







1. 简介
reduce side join是所有join中用时最长的一种join,但是这种方法能够适用
内连接、left外连接、right外连接、full外连接和反连接
等所有的join方式。reduce side join不仅可以对小数据进行join,也可以对大数据进行join,但是大数据会占用大量的集群内部网络IO,因为所有数据最终要写入到reduce端进行join。如果要做join的数据量非常大的话,就不得不用reduce join了。
2. 适用场景
-join的两部分数据量非常大;
-想要通过一种模式灵活的适用多种join。
3.Reduce side join的架构
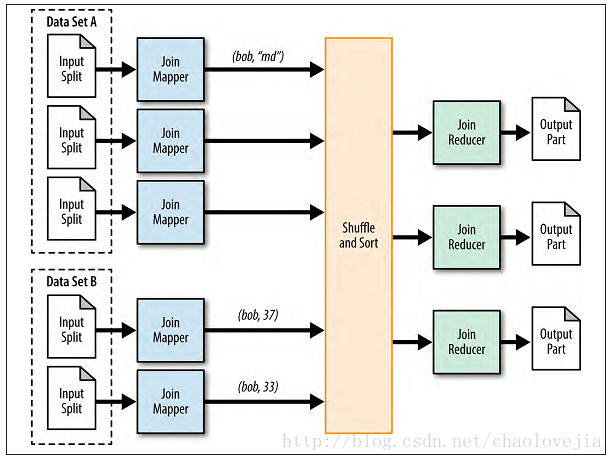
3.1 map 阶段
map 阶段首先从数据中提取出join的foreign key作为map输出的key,然后将输入的记录全部作为输出value。输出的value需要根据输入的数据集打上数据集的标签,比如在value的开头加上‘A’‘B’的标签。
3.2 reduce阶段
reduce端对具有同样foreign key的数据进行处理,对具有标签'A'和'B'的数据进行迭代处理,以下分别用伪代码对不同的join的处理进行说明。
-内连接:如果带有标签‘A’和‘B’的数据都存在,遍历并连接这些数据,然后输出
if (!listA.isEmpty() && !listB.isEmpty()) {
for (Text A : listA) {
for (Text B : listB) {
context.write(A, B);
}
}
}
-左外连接:右边的数据如果存在就与左边连接,否则将右边的字段都赋null,只输出左边
// For each entry in A,
for (Text A : listA) {
// If list B is not empty, join A and B
if (!listB.isEmpty()) {
for (Text B : listB) {
context.write(A, B);
}
} else {
// Else, output A by itself
context.write(A, EMPTY_TEXT);
}
}
-右外连接:与左外连接类似,左边为空就将左边赋值null,只输出右边
// For each entry in B,
for (Text B : listB) {
// If list A is not empty, join A and B
if (!listA.isEmpty()) {
for (Text A : listA) {
context.write(A, B);
}
} else {
// Else, output B by itself
context.write(EMPTY_TEXT, B);
}
}
-全外连接:这个要相对复杂点,首先输出A和B都不为空的,然后输出某一边为空的
// If list A is not empty
if (!listA.isEmpty()) {
// For each entry in A
for (Text A : listA) {
// If list B is not empty, join A with B
if (!listB.isEmpty()) {
for (Text B : listB) {
context.write(A, B);
}
} else {
// Else, output A by itself
context.write(A, EMPTY_TEXT);
}
}
} else {
// If list A is empty, just output B
for (Text B : listB) {
context.write(EMPTY_TEXT, B);
}
}
-反连接:输出A和B没有共同foreign key的值
// If list A is empty and B is empty or vice versa
if (listA.isEmpty() ^ listB.isEmpty()) {
// Iterate both A and B with null values
// The previous XOR check will make sure exactly one of
// these lists is empty and therefore the list will be skipped
for (Text A : listA) {
context.write(A, EMPTY_TEXT);
}
for (Text B : listB) {
context.write(EMPTY_TEXT, B);
}
}
4.实例
下面举一个简单的例子,要求能够用reduce side join方式实现以上所有的join。
4.1数据
User 表
---------------------------
username cityid
--------------------------
Li lei, 1
Xiao hong, 2
Lily, 3
Lucy, 3
Daive, 4
Jake, 5
Xiao Ming, 6
City表
---------------------------
cityid cityname
--------------------------
1, Shanghai
2, Beijing
3, Jinan
4, Guangzhou
7, Wuhan
8, Shenzhen
4.2 代码介绍
写两个mapper,一个mapper处理user数据,一个mapper处理city数据,在主函数中调用时用MultipleInputs类添加数据路径,并分别指派两个处理的Mapper;
往configuration中添加参数“join.type”,传给reducer,决定在reduce端采用什么样的join。
详细代码如下:
package com.study.hadoop.mapreduce;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class ReduceJoin {
//user map
public static class UserJoinMapper extends Mapper<Object, Text, Text, Text>{
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
String[] items = line.split(",");
outKey.set(items[1]);
outValue.set("A"+items[0]);
context.write(outKey, outValue);
}
}
//city map
public static class CityJoinMapper extends Mapper<Object, Text, Text, Text>{
// TODO Auto-generated constructor stub
private Text outKey = new Text();
private Text outValue = new Text();
