







如果没有一个 map-side join 技术适合我们的数据集,那么就需要在 MapReduce 中使用 shuffle 来排序和连接两个数据集。这称为 reduce-side joins,也叫”重分区连接”。
【例】基本的重分区连接(repartition join/reduce-side join)
重分区连接是 reduce 端连接。它利用 MapReduce 的排序-合并机制来分组数据。它只使用一个单独的 MapReduce 任务,并支持 N-way join,这里 N 指的是被连接的数据集的数量。
Map 阶段负责从多个数据集中读取数据,决定用于每条记录的连接值,并将连接值作为输出 key。输出 value 则包含在 reduce 阶段所合并的数据集的数据。
Reduce 阶段,一个 reduce 接收 map 函数传来的每一个 join key 的所有输出值,并将数据分为 N 个分区,这里 N 指的是被连接的数量。在该 reducer 接收到用于该 join value 的所有输入记录并在内存中对 他们分区之后,它对所有分区执行一个笛卡尔积(Cartersian product),并输出每个 join 的结果。下图演示 了重分区 join:
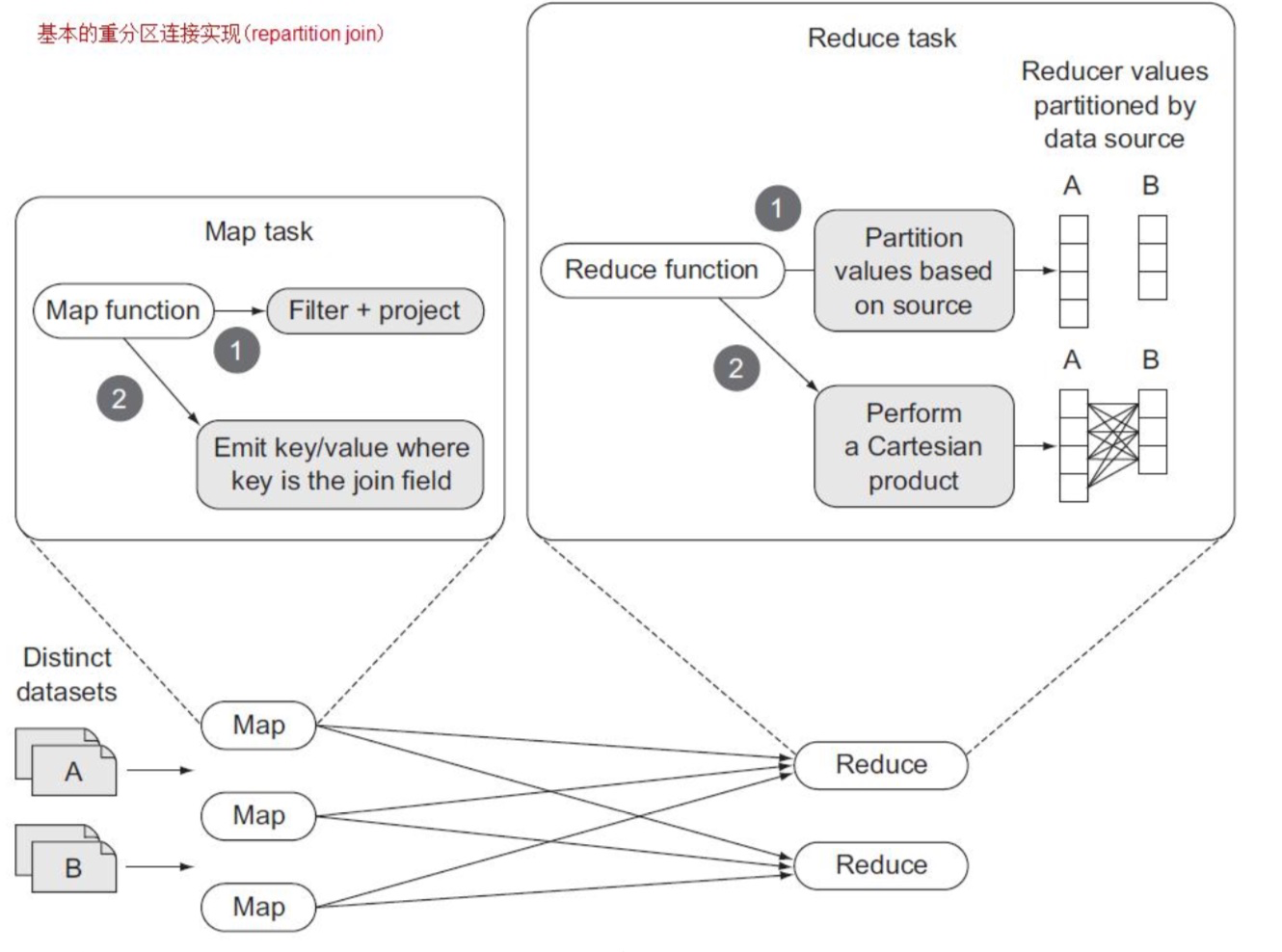 要支持这个技术,MapReduce 代码需要满足以下条件:
要支持这个技术,MapReduce 代码需要满足以下条件:
■它需要支持多个 map 类,每个 map 处理一个不同的输入数据集。这是通过使用 MultipleInputs 来 完成的。
■ 它需要一个方式来标记由 mapper 所输出的记录,这样它们才能与它们原始的数据集相关联。这 里我们将使用 htuple 项目来简化 MapReduce 中组合数据(composite data)的处理。
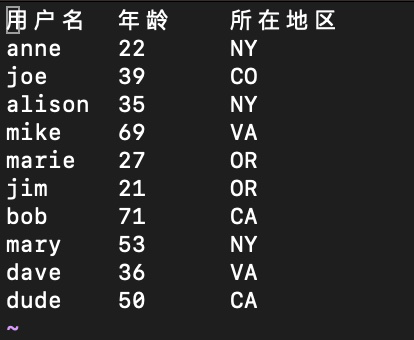
文件 users.txt:

package com.edu360.mapreduce;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* java 一出 谁与争锋
* <p>
* .............................................
* 佛祖保佑 永无BUG
*
* @Auther: caozhan
* @Date: 2018/11/4 13:11
* @Description:
*/
public class RepartitionJoin extends Configured implements Tool {
//声明代表不同数据表的标志变量
public static final int USERS=0;//代表记录来自用户信息表
public static final int USER_LOGS=1;//代表记录来自用户日志记录
