







复合文档文件格式研究(转)
前 言
复合文档(Compound Document) 是一种不仅包含文本而且包括图形、电子表格数据、声音、视频图象以及其它信息的文档。可以把复合文档想象成一个所有者,它装着文本、图形以及多媒体信息如 声音和图象。目前建立复合文档的趋势是使用面向对象技术,在这里,非标准信息如图像和声音可以作为独立的、自包含式对象包含在文档中。Microsoft Windows就是使用这种技术,叫做“OLE2 storage file format”或“Microsoft Office compatible storage file format”。
当然Excel、Word等都是用这种格式存储的。本文主要研究复合文档的二进制结构。
目 录
第一章 仓库与流(Storages and Streams)
第二章 扇区与扇区链(Sectors and Sector Chains)
第三章 复合文档头(Compound Document Header)
第四章 扇区配置(Sector Allocation)
第五章 短流(Short-Streams)
第六章 目录(Directory)
第七章 Excel文件实例剖析
第一章 仓库与流
复合文档的原理就像一个文件系统(文件系统:如FAT与NTFS)。复合文档将数据分成许多流(Streams),这些流又存储在不同的仓库(Storages)里。将复合文档想象成你的D盘,D盘用的是NTFS(NT File System)格式,流就相当于D盘里的文件,仓库就相当于D盘里的文件夹。
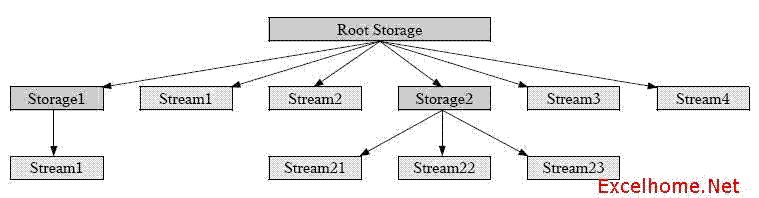
流和仓库的命名规则与文件系统相似,同一个仓库下的流及仓库不能重名,不同仓库下可以有同名的流。每个复合文档都有一个根仓库(root storage)。
例:
第二章 扇区与扇区链
2.1 扇区与扇区标识
所有的流又分成更小的数据块,叫做数据扇区(sectors)。Sectors 可能包含控制数据或用户数据。
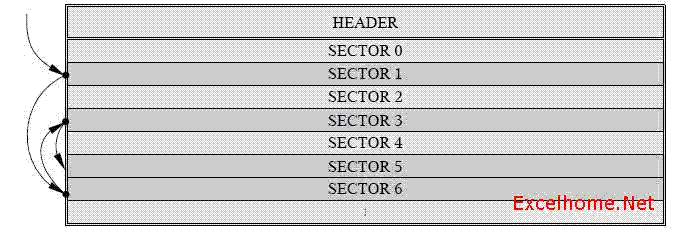
整个文件由一个头(Header)结构以及其后的所有Sectors组成。Sectors的大小在头中确定,且每个Sectors的大小都相同。
以下为示意图:
HEADER
SECTOR 0
SECTOR 1
SECTOR 2
SECTOR 3
SECTOR 4
SECTOR 5
SECTOR 6
┆
Sectors 简单的以其在文件中的顺序列举,一个扇区的索引(从0开始)叫做扇区标识(SID:sector identifier)。SID是一个有符号的32位的整型值。
如果一个SID的值非负,就表示真正存在的那个Sector;如果为负,就表示特殊的含义。下表给出有效的特殊SID:
SID Name Meaning
–1 Free SID 空闲sector,可存在于文件中,但不是任何流的组成部分。
–2 End Of Chain SID SID链的结束标记 (见2.2节)
–3 SAT SID 此Sector用于存放扇区配置表(SAT)(见4.2节)
–4 MSAT SID 此Sector用于存放主扇区配置表(MSAT)(见4.1节)
2.2 扇区链与扇区标识链
用于存储流数据的所有Sectors的列表叫做扇区链(Sector Chain)。这些Sectors可以是无序的。因此用于指定一个流的Sectors的顺序的SID数组就称为SID chain。一个SID chain总是以End Of Chain SID(-2)为结束标记。
例:一个流由4个Sector组成,其SID链为[1, 6, 3, 5, –2]。
流的SID链是通过扇区配置表构建的(见4.2节),但短流和以下两种内部流除外:
1.主扇区配置表,其从自身构建SID链(每个扇区包含下一个扇区的SID)。
2.扇区配置表,其通过主扇区配置表构建SID链。
第三章 复合文档头
3.1 复合文档头的内容
复合文档头在文件的开始,且其大小必定为512字节。这意味着第一个Sector的开始相对文件的偏移量为512字节。
复合文档头的结构如下:
Offset Size Contents
0 8 复合文档文件标识:D0H CFH 11H E0H A1H B1H 1AH E1H
8 16 此文件的唯一标识(不重要, 可全部为0)
24 2 文件格式修订号 (一般为003EH)
26 2 文件格式版本号(一般为0003H)
28 2 字节顺序规则标识(见3.2)::FEH FFH = Little-Endian FFH FEH = Big-Endian
30 2 复合文档中sector的大小(ssz),以2的幂形式存储, sector实际大小为s_size= 2ssz 字节
(一般为9即512字节, 最小值为7即128字节)
32 2 short-sector的大小(见5.1),以2的幂形式存储, short-sector实际大
小为s_s_size = 2sssz 字节(一般为6即64字节,最大为sector的大小)
34 10 Not used
44 4 用于存放扇区配置表(SAT)的sector总数
48 4 用于存放目录流的第一个sector的SID (见6)
52 4 Not used
56 4 标准流的最小大小(一般为4096 bytes), 小于此值的流即为短流。
60 4 用于存放短扇区配置表(SSAT)的第一个sector的SID (见5.2),或为–2 (End Of Chain SID)如不存在。
64 4 用于存放短扇区配置表(SSAT)的sector总数
68 4 用于存放主扇区配置表(MSAT)的第一个sector的SID (见4.1),或为–2 (End Of Chain SID) 若无附加的sectors。
72 4 用于存放主扇区配置表(MSAT)的sector总数
76 436 存放主扇区配置表(MSAT)的第一部分,包含109个SID。
3.2 字节顺序(Byte Order)
