样做的好处就是当以后需要增加新的产品时,直接新增加一个对应的工厂就可以了,而不是去修改原有的工厂。
下面是工厂方法模式的UML图:
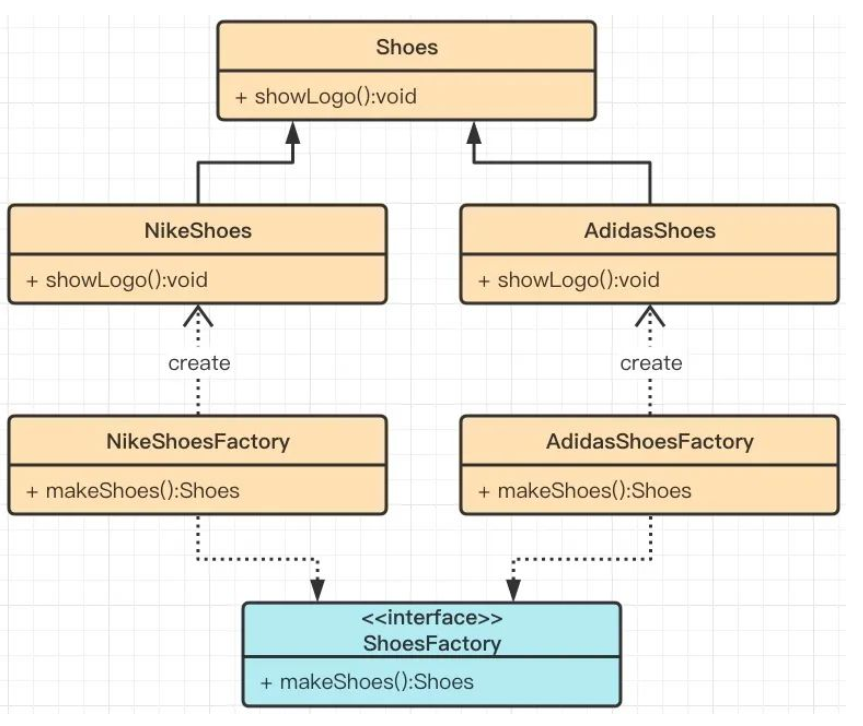
3.3工厂方法模式实现
以上面的业务场景为例,可以按照下面的方式写出对应的工厂方法模式的代码。
//1.定义鞋这种产品的抽象基类
abstract class Shoes{
public abstract void showLogo();
}
//2.定义具体品牌的鞋类,继承鞋抽象基类
class NikeShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是耐克鞋子");
}
}
//2.定义具体品牌的鞋类,继承鞋抽象基类
class AdidasShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是阿迪鞋子");
}
}
//3.定义工厂类接口
interface ShoesFactory {
public abstract Shoes makeShoes();
}
//4.定义生产具体产品工厂类,如生成耐克鞋的工厂
class NikeShoesFactory implements ShoesFactory{
@Override
public Shoes makeShoes() {
return new NikeShoes();
}
}
//4.定义实现具体产品工厂类,如生成阿迪鞋的工厂
class AdidasShoesFactory implements ShoesFactory{
@Override
public Shoes makeShoes() {
return new AdidasShoes();
}
}
//工厂方法模式
public class FactoryMethodExample {
public static void main(String[] args) {
NikeShoesFactory nikeShoesFactory = new NikeShoesFactory();
nikeShoesFactory.makeShoes().showLogo();
AdidasShoesFactory adidasShoesFactory = new AdidasShoesFactory();
adidasShoesFactory.makeShoes().showLogo();
}
}
******************【运行结果】******************
我是耐克鞋子
我是阿迪鞋子
可以看出,和简单工厂模式相比,工厂方法模式工厂类代替了简单工厂模式中的静态方法,现在如果小明的生意越做越大,又拓展了安踏这个品牌,看看是如何修改的。
//改动1:新增加安踏品牌,需要新增加有一个安踏鞋类继承抽象基类
class AntaShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是安踏鞋子");
}
}
//改动2.新增一个生产安踏鞋的工厂类,其实现了抽象工厂基类
class AntaShoesFactory implements ShoesFactory{
@Override
public Shoes makeShoes() {
return new AntaShoes();
}
}
可以看到,通过工厂方法模式,现在增加一种产品的时候就只要扩展出两个类就可以了,这就符合了开闭原则。也就是说解决了简单工厂模式的存在的问题。
3.4简单工厂模式的缺点
但工厂方法模式也不是完美的解决方案,它也有自己的不足,就是每增加一种产品就要相应的增加一个工厂类,比较繁琐,这点通过上面的例子也可以看出。
4抽象工厂模式
4.1UML类图
业务场景:小明是个运动鞋大亨,他承包了耐克和阿迪达斯两个品牌的运动鞋的生产,随着资本的积累,他准备将耐克和阿迪两个品牌的衣服也一起生产,我们如何用代码实现这个业务呢?