//处理来自 users.txt的输入记录
public static class UserMap extends Mapper<LongWritable, Text,Text, TupleWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//提取用户名
String username = value.toString().split("\t")[0];
TupleWritable outputValue = new TupleWritable();
outputValue.setTable(USERS);
outputValue.setRecord(value.toString());
context.write(new Text(username),outputValue);
}
}
//处理来自logs.txt 的输入记录
public static class UserLogMap extends Mapper<LongWritable,Text,Text, TupleWritable>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//提取用户名
String username=value.toString().split("\t")[0];
TupleWritable outValue = new TupleWritable();
outValue.setTable(USER_LOGS);
outValue.setRecord(value.toString());
context.write(new Text(username),outValue);
}
}
public static class ReduceJoin extends Reducer<Text,TupleWritable,Text,Text>{
private List<String> users,userLogs;
private Text keyInfo = new Text();
private Text valueInfo = new Text();
@Override
protected void reduce(Text key, Iterable<TupleWritable> values, Context context)
throws IOException, InterruptedException {
users = new ArrayList<>();
userLogs=new ArrayList<>();
//解析从mapper收到的输入,分别放入相应的list集合中
for(TupleWritable tupleWritable:values){
System.out.println("Tuple:"+tupleWritable);
switch (tupleWritable.getTable()){