文件数据的二进制存储有两种方法Little-Endian 和 Big-Endian,但实际应用中只使用Little-Endian方法即:低位8字节存放在地址的低位,高位8字节存放在地址的高位。
例:一个32位的整数13579BDFH(转为十进制即324508639),以Little-Endian存放为DFH 9BH 57H13H,以Big-Endian 存放为 13H 57H 9BH DFH。(H下标表示十六进制)
3.3 扇区偏移量
从头中的信息可以计算出一个sector的偏移量(offset),公式为:
sec_pos(SID) = 512 + SID ∙ s_size = 512 + SID ∙ 2 ssz
例:ssz = 10 and SID = 5:
sec_pos(SID) = 512 + SID ∙ 2 ssz = 512 + 5 ∙ 210 = 512 + 5 ∙ 1024 = 5632.
第四章 扇区配置
4.1 主扇区配置表
主扇区配置表(MSAT:master sector allocation table)是一个SID数组,指明了所有用于存放扇区配置表(SAT:sector allocation table)的sector的SID。MSAT的大小(SID个数)就等于存放SAT的sector数,在头中指明。
MSAT的前109个SID也存放于头中,如果一个MSAT的SID数多余109个,那么多出来的SID将存放于sector中,头中已经指明了用于存放MSAT的第一个sector的SID。在用于存放MSAT的sector中的最后一个SID指向下一个用于存放MSAT的sector,如果没有下一个则为End Of Chain SID(-2)。
存放MSAT的sector的内容:(s_size表示sector的大小)
Offset Size Contents
0 s_size-4 MSAT的(s_size-4) / 4个SID的数组
s_size-4 4 下一个用于存放MSAT的sector的SID,或-2(已为最后一个)
最后一个存放MSAT的sector可能未被完全填满,空闲的地方将被填上Free SID(-1)。
例:一个复合文档需要300个sector用于存放SAT,头中指定sector的大小为512字节,这说明一个sector可存放128个SID。MAST有300个SID,前109个放于头中,其余的191个将要占用2个sector来存放。此例假定第一个存放MSAT的sector为sector 1,则sector 1包含127个SID。第128个SID指向一个用于存放MSAT的sector,假定为sector 6,则sector 6包含剩下的64个SID(最后一个SID为-2,其他的值为-1)。
4.2 扇区配置表
扇区配置表(SAT:sector allocation table)是一个SID数组,包含所有用户流(短流除外)和内部控制流(the short-stream container stream, 见5.1, the short-sector allocation table, 见5.2, and the directory, 见7)的SID链。SAT的大小(SID个数)就等于复合文档中所存在的sector的个数。
SAT的建立就是通过按顺序读取MSAT中指定的sector中的内容。
存放SAT的sector的内容:(s_size表示sector的大小)
Offset Size Contents
0 s_size SAT的s_size / 4个SID的数组
当通过SAT为一个流创建SID链时,SAT数组的当前位置(array index)表示的就是当前的sector,而该位置存放的SID则指向下一个sector。
SAT可能在任意位置包含Free SID(-1),这些sector将不被流使用。如果该位置包含End Of Chain SID(-2)表示一个流的结束。如果sector用于存放SAT则为SAT SID(-3),同样用于存放MSAT则为MSAT SID(-4)。
一个SID链的起点从用户流的目录入口(directory entry,见6.2节)或头(内部控制流)或目录流本身获得。
例:一个复合文档包含一个用于存放SAT的sector(sector 1)和2个流。
Sector 1的内容如下图:

在位置1其值为-3,表明Sector 1是SAT的一部分。
其中一个流为内部目录流,假定头中指定其开始为Sector 0,SAT中位置0的值为2,位置2的值为3,位置3 的值为-2。因此目录流的SID链为[0, 2, 3, –2],即此目录流存放于3个sector中。
目录中包含一个用户流的入口假定为sector 10,从图中可看出此流的SID链为[10, 6, 7, 8, 9, –2]。
第五章 短流
5.1 短流存放流
当一个流的大小小于指定的值(在头中指定),就称为短流(short-stream)。
短流并不是直接使用sector存放数据,而是内含在一种特殊的内部控制流——短流存放流(short-stream container stream)中。
短流存放流象其他的用户流一样:先从目录中的根仓库入口(root storage entry)获得第一个使用的sector,其SID链从SAT中获得。然后此流将其所占用的sectors分成short-sector,以便用来存放短流。此处也许较难理解,我们来打个比方:既然流组成符合文档,而短流组成短流存放流,这两者是相似的。把短流存放流当作复合文档,那么短流对应流,short-sector对应sector,唯一的不同是复合文档有一个头结构,而短流存放流没有。short-sector的大小在头中已经指定,因此可根据SID计算short-sector相对于短流存放流的偏移量(offset)。公式为:
short_s_pos(SID) = SID ∙ short_s_size = SID ∙ 2 sssz
例:sssz = 6 and SID = 5:
short_s_pos(SID) = SID ∙ 2 sssz = 5 ∙ 26 = 5 ∙ 64 = 320.
