







我们知道Excel有一个match函数,可以做数据匹配。
比如要根据人名获取成绩
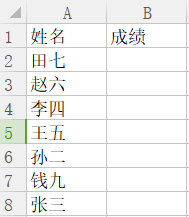
而参考表sheet1的内容如下:
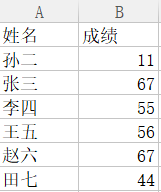
要根据sheet1匹配每人的成绩,用Excel是这么写
index(Sheet1!B:B,MATCH(A2,Sheet1!A:A,0))
意思就是获取sheet1的B列的内容,根据我的A列匹配sheet1的A列的内容
但是如何用python实现这一点呢,我写了一个函数,非常好用,分享给大家。
这个函数考虑到了匹配多个字段,多个sheet,而且匹配后单元格格式不变!
import pandas as pd
from openpyxl import load_workbook
def match(file,sheetnames,reffile,refsheet,targetsegs,matchseg) #文件名 sheet列表 参考文件名 参考sheet 目标字段列表 参考字段
refdata=pd.read_excel(reffile,refsheet)
if(not targetsegs[0] in refdata.columns or not matchseg in refdata.columns):
print('要匹配的字段不在参考表格中,请检查')
wb=load_workbook(file) #打开文件
#从参考表获取映射字典
maps={}
for i in refdata.index:
MatchSeg=refdata.loc[i,matchseg]
maps[MatchSeg]={}
for seg in targetsegs:
maps[MatchSeg][seg]=refdata.loc[i,seg]
#匹配数据
for sheet in sheetnames: #处理每个sheet
if(isinstance(sheet,int)):
sheet=wb.sheetnames[sheet] #如果是sheet编号,换算成名称
ws=wb[sheet]
cols=next(ws.values) #标题行
length=ws.max_row #总行数
for i in range(2,length+1):
refindex=cols.index(matchseg) #参考字段序号
MatchSeg=ws.cell(row=i,column=refindex+1).value #参考字段的值
for seg in targetsegs:
index=cols.index(seg) #要匹配字段的序号
try:
ws.cell(row=i,column=index+1).value=maps[MatchSeg][seg] #匹配
except Exception as e:
pass
print(sheet+"已经匹配")
wb.save(file) #保存
match('要匹配的表.xlsx',[0,1],'参考表.xlsx','参考页',['要匹配的字段1,字段2'],'参考字段')
我这里还制作了一个GUI工具,可供下载
已经分享到百度网盘,如要获取,请关注私聊

这个工具非常便利















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