case USERS:{
users.add(tupleWritable.getRecord());
break;
}
case USER_LOGS:{
userLogs.add(tupleWritable.getRecord());
break;
}
}
}
//笛卡尔乘机
for(String user:users){
for(String userLog:userLogs){
keyInfo.set(user);
valueInfo.set(userLog);
context.write(keyInfo,valueInfo);
}
}
}
}
@Override
public int run(String[] args) throws Exception {
Path usersPath = new Path(args[0]);
Path userLogsPath = new Path(args[1]);
Path outputPath = new Path(args[2]);
Job job=Job.getInstance(getConf(),"Simple Redpartition Jii");
job.setJarByClass(ReduceJoin.class);
//分别为不同的输入文件指定不同的inputformat
MultipleInputs.addInputPath(job,usersPath, TextInputFormat.class,UserMap.class);
MultipleInputs.addInputPath(job,userLogsPath,TextInputFormat.class,UserLogMap.class);
job.setReducerClass(ReduceJoin.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(TupleWritable.class);
job.setOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job,outputPath);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
int res= ToolRunner.run(new RepartitionJoin(),args);
System.exit(res);
}
}
发生的ERRO:
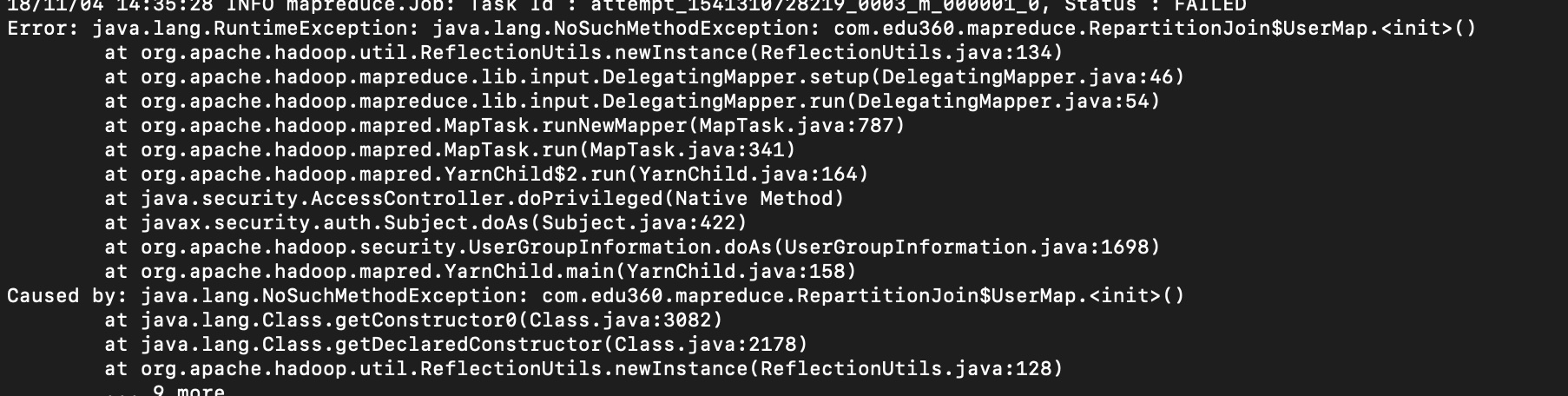
查看你的map和reduce 是不是没有被static修饰,拿不到实例类。
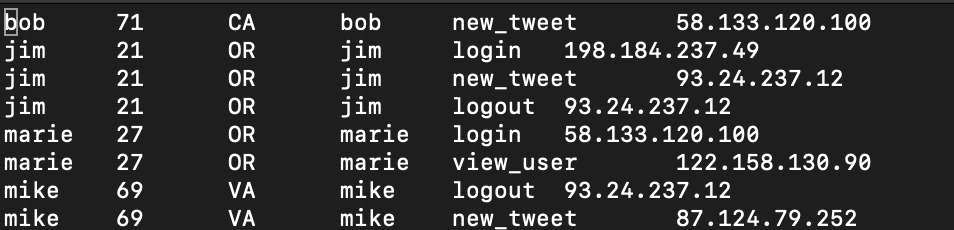
最终结果















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