5.2 短扇区配置表
短扇区配置表(SSAT:short-sector allocation table)是一个SID数组,包含所有短流的SID链。与SAT很相似。
用于存放SSAT的第一个sector的SID在头中指定,其余的SID链从SAT中获得。
存放SSAT的sector的内容:(s_size表示sector的大小)
Offset Size Contents
0 s_size SSAT的s_size / 4个SID的数组
SSAT的用法与SAT类似,不同的是其SID链引用的是short-sector。
第六章 目录
6.1 目录结构
目录(directory)是一种内部控制流,由一系列目录入口(directory entry)组成。每一个目录入口都指向复合文档的一个仓库或流。目录入口以其在目录流中出现的顺序被列举,一个以0开始的目录入口索引称为目录入口标识(DID: directory entry identifier)。
如下图所示:
DIRECTORY ENTRY 0
DIRECTORY ENTRY 1
DIRECTORY ENTRY 2
DIRECTORY ENTRY 3
⋮
目录入口的位置不因其指向的仓库或流的存在与否而改变。如果一个仓库或流被删除了,其相应的目录入口就标记为空。在目录的开始有一个特殊的目录入口,叫做根仓库入口(root storage entry),其指向根仓库。
目录将每个仓库的直接成员(仓库或流)放在一个独立的红黑树(red-black tree)中。红黑树是一种树状的数据结构,本文仅简单介绍一下,详细情况请参考有关资料。
建构一个Red-Black tree的规则:
1. 每个节点(node)的颜色属性不是红就是黑。
2. 根节点一定是黑的。
3. 如果某个节点是红的,那它的子节点一定是黑的。
4. 从根节点到每个叶节点的路径(path)必须有相同数目的黑节点。
ex: B (用图形来解说第4点,从根节点
/ / 到最底层的node,你会发现每个
B B path都恰好有3个black node)
/ / / /
B B R B
/ / / / /
R B B R R
/ /
R R
注意并不总是执行上述规则。安全的方法是忽略节点的颜色。
例:以第一章中的图为例
1.根仓库入口描述根仓库,它不是任何仓库入口的成员,因此无需构建红黑树。
2.根仓库的所有直接成员(“Storage1”, “Storage2”, “Stream1”, “Stream2”, “Stream3”, 和 “Stream4”)将组成一棵红黑树,其根节点的DID存放于根仓库入口中。
3.仓库Storage1只有一个成员Stream1,Stream1构成一棵红黑树,此树只有一个节点。Storage1的目录入口包含Stream1的DID。
4. 仓库Storage2包含3个成员“Stream21”, “Stream22”, 和“Stream23”。这3个成员将构建一棵红黑树,其根节点的DID存放于Storage2的目录入口中。
这种存放规则将导致每个目录入口都包含3个DID:
1.在包含此目录入口的红黑树中,此目录入口的左节点的DID。
2.在包含此目录入口的红黑树中,此目录入口的右节点的DID。
3.若此目录入口表示一个仓库,则还包含此仓库的直接成员所组成的另一颗红黑树的根节点的DID。
在构建红黑树的过程中,一个节点究竟作为左还是右,是通过比较其名字来判断的。一个节点比另一个小是指其名字的长度更短,如长度一样,则逐字符比较。
规定:左节点<根节点<右节点。
6.2 目录入口
一个目录入口的大小严格地为128字节,计算其相对目录流的偏移量的公式为:dir_entry_pos(DID) = DID ∙ 128。目录入口的内容:
Offset Size Contents
0 64 此入口的名字(字符数组), 一般为16位的Unicode字符,以0结束。(因此最大长度为31个字符)
64 2 用于存放名字的区域的大小,包括结尾的0。(如:一个名字右5个字符则此值为(5+1)∙2 = 12)
66 1 入口类型: 00H = Empty 03H = LockBytes (unknown) 01H = User storage
04H = Property (unknown) 02H = User stream 05H = Root storage
67 1 此入口的节点颜色: 00H = Red 01H = Black
68 4 其左节点的DID (若此入口为一个user storage or stream) 若没有左节点就为-1。
72 4 其右节点的DID (若此入口为一个user storage or stream), 若没有右节点就为-1。
76 4 其成员红黑树的根节点的DID (若此入口为storage), 其他为-1。
80 16 唯一标识符(若为storage)(不重要, 可能全为0)
96 4 用户标记(不重要, 可能全为0)
100 8 创建此入口的时间标记。大多数情况都不写。
108 8 最后修改此入口的时间标记。大多数情况都不写。
116 4 若此为流的入口,指定流的第一个sector或short-sector的SID,若此为根仓库入口,指定短流存放流的第一个sector的SID,其他情况,为0。
120 4 若此为流的入口,指定流的大小(字节)若此为根仓库入口,指定短流存放流的大小(字节)其他情况,为0。
124 4 Not used
时间标记(time stamp) 是一个符号的64位的整数,表示从1601-01-01 00:00:00开始的时间值。此值的单位为10-7秒。
当计算时间标记是要注意闰年。
例:时间标记值为01AE408B10149C00H
计算步骤 公式 结果
转为十进制 t0 = 121,105,206,000,000,000
化成秒的余数 rfrac = t0 mod 107 rfrac = 0
化成秒的整数 t1 = t0 / 107 t1 = 12,110,520,600
化成分的余数 rsec = t1 mod 60 rsec = 0
化成秒的整数 t2 = t1 / 60 t2 = 201,842,010
化成小时的余数 rmin = t2 mod 60 rmin = 30
化成小时的整数 t3 = t2 / 60 t3 = 3,364,033
化成天的余数 rhour = t3 mod 24 rhour = 1
化成天的整数 t4 = t3 / 24 t4 = 140,168
距1601-01-01的整年 ryear = 1601 + t4含的年 ryear = 1601 + 383 = 1984
到1984年还剩的天数 t5 = t4 – (1601-01-01 t5 = 140,168 – 139,887 = 281
到1984-01-01的天数)
距1984-01-01的月数 rmonth = 1 + t5含的月数 rmonth = 1 + 9 = 10
到10月还剩的天数 t6 = t5 – (1984-01-01 t6 = 281 – 274 = 7
到1984-10-01的天数)
10月最终天数 rday = 1 + t6 rday = 1 + 7 = 8
第七章 Excel文件实例剖析
这章我们以一个Excel文件作为实例来分析其二进制结构。看实例永远是最好的学习方法,呵呵。
1.复合文档头
首先,读取此文件头,假定此Excel文件的头(512字节)内容如下:
00000000H D0 CF 11 E0 A1 B1 1A E1 00 00 00 00 00 00 00 00
00000010H 00 00 00 00 00 00 00 00 3B 00 03 00 FE FF 09 00
00000020H 06 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
00000030H 0A 00 00 00 00 00 00 00 00 10 00 00 02 00 00 00
00000040H 01 00 00 00 FE FF FF FF 00 00 00 00 00 00 00 00