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
String line = value.toString();
String[] items = line.split(",");
outKey.set(items[0]);
outValue.set("B"+items[1]);
context.write(outKey, outValue);
}
}
public static class JoinReducer extends Reducer<Text, Text, Text, Text>{
// TODO Auto-generated constructor stub
//Join type:{inner,leftOuter,rightOuter,fullOuter,anti}
private String joinType = null;
private static final Text EMPTY_VALUE = new Text("");
private List<Text> listA = new ArrayList<Text>();
private List<Text> listB = new ArrayList<Text>();
@Override
protected void setup(Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//获取join的类型
joinType = context.getConfiguration().get("join.type");
}
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
listA.clear();
listB.clear();
Iterator<Text> iterator = values.iterator();
while(iterator.hasNext()){
String value = iterator.next().toString();
if(value.charAt(0)=='A')
listA.add(new Text(value.substring(1)));
if(value.charAt(0)=='B')
listB.add(new Text(value.substring(1)));
}
joinAndWrite(context);
}
private void joinAndWrite(Context context)
throws IOException, InterruptedException{
//inner join
if(joinType.equalsIgnoreCase("inner")){
if(!listA.isEmpty() && !listB.isEmpty()) {
for (Text A : listA)
for(Text B : listB){
context.write(A, B);
}
}
}
//left outer join
if(joinType.equalsIgnoreCase("leftouter")){
if(!listA.isEmpty()){
for (Text A : listA){
if(!listB.isEmpty()){
for(Text B: listB){
context.write(A, B);
}
}
else{
context.write(A, EMPTY_VALUE);
}
}
}
}
//right outer join
else if(joinType.equalsIgnoreCase("rightouter")){
if(!listB.isEmpty()){
for(Text B: listB){
if(!listA.isEmpty()){
for(Text A: listA)
context.write(A, B);
}else {
context.write(EMPTY_VALUE, B);
}
}
}
}
//full outer join
else if(joinType.equalsIgnoreCase("fullouter")){
if(!listA.isEmpty()){
for (Text A : listA){
if(!listB.isEmpty()){
for(Text B : listB){
context.write(A, B);
}
}else {
context.write(A, EMPTY_VALUE);
}
}
}else{
for(Text B : listB)
context.write(EMPTY_VALUE, B);
}
}
//anti join
else if(joinType.equalsIgnoreCase("anti")){
if(listA.isEmpty() ^ listB.isEmpty()){
for(Text A : listA)
context.write(A, EMPTY_VALUE);
for(Text B : listB)
context.write(EMPTY_VALUE, B);
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 4)
{
System.err.println("params:<UserInDir> <CityInDir> <OutDir> <join Type>");
System.exit(1);
}
Job job = new Job(conf,"Reduce side join Job");
job.setJarByClass(ReduceJoin.class);
job.setReducerClass(JoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
MultipleInputs.addInputPath(job, new Path(otherArgs[0]), TextInputFormat.class, UserJoinMapper.class);
MultipleInputs.addInputPath(job, new Path(otherArgs[1]), TextInputFormat.class, CityJoinMapper.class);
FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
job.getConfiguration().set("join.type", otherArgs[3]);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.3 结果
执行语句:

inner join:
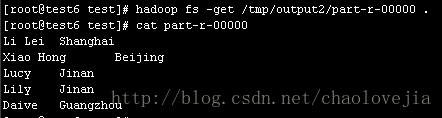
left outer join:

right outer join:

full outer join:

anti join:
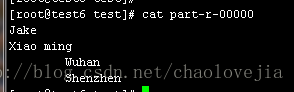














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