如果继续用前面介绍的工厂方法模式,如果品牌数和每个品牌对应的产品种类都很多的情况下,会造成类巨多的场面,过多的类会让系统的维护成本大幅增加。今天要介绍的抽象工厂模式能一定程度上改善这种局面。
下面是抽象工厂模式的UML图:
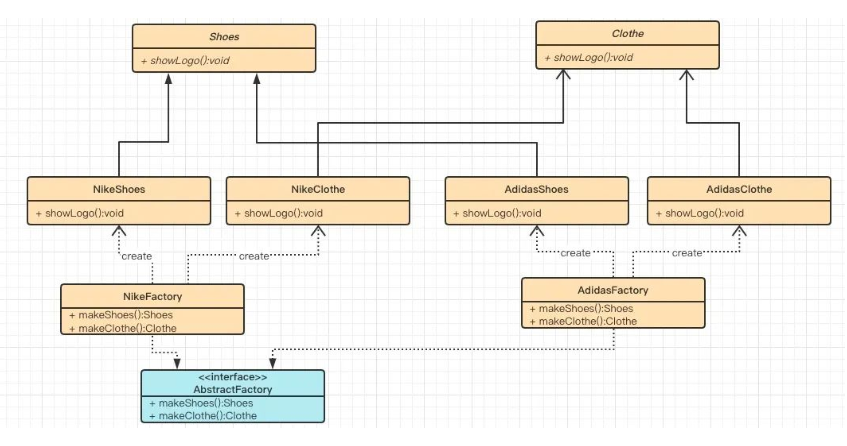
4.2抽象工厂模式
以上面的业务场景为例,可以按照下面的方式写出对应的抽象工厂模式的代码。
//1.1 定义鞋的抽象类
abstract class Shoes{
public abstract void showLogo();
}
//1.2 定义衣服的抽象类
abstract class Clothe{
public abstract void showLogo();
}
//2.1 定义耐克具体品牌的鞋类,继承鞋抽象基类
class NikeShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是耐克鞋子");
}
}
//2.2 定义阿迪具体品牌的鞋类,继承鞋抽象基类
class AdidasShoes extends Shoes{
@Override
public void showLogo() {
System.out.println("我是阿迪鞋子");
}
}
//2.3 定义耐克具体品牌的衣服类,继承衣服抽象基类
class NikeClothe extends Clothe{
@Override
public void showLogo() {
System.out.println("我是耐克衣服");
}
}
//2.4 定义阿迪具体品牌的衣服类,继承衣服抽象基类
class AdidasClothe extends Clothe{
@Override
public void showLogo() {
System.out.println("我是阿迪衣服");
}
}
//3.定义抽象工厂接口
interface AbstractFactory {
Shoes makeShoes();
Clothe makeClothe();
}
//4.1 定义生产耐克产品的的具体工厂类,这里的工厂类以品牌来定义
class NikeFactory implements AbstractFactory{
@Override
public Shoes makeShoes() {
return new NikeShoes();
}
@Override
public Clothe makeClothe() {
return new NikeClothe();
}
}
//4.2 定义生产阿迪产品的的具体工厂类,这里的工厂类以品牌来定义
class AdidasFactory implements AbstractFactory{
@Override
public Shoes makeShoes() {
return new AdidasShoes();
}
@Override
public Clothe makeClothe() {
return new AdidasClothe();
}
}
public class AbstractFactoryExample {
public static void main(String[] args) {
//使用耐克工厂生产耐克的衣服和鞋
NikeFactory nikeFactory = new NikeFactory();
nikeFactory.makeShoes().showLogo();
nikeFactory.makeClothe().showLogo();
System.out.println("");
AdidasFactory adidasFactory = new AdidasFactory();
adidasFactory.makeShoes().showLogo();
adidasFactory.makeClothe().showLogo();
}
}
******************【运行结果】******************
我是耐克鞋子
我是耐克衣服
我是阿迪鞋子
我是阿迪衣服
理解抽象工厂模式的核心关键在于理解品牌家族的概念,简单工厂方法与工厂方法创建工厂的着眼点为某类具体的产品,某个工厂与某个产品对应,而抽象工厂某个工厂与产品的家族对应,这个工厂可以生产这个品牌家族的一系列产品。
5.建造者模式
5.1概述
在我们工作中常常会出现建造者模式的身影,它是一种比较常用的创建型设计模式。建造者模式的原理和代码实现非常简单,掌握起来并不难。
5.2使用场景
当一个类的构造函数参数有多个,而且这些参数有些是可选的参数,就可以考虑使用建造者模式了。
还是看一个场景,我们现在有如下一个雇员类:
class Employee{
private String name; //名字,必须
private int age; //年龄,必须
private String sex; //性别,可选
private String country; //国家,可选
}
在实例化对象时其中name和age是必填参数,而sex和country是可选参数,那么我们如何构造这个类的实例呢,通常有两种方式:
1. 折叠构造函数模式
class Employee{
...........