00000050H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000060H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000070H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000080H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000090H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000A0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000B0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000C0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000D0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000000F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000100H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000110H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000120H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000130H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000140H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000150H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000160H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000170H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000180H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000190H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001A0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001B0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001C0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001D0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000001F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
1)前8个字节是固定的标识,表示这是一个复合文档文件。
00000000H D0 CF 11 E0 A1 B1 1A E1 00 00 00 00 00 00 00 00
2)接着16个字节是唯一标识,其后的4个字节表示修订号和版本号,可不用管它。
00000000H D0 CF 11 E0 A1 B1 1A E1 00 00 00 00 00 00 00 00
00000010H 00 00 00 00 00 00 00 00 3B 00 03 00 FE FF 09 00
3)接下来的2个字节是字节顺序(Byte Order)标识符,总是FEH FFH。
00000010H 00 00 00 00 00 00 00 00 3B 00 03 00 FE FF 09 00
4)接着的2个字节表示sector的大小,再2个字节表示short-sector的大小。分别是2^9=512字节和2^6=64字节。
00000010H 00 00 00 00 00 00 00 00 3B 00 03 00 FE FF 09 00
00000020H 06 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
5)接着的10个字节无有效数据,可忽略。
00000020H 06 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
6)接着的4个字节表示用于存放扇区配置表(SAT)的sector总数,此例为1个。
00000020H 06 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00
7)接着的4个字节表示用于存放目录流的第一个sector的SID,这里为sector 10。
00000030H 0A 00 00 00 00 00 00 00 00 10 00 00 02 00 00 00
8)接着的4个字节无有效数据,可忽略。
00000030H 0A 00 00 00 00 00 00 00 00 10 00 00 02 00 00 00
9)接着的4个字节表示标准流的最小大小,这里为00001000H = 4096字节。
00000030H 0A 00 00 00 00 00 00 00 00 10 00 00 02 00 00 00
10)接着的4个字节表示用于存放短扇区配置表(SSAT)的第一个sector的SID,其后4个字节表示用于存放短扇区配置表(SSAT)的sector总数,这里SSAT从sector 2开始,并只占用1个sector。
00000030H 0A 00 00 00 00 00 00 00 00 10 00 00 02 00 00 00
00000040H 01 00 00 00 FE FF FF FF 00 00 00 00 00 00 00 00
11)接着的4个字节表示用于存放主扇区配置表(MSAT)的第一个sector的SID,其后的4个字节表示用于存放主扇区配置表(MSAT)的sector总数,这里SID为-2,说明没有附加的sector用于存放MSAT。
00000040H 01 00 00 00 FE FF FF FF 00 00 00 00 00 00 00 00
12)最后的436个字节包含MSAT的前109个SID。只有第一个SID有效,因为上面已经说了SAT只占用1个sector。从这里可看出为sector 0。其他的SID标记为Free SID值为-1。
00000040H 01 00 00 00 FE FF FF FF 00 00 00 00 00 00 00 00
00000050H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000060H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
…… ……
2. 主扇区配置表
头中已经包含整个MSAT,其SID链为[0,-2]。
3. 扇区配置表
在此例中扇区配置表仅占用sector 0,它开始于文件偏移量为00000200H = 512字节处。假定内容如下:
00000200H FD FF FF FF FF FF FF FF FE FF FF FF 04 00 00 00
00000210H 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00
00000220H 09 00 00 00 FE FF FF FF 0B 00 00 00 FE FF FF FF
00000230H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000240H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000250H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000260H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000270H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000280H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000290H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002A0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002B0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002C0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002D0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000002F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000300H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000310H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000320H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000330H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000340H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000350H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000360H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000370H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000380H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000390H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003A0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003B0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003C0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003D0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000003F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
因此可构建SAT的SID数组为:
Array index 0 1 2 3 4 5 6 7 8 9 10 11 12 …
SID array | –3 | –1 | –2 | 4 | 5 | 6 | 7 | 8 | 9 | –2 | 11 | –2| –1| … |
可看出sector 0被标记为SAT SID(-3),sector 1和sector 12及其后的所有sector都未被使用。
4. 短扇区配置表
在头中我们知道SSAT从sector 2开始只占用一个sector。从SAT中可看出位置2的值为-2,表示结束,故SSAT的SID链为[2, –2]。
开始于文件偏移量为00000600H = 1536字节处。
假定内容如下:
00000600H 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00
00000610H 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00
00000620H 09 00 00 00 0A 00 00 00 0B 00 00 00 0C 00 00 00
00000630H 0D 00 00 00 0E 00 00 00 0F 00 00 00 10 00 00 00
00000640H 11 00 00 00 12 00 00 00 13 00 00 00 14 00 00 00
00000650H 15 00 00 00 16 00 00 00 17 00 00 00 18 00 00 00
00000660H 19 00 00 00 1A 00 00 00 1B 00 00 00 1C 00 00 00
00000670H 1D 00 00 00 1E 00 00 00 1F 00 00 00 20 00 00 00
00000680H 21 00 00 00 22 00 00 00 23 00 00 00 24 00 00 00
00000690H 25 00 00 00 26 00 00 00 27 00 00 00 28 00 00 00
000006A0H 29 00 00 00 2A 00 00 00 2B 00 00 00 2C 00 00 00
000006B0H 2D 00 00 00 FE FF FF FF 2F 00 00 00 FE FF FF FF
000006C0H FE FF FF FF 32 00 00 00 33 00 00 00 34 00 00 00
000006D0H 35 00 00 00 FE FF FF FF FF FF FF FF FF FF FF FF
000006E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000006F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000700H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000710H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000720H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000730H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000740H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000750H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000760H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000770H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000780H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