..........
public Employee(String name, int age){
this(name, age, "男");
}
public Employee(String name, int age, String sex){
this(name, age, sex, "中国");
}
public Employee(String name, int age, String sex, String country){
this.name = name;
this.age = age;
this.sex = sex;
this.country = country;
}
}
通过这种方式,我们可以根据需要,选择不同形式的构造函数创建对象。
2. 属性设置模式:
class Employee{
...........
..........
public Employee(){
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public void setSex(String sex) {
this.sex = sex;
}
public void setCountry(String country) {
this.country = country;
}
}
//使用
public static void main(String[] args) {
Employee employee = new Employee();
employee.setName("宋江"); //还有属性 没有设置,对象还处于无效状态
employee.setAge(66); //还有属性 没有设置,对象还处于无效状态
employee.setSex("男"); //还有属性 没有设置,对象还处于无效状态
employee.setCountry("大宋"); //所有属性设置完成,对象可用了
System.out.println(employee);
}
******************【运行结果】******************
Employee{name='宋江', age=66, sex='男', country='大宋'}
两种方式都能创建出你想要的对象,但是两种方式都有其弊端:
- 第一种方式在构建对象调用构造函数时,你首先要决定使用哪一个构造函数,当可选参数很多的时候,你就要非常清楚这些参数的含义,否则很容易就传混了。
- 第二种方式在构建对象的过程中,对象的属性是分步设置的,会出现无效状态,容易出错。
正是因为前面两种方式都有其不足之处,所以就出现了建造者模式。
5.3建造者模式实现
以上面的业务场景为例,可以按照下面的方式写出对应的建造者模式的代码。
class Employee{
private String name;
private int age;
private String sex; //性别,可选
private String country; //国家,可选
//在Employee中创建一个private的构造函数,参数为Builder类型
private Employee(Builder builder){
this.name = builder.name;
this.age = builder.age;
this.sex = builder.sex;
this.country = builder.country;
}
//2.在Employee创建静态内部类Builder,将Employee的成员变量复制到Builder类中
public static class Builder{
private String name;
private int age;
private String sex; //性别,可选
private String country; //国家,可选
//3.在Builder中创建一个public的构造函数,参数为必填的那些参数,name 和age。
public Builder(String name, int age){
this.name = name;
this.age = age;
}
//4.在Builder中创建设置函数,对那些可选参数进行赋值,返回值为Builder类型的实例
public Builder setSex(String sex){
this.sex = sex;
return this;
}
public Builder setCountry(String country){
this.country = country;
return this;
}
//在Builder中创建一个build()方法,在其中构建Employee的实例并返回
public Employee build(){
return new Employee(this);
}
}
@Override
public String toString() {
return "Employee{" +
"name='" + name + '\'' +
", age=" + age +
", sex='" + sex + '\'' +
", country='" + country + '\'' +
'}';
}
}
public class BuilderExample {
public static void main(String[] args) {
//使用建造者模式将对象一步步创建出来
Employee employee = new Employee.Builder("李世民", 55)
.setSex("男")
.setCountry("唐朝")
.build();
System.out.println(employee);
}
}
******************【运行结果】******************
Employee{name='李世民', age=55, sex='男', country='唐朝'}
可用看出,建造者模式很好的解决了前面两种方式存在的问题,所以如果一个类的构造函数可选参数过多,我们就需要考虑使用建造者模式,先设置建造者的变量,然后再一次性地创建对象。
6.原型模式
6.1概述
原型模式顾名思义,就是基于原型来创建对象,用人话说就是一个对象的产生可以不由零起步,直接从一个已经具备一定雏形的对象克隆,然后再修改为所需要的对象。显而易见 ,原型模式属于创建型模式,
6.2使用场景
如果对象的创建成本比较大,例如某个对象里面的数据需要访问数据库才能拿到;并且同一个类的不同对象之间差别不大(大部分字段都相同),这种场景下可以考虑使用原型模式达到提高程序性能的作用。
我们可以通过一个业务场景来理解原型模式的应用,设计一个学生类,学生类主要的成员变量有名字name,班级classId, needExtraCourse,以及所学的课程 course,其中course需要通过rpc调用查询课程系统获取,这个耗时100ms。如果用普通的方式为该类创建同一个班的4个 对象,如下所示:
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
class Student{
private String name;
private Integer classId;
//是否需要额外多选课程
private Boolean needExtraCourse = false;
//所学课程,需要通过rpc调用查询课程系统,耗时100ms
private List<String> course = new ArrayList<>();
public Student(String name, Integer classId) throws InterruptedException {