00000790H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007A0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007B0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007C0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007D0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007E0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
000007F0H FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF FF
因此可构建SSAT的SID数组为:

从sector 54开始所有的short-sectors都未被使用。
5.目录
头中指明用于存放目录流的第一个sector为sector 10。目录总是存放于sector中,而不是short-sector中。故从SAT构建SID链为[10, 11, –2]。sector 10的偏移量为00001600H = 5632, sector 11的偏移量为00001800H = 6144。此例中sector的大小为512字节,因此每个sector包含4个目录入口(一个目录入口128字节),故此目录共包含8个入口。
<1>根仓库入口(Root Storage Entry)
第一个目录入口总是根目录入口,假定其内容如下:
00001600H 52 00 6F 00 6F 00 74 00 20 00 45 00 6E 00 74 00
00001610H 72 00 79 00 00 00 00 00 00 00 00 00 00 00 00 00
00001620H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00001630H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
00001650H 10 08 02 00 00 00 00 00 C0 00 00 00 00 00 00 46
00001660H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00001670H 00 00 00 00 03 00 00 00 80 0D 00 00 00 00 00 00
1)前64个字节是此入口名字的字符数组(为16位的字符, 以第一个00结束),
可看出此入口的名字是“Root Entry”。
00001600H 52 00 6F 00 6F 00 74 00 20 00 45 00 6E 00 74 00
00001610H 72 00 79 00 00 00 00 00 00 00 00 00 00 00 00 00
00001620H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00001630H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
2)接着2个字节表示用于存放上述字符数组的有效区域的大小,这里是22字节,只有10个有效字符。
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
3)接着1个字节表示入口类型,根仓库入口故为05H。
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
4)接着1个字节表示入口节点颜色,这里为红色,打破了根仓库入口为黑的规定。
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
5)接着4个字节表示其左节点的DID,再接着4个字节表示右节点的DID。对根仓库入口来说都是-1。
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
6)接着4个字节表示根仓库入口的成员构建的红黑树的根节点的DID,此例为1。
00001640H 16 00 05 00 FF FF FF FF FF FF FF FF 01 00 00 00
7)接着16个字节表示唯一标识符,说明这是一个仓库,其后4字节表示用户标识,再接着是两个时间标记,各8字节,表明此仓库的创建时间和最后修改时间。这些数据都可忽略。
00001650H 10 08 02 00 00 00 00 00 C0 00 00 00 00 00 00 46
00001660H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00001670H 00 00 00 00 03 00 00 00 80 0D 00 00 00 00 00 00
8)接着4个字节表示短流存放流的第一个sector的SID,其后4字节表示短流存放流的大小。此例中第一个sector为sector 3,其大小为00000D80H = 3456字节。
00001670H 00 00 00 00 03 00 00 00 80 0D 00 00 00 00 00 00
9)最后4个字节无有效数据,可忽略。
00001670H 00 00 00 00 03 00 00 00 80 0D 00 00 00 00 00 00
<1>第二个目录入口
第二个目录入口(DID 1)假定其内容如下:
00001680H 57 00 6F 00 72 00 6B 00 62 00 6F 00 6F 00 6B 00
00001690H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000016A0H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000016B0H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000016C0H 12 00 02 00 02 00 00 00 04 00 00 00 FF FF FF FF
000016D0H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000016E0H 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
000016F0H 00 00 00 00 00 00 00 00 51 0B 00 00 00 00 00 00
用颜色标记的为重要数据。入口的名字是“Workbook”,它表示一个流。其左节点的DID是2,右节点的DID是4。其第一个sector的SID是0,其大小是00000B51H = 2897字节,小于4096字节,故其存放于短流存放流中。
<3>剩下的目录入口
剩下的目录入口可按上面的方法读取,下面给出目录:
从根仓库入口的第一个成员的DID(此为1)可以找到根仓库的所有成员。入口1有2个子节点,DID 2 和 DID 4,DID 2又有一个子节点DID 3,DID 3和DID 4都没有子节点了。因此根仓库包含DID 1、2、3、4这4个成员。
<4>流的SID链
短流存放流是存储在sector中的,小于4096字节的用户流(为短流)存储在短流存放流中,并使用SSAT构建SID链。
下表给出所有流的情况:
DID 流名 配置表 SID 链
0 Root Entry (短流存放流) SAT [3, 4, 5, 6, 7, 8, 9, –2]
1 Workbook SSAT [0, 1, 2, 3, 4, 5, …, 43, 44, 45, –2]
2 <01H>CompObj SSAT [46, 47, –2]
3 <01H>Ole SSAT [48, –2]
4 <05H>SummaryInformation SSAT [49, 50, 51, 52, 53, –2]
<5>流的读取