this.name = name;
this.classId = classId;
//超时模拟rpc调用获取课程信息初始化course
Thread.sleep(100);
course.add("语文");
course.add("数学");
course.add("英语");
}
//getter、setter、toString函数省略
}
public class PrototypeExample {
public static void main(String[] args) throws InterruptedException {
long start = new Date().getTime();
Student student1 = new Student("张三", 1);
Student student2 = new Student("李四", 1);
Student student3 = new Student("王五", 1);
Student student4 = new Student("赵六", 1);
long end = new Date().getTime();
System.out.println("创建对象共花费了时间:" + (end -start) + " ms");
}
}
******************【运行结果】******************
创建对象共花费了时间:413 ms
只是创建了4个对象就花费了400多ms,这样成本也太大了,其实对于一个班级的学生,不考虑额外选修课程的情况下(needExtraCourse = false),所学的课程应该是完全一样的。
因此可以用到今天介绍的原型模式:先用普通的方式创建一个对象,然后从创建的对象中克隆出其它对象,再修改其它对象的name字段即可。
6.3UML类图
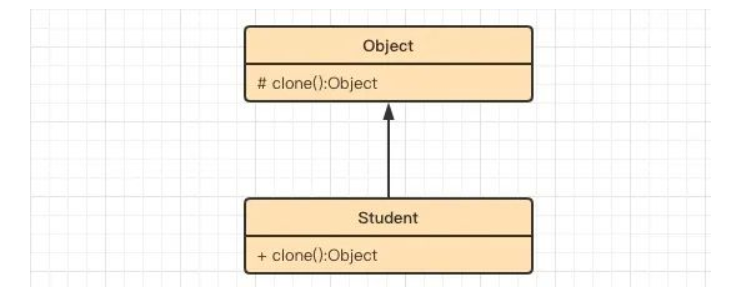
UML 类图也比较简单,只有两个部分:
- Cloneable接口
- Student类,实现了Cloneable接口的原型对象,这个对象有个能力就是可以克隆自己。
6.4原型模式实现
原型模式的实现方式有两种:浅拷贝和深拷贝。关于浅拷贝和深拷贝.
6.4.1浅拷贝模式
浅拷贝仅仅复制所考虑的对象,而不复制它所引用的对象。Object类提供的方法clone只是拷贝本对象 , 其对象内部的数组、引用对象等都不拷贝,还是指向原生对象的内部元素地址,下面是浅拷贝原型模式实现的代码:
//1原型类需实现Cloneable接口
class Student implements Cloneable{
//Student类的其余部分和上面例子一样
......................
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class PrototypeExample {
public static void main(String[] args) throws InterruptedException, CloneNotSupportedException {
long start = new Date().getTime();
Student student1 = new Student("张三", 1);
Student student2 = (Student) student1.clone();
student2.setName("李四");
Student student3 = (Student) student1.clone();
student3.setName("王五");
Student student4 = (Student) student1.clone();
student4.setName("赵六 ");
System.out.println("student1--->" + student1);
System.out.println("student2--->" + student2);
System.out.println("student3--->" + student3);
System.out.println("student4--->" + student4);
long end = new Date().getTime();
System.out.println("创建对象共花费了时间:" + (end -start) + " ms");
//赵六选修了课程美术
student4.setNeedExtraCourse(true);
student4.getCourse().add("美术 ");
System.out.println("\n赵六选修美术课后:");
System.out.println("student1--->" + student1);
System.out.println("student2--->" + student2);
System.out.println("student3--->" + student3);
System.out.println("student4--->" + student4);
}
}
******************【运行结果】******************
student1--->Student{name='张三', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student2--->Student{name='李四', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student3--->Student{name='王五', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student4--->Student{name='赵六 ', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
创建对象共花费了时间:130 ms
赵六选修美术课后:
student1--->Student{name='张三', classId=1, needExtraCourse=false, course=[语文, 数学, 英语, 美术 ]}
student2--->Student{name='李四', classId=1, needExtraCourse=false, course=[语文, 数学, 英语, 美术 ]}
student3--->Student{name='王五', classId=1, needExtraCourse=false, course=[语文, 数学, 英语, 美术 ]}
student4--->Student{name='赵六 ', classId=1, needExtraCourse=true, course=[语文, 数学, 英语, 美术 ]}
可以看到,通过原型模式的方式,同样是创建四个对象,只花了100多ms,大大的提高了程序性能。
但是这里还存在一个小问题:赵六比较好学,所以还选修了美术,但是通过程序的运行结果可以看到,明明只是赵六选修了美术,但是其他三个同学的课表中也都出现了美术课 。这是因为浅拷贝虽然产生了两个完全不同的对象,但是对象中有对其他对象的引用(如这里的List)都指向同一个对象。
为了解决这个问题,我们引入了深拷贝模式。
6.4.2深拷贝模式
深拷贝模式把要复制的对象所引用的对象都拷贝了一遍。
class Student implements Cloneable{
//Student类的其余部分和上面例子一样
......................
@Override
public Object clone() throws CloneNotSupportedException {
Object object = super.clone();
Student student = (Student)object;
List<String> newCourse = new ArrayList<>();
Iterator<String> it = student.course.iterator();
while (it.hasNext()) {
newCourse.add(it.next());
}
student.course = newCourse;
return object;
}
}
public class PrototypeExample {
public static void main(String[] args) throws InterruptedException, CloneNotSupportedException {
long start = new Date().getTime();
Student student1 = new Student("张三", 1);
Student student2 = (Student) student1.clone();
student2.setName("李四");
Student student3 = (Student) student1.clone();
student3.setName("王五");
Student student4 = (Student) student1.clone();
student4.setName("赵六 ");
System.out.println("student1--->" + student1);
System.out.println("student2--->" + student2);
System.out.println("student3--->" + student3);
System.out.println("student4--->" + student4);
long end = new Date().getTime();
System.out.println("创建对象共花费了时间:" + (end -start) + " ms");
//赵六选修了课程美术
student4.setNeedExtraCourse(true);
student4.getCourse().add("美术 ");
System.out.println("\n赵六选修美术课后:");
System.out.println("student1--->" + student1);
System.out.println("student2--->" + student2);
System.out.println("student3--->" + student3);
System.out.println("student4--->" + student4);
}
}
******************【运行结果】******************
student1--->Student{name='张三', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student2--->Student{name='李四', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student3--->Student{name='王五', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student4--->Student{name='赵六 ', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
创建对象共花费了时间:135 ms
赵六选修美术课后:
student1--->Student{name='张三', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student2--->Student{name='李四', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student3--->Student{name='王五', classId=1, needExtraCourse=false, course=[语文, 数学, 英语]}
student4--->Student{name='赵六 ', classId=1, needExtraCourse=true, course=[语文, 数学, 英语, 美术 ]}
可以看到,深拷贝模式 ,修改一个对象的引用类型的成员不会再影响另外对象的该成员了。
7.秒懂责任链模式
7.1概述
责任链模式是一种行为型模式。责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求。
上面对于责任链模式的定义不理解没关系,其实每一种设计模式的定义对于初学者来说都比较晦涩难懂,因为字都认识却无法理解其中的含义。必须等学完了,回过头来看才能更加深刻的理解其含义。
7.2使用场景
设计模式的使用场景才是目前我们关注的重点之一。
小二哥是BAT某个公司的一个资深码农,他的媳妇还有1个星期预产期到了,小二哥想请半个月假期去陪媳妇,但是在小二哥公司,对于假期的批准,不同级别的领导权限是不一样的,比如3天以下的假期,小二哥的直属组长就能批了,对于一个星期的假期,需要走到总监这一层批准。半个月的 假期则需要走到总经理这个级别了。
小二哥请假的情况就非常适合使用责任链模式。事先不知道会由哪层领导批复假期,而各层领导的审批职责就好像铁链一样连接在一起,一个请求沿着这条链一直往上传。
看到这里, 如果还是很模糊,也没关系,talk is cheap show you the code, 后面我们会用代码实现这个场景.
7.3UML图
责任链模式的UML类图如下:
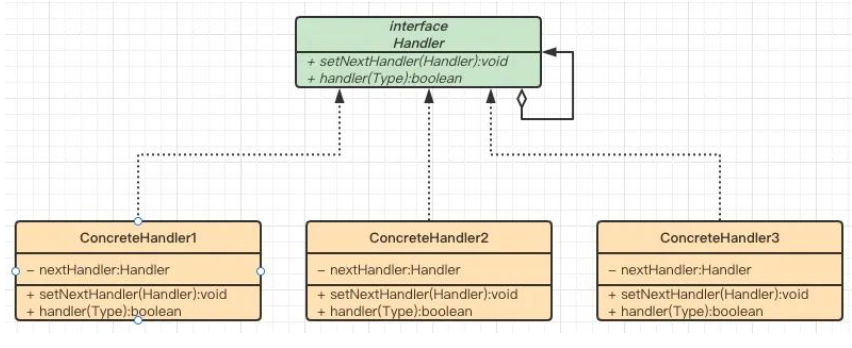
UML 类图也比较简单,只有两个部分:
- Handler接口:处理请求的接口。接口中有两个抽象方法,setNextHandler方法用来设置对下个层级的引用;handler方法用以处理具体请求。