短流存放流读取其SID链中的所有sector,此例中将按顺序读取sector 3,4,5,6,7,8,9,故此流的大小为512×7=3584字节。但是只有前3456字节有效(根仓库入口中指定的)。这3456字节被分成大小为64字节的short-sector,一共54个。
现在我们来读取流“<01H>CompObj”,其SID链为[46, 47, –2],此流是一个短流。其数据存放在short-sector 46和short-sector 47中。short-sector 46在短流存放流中的偏移量为2944字节,short-sector 47的偏移量为3008字节。
[转]http://blog.csdn.net/liangjingbo/article/details/2874959本文是研究DOC文件格式的第一部分。office中的doc等文件在外层都遵循复合文档格式,而真正的doc内容主要是(也有其它流和仓库)作为复合文档的一系列流而存在。下面为转载的文章正文,讲解复合文档格式。根据下面的讲解,可以在doc文件中找到名字为“WordDocument”的目录,从而找到“WordDocument”流。
推荐一个查看office文档结构的工具,用于辅助学习过程:
原:https://download.csdn.net/download/chaoguodong/10429018
关于“WordDocument”流的分析,见:
原:http://blog.csdn.net/shadow20080578/article/details/50310257
WordDocument流的偏移0处是一个 FIB(File Information Block)。
FIB
FIB包含文档信息和指向文档各个部分的指针。
FIB由基础部分和扩展的节(section)组成,基础部分的长度固定,节的数量和长度可变,每一个节包含一个count域指明下一个节的长度。


图1,FIB结构
csw (2 bytes):无符号整形,指明后面的fibRgW个数。fibRgW大小为2字节,该值必须为0x000E。
fibRgW (28 bytes):为FibRgW97格式。
cslw (2 bytes):无符号整形,指明后面的fibRgLw个数。fibRgLw大小为4字节,该值必须为0x0016。
fibRgLw (88 bytes):格式为FibRgLw97。
cbRgFcLcb (2 bytes):无符号整形,指明后面的fibRgFcLcbBlob 个数。fibRgFcLcbBlob 大小为8字节。其值根据FibBase中的nFib而不同:

fibRgFcLcbBlob (可变):格式为FibRgFcLcb。
cswNew (2 bytes):无符号整形,指明后面的fibRgCswNew个数。fibRgCswNew大小为2字节。其值根据FibBase中的nFib而不同:
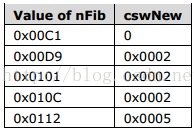
fibRgCswNew (variable):如果cswNew非0,结构为 fibRgCswNew。否则,该域在文件中不存在。
FibBase
FIB的起始部分为32字节的基础部分,如图2所示:
1) wIdent (2字节):用来说明这是一个woud二进制文件,值必须为0xA5EC。
2) nFib (2字节):说明文件格式的版本号,如果存在FibRgCswNew.nFibNew域,则被该域取代。值通常为0x00C1。
3) unused (2字节):被忽略。
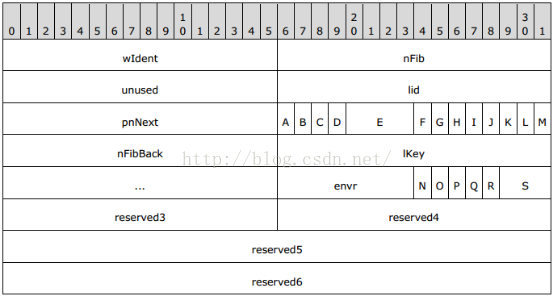
图2,FIB基础部分结构
4) lid (2字节):说明产生该文档的应用程序的语言。
5) pnNext (2字节):一个无符号整数,说明所有包含 AutoText(文档、图像)项的FIB在WordDocument流中的偏移,其位置为pnNext*512。如果为0,表示没有AutoText项。如果fGlsy是1或fDot是0,这个值必须是0。如果pnNext非0,则必须与FibRgFcLcb97.fcPlcBteChpx,FibRgFcLcb97.lcbPlcBteChpx,FibRgFcLcb97.fcPlcBtePapx,FibRgFcLcb97.lcbPlcBtePapx和FibRgLw97.cbMac的值相同。
6) A - fDot (1位):说明是否为文档模板。
7) B - fGlsy (1位):是否为一个只包含AutoText元素的文档。
8) C - fComplex (1位):该文档的最后一次保存操作是否为incremental save(除了附加或修改部分内容,保留其它内容,不是重建等)。
9) D - fHasPic (1位):为0,表示没有图片。
10) E - cQuickSaves (4位):无符号整形。如果nFib小于0x00D9,该域表示连续进行的incrementally save的次数。如果nFib大于等于0x00D9,该域必须为0xF。
11) F - fEncrypted (1位):说明该文档是否被加密或混淆。
12) G - fWhichTblStm (1 bit):为1,则文档使用1Table流,为0,则文档使用0Table流。
13) H - fReadOnlyRecommended (1 bit):是否文档只能以只读方式打开。
14) I - fWriteReservation (1 bit):文档执行写操作是否需要密码。
15) J - fExtChar (1 bit):为1。
16) K - fLoadOverride (1 bit):是否重写istd 0中段落格式中指定的语言信息和字体为与当前应用适应的值。
17) L - fFarEast (1 bit):创建文档的语言是否为East Asian language。
18) M - fObfuscated (1 bit):如果 fEncrypted为1,改为说明文档是否被执行异或混淆。
19) nFibBack (2 bytes):为0x00BF或0x00C1。
20) lKey (4 bytes): 如果fEncrypted和fObfuscation都是1,这个值是异或混淆验证器。如果fEncrypted是1fObfuscation都是0,则该域为EncryptionHeader的长度。否则为0。
21) envr (1 byte):必须为0,且被忽略。
22) N - fMac (1 bit):必须为0,且被忽略。
23) O - fEmptySpecial (1 bit):必须为0,且被忽略。
24) P - fLoadOverridePage (1 bit):是否根据所安装应用的语言修改页尺寸的节属性,方向。
25) Q - reserved1 (1 bit):忽略。
26) R - reserved2 (1 bit):忽略。
27) S - fSpare0 (3 bits):忽略。
28) reserved3 (2 bytes):必须为0,且被忽略。
29) reserved4 (2 bytes):必须为0,且被忽略。
30) reserved5 (4 bytes):被忽略。
31) reserved6 (4 bytes):被忽略。
SummaryInformation流:
原:http://blog.csdn.net/shadow20080578/article/details/50311985
这篇分析SummaryInformation流,该流为可选流,保存文档的摘要信息。该流的位置同样通过目录定位,其名字为0005SummaryInformation(0005为16进制数),定位方法见复合文档格式的分析(http://blog.csdn.net/shadow20080578/article/details/50245309)。
该流包含一个或多个属性组,每个属性组包含一个或多个属性。
1.开始为流的全局信息:
00H-01H为字节顺序,要求为0xFFFE。
02H-03H属性集版本。
04H为一字节的操作系统主版本号。
05H为一字节的操作系统次版本号。
06H-07H为操作系统类型,固定为0x0002.
08H-17H为10字节的CLSID,未设置时为默认的全0x00。
018H-01BH的4字节UInt32,是存储属性组的个数。
01CH开始的每20字节,是每个属性组的标志和偏移:
前16字节为FMTID,FMTID_SummaryInformation 是0xE0 0x85 0x9F 0xF2 0xF9 0x4F 0x68 0x10 0xAB 0x91 0x08 0x00 0x2B 0x27 0xB3 0xD9。
后4字节UInt32,则是该属性组相对于流起始的偏移。
2.利用偏移可以在流中定位到属性组,对于每个属性组,其结构如下:
000H-003H的4字节UInt32,是属性组大小。
004H-007H的4字节UInt32,是属性组中属性的个数。
008H开始的每8字节,是属性的信息:
对于前4字节UInt32,是属性编号,表示属性的种类。
Unknown = 0x00
CodePage = 0x01
Title = 0x02;文档标题
Subject = 0x03
Author = 0x04;文档作者
Keyword = 0x05;文档关键字
Commenct = 0x06;文档注释
Template = 0x07
LastAuthor = 0x08
Reversion = 0x09
EditTime = 0x0A
LastPrintTime = 0x0B
CreateDateTime = 0x0C
LastSaveDateTime = 0x0D
PageCount = 0x0E
WordCount = 0x0F
CharCount = 0x10
Thunbnail = 0x11
ApplicationName = 0x12
Security = 0x13
对于后4字节UInt32,是属性内容相对于属性组的偏移。
3.利用属性信息可以定位到属性组中的每个属性,对于每个属性,其结构如下:
000H-003H的4字节UInt32,是属性内容的类型:
类型为0x02时为UInt16
类型为0x03时为UInt32
类型为0x0B时为Boolean
类型为0x1E时为String
剩余的字节为属性的内容, 除了类型是String时为不定长,其余三种均为4位字节(多余字节置0)。类型是String时前4字节是字符串的长度(包括“\0”),所以没法使用BinaryReader的ReadString读取。之后长度为字符串内容,字符串是使用单字节编码进行存储的,可以使用Encoding中的GetString获取字符串内容。
DocumentSummaryInformation流:
原:http://blog.csdn.net/shadow20080578/article/details/50313095
这篇分析DocumentSummaryInformation流,该流为可选流,保存文档的摘要信息。该流的位置同样通过目录定位,其名字为0005DocumentSummaryInformation(0005为16进制数)。
该流包含一个或多个属性组,每个属性组包含一个或多个属性。
1.开始为流的全局信息:
00H-01H为字节顺序,要求为0xFFFE。
02H-03H属性集版本。
04H为一字节的操作系统主版本号。
05H为一字节的操作系统次版本号。
06H-07H为操作系统类型,固定为0x0002.
08H-17H为10字节的CLSID,未设置时为默认的全0x00。
018H-01BH的4字节UInt32,是存储属性组的个数。
01CH开始的每20字节,是每个属性组的标志和偏移:
前16字节为FMTID,FMTID_DocSummaryInformation 是0x02 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE。FMTID_UserDefinedProperties 是0x05 0xD5 0xCD 0xD5 0x9C 0x2E 0x1B 0x10 0x93 0x97 0x08 0x00 0x2B 0x2C 0xF9 0xAE。
后4字节UInt32,则是该属性组相对于流起始的偏移。
2.利用偏移可以在流中定位到属性组,对于每个属性组,其结构如下:
从000H到003H的4字节UInt32,是属性组大小。
从004H到007H的4字节UInt32,是属性组中属性的个数。
从008H开始的每8字节,是属性的信息:
对于前4字节UInt32,是属性编号,表示属性的种类:
Unknown = 0x00
CodePage = 0x01
Category = 0x02
PresentationTarget = 0x03,
Bytes = 0x04,
LineCount = 0x05,
ParagraphCount = 0x06,
Slides = 0x07,
Notes = 0x08,
HiddenSlides = 0x09,
MMClips = 0x0A,
Scale = 0x0B
HeadingPairs = 0x0C,
DocumentParts = 0x0D,
Manager = 0x0E,
Company = 0x0F,
LinksDirty = 0x10,
CountCharsWithSpaces = 0x11
SharedDoc = 0x13,
LINKBASE = 0x14
HLINKS = 0x15
HyperLinksChanged = 0x16
Version = 0x17
DIGSIG = 0x18
CONTENTTYPE = 0x1a
ContentStatus = 0x1b
LANGUAGE = 0x1c
DOCVERSION = 0x1d
对于后4字节UInt32,是属性内容相对于属性组的偏移。
3.利用属性信息可以定位到属性组中的每个属性,对于每个属性,其结构如下:
从000H到003H的4字节UInt32,是属性内容的类型:
类型为0x02时为UInt16。
类型为0x03时为UInt32。
类型为0x0B时为Boolean。
类型为0x1E时为String。
剩余的字节为属性的内容。
除了类型是String时为不定长,其余三种均为4位字节(多余字节置0)。类型是String时前4字节是字符串的长度(包括“\0”),所以没法使用BinaryReader的ReadString读取。之后长度为字符串内容,字符串是使用单字节编码进行存储的,可以使用Encoding中的GetString获取字符串内容。

















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