- ConcreteHandler类:具体处理者接到请求后,可以选择将请求处理掉,或者将请求传给下个层级。由于具体处理者持有对下个层级的引用,因此,如果需要,具体处理者可以访问下家。根据实际场景,ConcreteHandler类可以有多个,如上面场景中需要构造组长,总监,总经理的ConcreteHandler类。
7.4责任链模式实现
下面是根据上面的场景用责任链模式实现的代码:
//1.定义一个所有层级请假处理器都需要实现的接口
interface AskForLeaveHander{
void setNextHandler(AskForLeaveHander nextHandler);
boolean handler(int days);
}
//2.1 组长批复ConcreteHandler类
class HeadmanHander implements AskForLeaveHander{
private AskForLeaveHander nextHandler;
@Override
public void setNextHandler(AskForLeaveHander nextHandler) {
this.nextHandler = nextHandler;
}
@Override
public boolean handler(int days) {
if (days <= 3){
System.out.println("组长成功批复了!");
return true;
}
System.out.println(String.format("%d 天假期超出组长权限,请总监批复",days));
return nextHandler.handler(days);
}
}
//2.2 总监批复ConcreteHandler类
class ChiefHander implements AskForLeaveHander{
private AskForLeaveHander nextHandler;
@Override
public void setNextHandler(AskForLeaveHander nextHandler) {
this.nextHandler = nextHandler;
}
@Override
public boolean handler(int days) {
if (days <= 7){
System.out.println("总监成功批复了!");
return true;
}
System.out.println(String.format("%d 天假期超出总监权限,请总经理批复", days));
return nextHandler.handler(days);
}
}
//2.3 总经理批复ConcreteHandler类
class GmHander implements AskForLeaveHander{
private AskForLeaveHander nextHandler;
@Override
public void setNextHandler(AskForLeaveHander nextHandler) {
this.nextHandler = nextHandler;
}
@Override
public boolean handler(int days) {
if (days <= 60){
System.out.println("总经理成功批复了!");
return true;
}
System.out.println("单次最多只能请60天假!");
return false;
}
}
public class ResponsibilityExample {
public static void main(String[] args) {
HeadmanHander headmanHander = new HeadmanHander();
ChiefHander chiefHander = new ChiefHander();
GmHander gmHander = new GmHander();
headmanHander.setNextHandler(chiefHander);
chiefHander.setNextHandler(gmHander);
System.out.println("小二哥申请15天假期\n");
if (headmanHander.handler(15)){
System.out.println("\n您申请的假期已被批准");
}else{
System.out.println("\n最近项目太忙了,暂不批假");
}
}
}
******************【运行结果】******************
小二哥申请15天假期
15 天假期超出组长权限,请总监批复
15 天假期超出总监权限,请总经理批复
总经理成功批复了!
您申请的假期已被批准
小二哥只能向自己的直接上级组长申请假期的批准,所以入口肯定是headmanHander.handler(15),至于谁最终会批准这个请假申请,则是根据请假的天数days决定。
如果本级别没有权限批准, 则需要提交到下一层级处理器继续处理,所以需要在每个级别的Handler中使用setNextHandler方法指定下一个Handler,由于总经理是最后一个处理器,所以我们就不设置Handler。通过运行结果可以看出,小二哥的请假被总经理批准了。
7.5责任链模式要点
责任链模式的实现,需要我们注意以下几点:
- Handler 接口持有它自己的类型,通过set方法或者构造函数将责任链上的下一个处理器赋值进去;
- 客户端(使用责任链模式的代码)负责将各个处理器连成链,而且必然知道链上的第一个处理器,通过调用它的handle方法触发处理流程;
- 千万不能将最后一个处理的下一个handler设置为第一个,这样程序可能就无法结束了。
8.策略模式介绍
8.1概述
策略模式可以说算一种既简单又常用的设计模式了,因此需要我们好好的掌握它为我们所用。
同样先来策略模式的定义:策略模式定义了一系列算法,并将每个算法封装起来,让它们之间可以互相替换,让算法的变化独立于使用算法的客户。
好吧,这里还是不过多的纠结其定义,等到我们自己实现一遍之后自然会理解的。
8.2使用场景
如果你在写代码的时候发现一个操作有多种实现方法,需要根据不同的情况使用if-else结构来确定实现方式的时候,想一想是否可以用本文介绍的策略模式。
举个例子,作为21世纪的宅男宅女们,相信都用过美团吧,假如某个入驻美团的商家为了促销,设置多种会员优惠,包含超级会员7折、普通会员9折和普通用户没有折扣三种。用户在付款的时候,根据用户的会员等级,就可以知道用户符合哪种折扣策略,进而计算出实付金额。
在这个例子中,计算实付金额这个操作需要根据用户等级来确定实现方式,因此非常适合用策略模式实现。
8.3UML类图
以上面的场景为例,策略模式的UML类图如下:
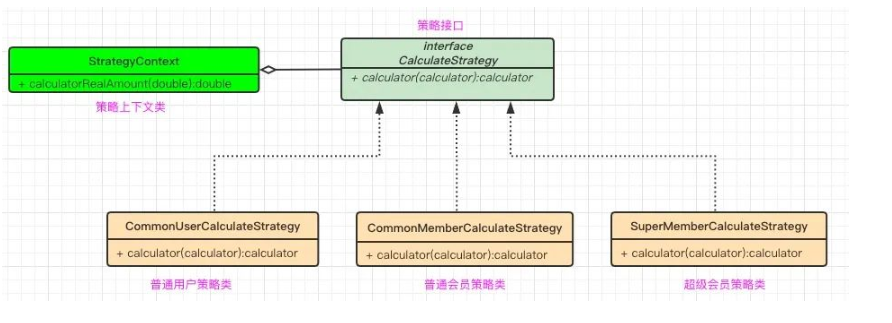
UML 类图也不复杂,只有三个部分:
- 策略接口CalculateStrategy:该接口定义了计算价格的抽象方法,由具体的策略实现类去实现该抽象方法;
- 多个具体策略类:针对不同的会员,定义三种具体的策略类,每个类中都分别实现计算价格方法;
- 策略上下文类StrategyContext:该类是集成各种实现算法的类。
8.4策略模式实现
普通实现
我们先来看看不使用策略模式实现的代码:
enum Grade{
COMMON_USER, //普通用户
COMMON_MEMBER, //普通会员
SUPER_MEMBER //超级会员
}
class CalculatorRealAmount{
public double calculator(double price, Grade grade){
double realAmount = 0.0;
if (grade == Grade.COMMON_USER){
realAmount = price;
}else if(grade == Grade.COMMON_MEMBER){
realAmount = price * 0.9;
}else if (grade == Grade.SUPER_MEMBER){
realAmount = price * 0.7;
}else{
System.out.println("不支持的会员等级");
}
return realAmount;
}
}
public class NonStrategyPatternExample {
public static void main(String[] args) {
CalculatorRealAmount calculatorRealAmount = new CalculatorRealAmount();
System.out.println(calculatorRealAmount.calculator(100, Grade.COMMON_USER));
System.out.println(calculatorRealAmount.calculator(100, Grade.COMMON_MEMBER));
System.out.println(calculatorRealAmount.calculator(100, Grade.SUPER_MEMBER));
}
}
******************【运行结果】******************
100.0
90.0
70.0
我们可以分析下这种写法有什么不好的地方:
- 违反了单一职责原则:每种会员的计算方式都写在了CalculatorRealAmount类中;
- 违法了开闭原则:如果又新出了一个会员等级,那么就得修改calculator这个方法。
8.5使用策略模式实现
如果改用策略模式,其实现如下:
//1 定义一个策略接口,定义计算方法的操作
interface CalculateStrategy {
double calculator(double price);
}
//2.1 实现各个算法:普通用户的计算方法
class CommonUserCalculateStrategy implements CalculateStrategy{
@Override
public double calculator(double price) {
return price;
}
}
//2.2 实现各个算法:普通会员的计算方法
class CommonMemberCalculateStrategy implements CalculateStrategy{
@Override
public double calculator(double price) {
return price * 0.9;
}
}
//2.3 实现各个算法:超级会员的计算方法
class SuperMemberCalculateStrategy implements CalculateStrategy{
@Override
public double calculator(double price) {
return price * 0.7;
}
}
//3 定义上下文类,所谓上下文类,就是集成算法的类。
class StrategyContext{
private CalculateStrategy calculateStrategy;
public StrategyContext(CalculateStrategy calculateStrategy) {
this.calculateStrategy = calculateStrategy;
}
public double calculatorRealAmount(double price){
return calculateStrategy.calculator(price);
}
}
public class StrategyPatternExample {
public static void main(String[] args) {
StrategyContext commonUser = new StrategyContext(new CommonUserCalculateStrategy());
System.out.println("普通用户实际支付金额:" + commonUser.calculatorRealAmount(100));
StrategyContext commonMember = new StrategyContext(new CommonMemberCalculateStrategy());
System.out.println("普通会员实际支付金额:" + commonMember.calculatorRealAmount(100));
StrategyContext SuperMember = new StrategyContext(new SuperMemberCalculateStrategy());
System.out.println("超级会员实际支付金额:" + SuperMember.calculatorRealAmount(100));
}
}
******************【运行结果】******************
普通用户实际支付金额:100.0
普通会员实际支付金额:90.0
超级会员实际支付金额:70.0
好了,我们总结下策略模式实现的过程:
第一步:首先定义一个接口CalculateStrategy,该接口定义了计算价格方法,具体实现方式由具体的策略类来定义。
第二步:针对不同的会员等级,定义三种具体的策略类,每个类中都分别实现计算价格方法。
第三步:定义上下文类StrategyContext,这种类是集成算法的类。该类的定义体现了多用组合,少用继承。针对接口,不针对实现两个设计原则。
8.6策略方法模式特点
优点:
- 1.体现了单一职责原则:每个策略类负责实现对应会员等级的计算方法。
- 2.体遵循了开闭原则:使用了策略模式之后,如果又新出了一个会员等级,只需针对新增的等级实现一个策略类即可,不需要修改原有的代码。
缺点:
- 1.首先是类增多了,这个也是大部分设计模式的通病了;
- 2.其次,客户在使用的时候必须知道所有的策略类,并自行决定使用哪一个策略类,就拿文中的例子来说,如果我们需要计算超级会员的价格,new StrategyContext(new SuperMemberCalculateStrategy()),必须知道SuperMemberCalculateStrategy这个类是用来计算超级会员的价格的。
9.模板方法模式
9.1概述
李建中老师在微软有个设计模式的系列讲座,其中在讲到模板方法模式时说过这么一句:如果你只想学习一种设计模式就学习模板方法吧。由此可见它的重要性。
先来看看模板方法模式的定义:在一个方法中定义一个算法的大体框架,而将一些步骤的实现延迟到子类中,使得子类可以在不改变一个算法的结构前提下即可重定义该算法的某些特定步骤。
定义看不懂,没事,理论需要结合实践,等学习完后自己将这个设计模式实现出来后再回过头来看,你一定会恍然大悟:原来就是这样啊。
9.2使用场景
在学习设计模式的时候,每种设计模式的使用场景才是我们最需要关注的一个重点。
如果你在写代码的过程中,遇到下面两种情况,那么就可以停下来思考是不是可以用模板方法模式了:
- • 1.算法的整体步骤很固定,但其中个别部分易变时,这时候可以使用模板方法模式,将容易变的部分抽象出来,供子类实现。
- • 2.当多个子类存在公共的行为时,可以将其提取出来并集中到一个公共父类中以避免代码重复。首先,要识别现有代码中的不同之处,并且将不同之处分离为新的操作。最后,用一个调用这些新的操作的模板方法来替换这些不同的代码。
好吧,还是举个例子吧:小二哥所在的xx公司眼见BAT的某个公司游戏业务每年赚了个盆满钵满,于是也决定向游戏业进军了,由于公司老总是个麻将迷,因此公司决定开发的第一个游戏是麻将类的游戏app。
众所周知,对于麻将不同地方有不同的玩法,因此这个app,用户首先用账号登录游戏,然后可以选择玩法,最后是退出游戏。这里,登录游戏和退出游戏不区分玩法,也就是说无论哪种玩法 ,登录和退出的行为一模一样。但是具体的玩麻将的过程,不同的地方的玩法是不一样的,这个是不能复用的。这种场景就很适合用模板方法模式。
9.3UML类图
以上面的场景为例,模板方法模式的UML类图如下:
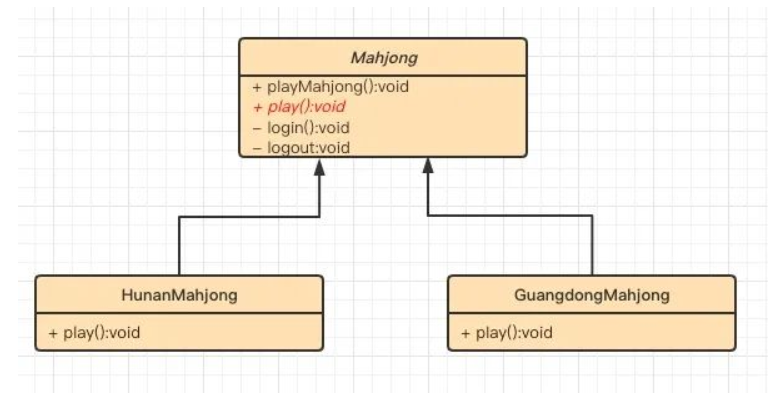
UML 类图也比较简单,只有两个部分:
- 1.Mahjong抽象类:这个类是模板类,类中的final方法playMahjong定义了算法的骨架。
- 2.多个实现类:如HunanMahjong和GuangdongMahjong,实现类中实现了抽象类中的抽象方法,这样在执行抽象类的playMahjong时,如果playMahjong中调用了抽象方法,最终会调用对应实现类中的 该方法。
9.4模板方法模式实现
下面是根据上面的场景用模板方法模式实现的代码:
//麻将类
abstract class Mahjong{
//final方法,定义了算法的骨架
public final void playMahjong(){
login();
play();
logout();
}
private void login(){
System.out.println("登录游戏!");
}
private void logout(){
System.out.println("退出游戏!");
}
//抽象方法,由其子类实现
public abstract void play();
}
//湖南麻将类
class HunanMahjong extends Mahjong{
@Override
public void play() {
System.out.println("湖南麻将进行中");
}
}
//广东麻将类
class GuangdongMahjong extends Mahjong{
@Override
public void play() {
System.out.println("广东麻将进行中");
}
}
public class TemplateMethodExample {
public static void main(String[] args) {
Mahjong hunanMahjong = new HunanMahjong();
hunanMahjong.playMahjong();
System.out.println();
Mahjong guangdongMahjong = new GuangdongMahjong();
guangdongMahjong.playMahjong();
}
}
******************【运行结果】******************
登录游戏!
湖南麻将进行中
退出游戏!
登录游戏!
广东麻将进行中
退出游戏!
可以看出,需要玩哪个地方的麻将,只需要实例化对应实现类的对象,然后调用抽象类的playMahjong方法即可。
好了,我们总结下模板方法模式实现的过程:
第一步:首先定义一个抽象的模板类Mahjong,并且定义了四个方法:模板方法playMahjong定义了整个框架;两个普通方法login, logout,子类复用,不需要子类实现;抽象放方法play,需要子类去实现,因为每个地方的玩法不一样。
第二步:定义具体的实体类,并实现父类的抽象方法。
9.5模板方法模式特点
**优点:**提高了代码的复用度,而且很好的符合的“开闭原则”。比如说过段时间,四川麻将又很流行了,公司决定上线四川麻将,只需要用一个四川麻将类继承抽象类就可以了。
**缺点:**首先是类增多了;其次,模板方法模式使得程序流程变成了父类调用子类方法,使得程序比较难以理解,因为正常情况下,程序的执行流是子类调用父类的方法。















 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









