







IDEA中整合hadoop开发环境
前言:
hadoop程序运行在分布式环境下,运行调试MapReduce只需要对应的hadoop相应的依赖jar包就可以,下面以是在伪分布模式下hadoop程序的开发与调试IDEA环境的配置
环境:
- 操作系统:Ubuntu 16
- hadoop: hadoop-3.0.0-alpha2
- java: java 1.8
- IDEA:idea-IU-172.3317.76
新建项目:
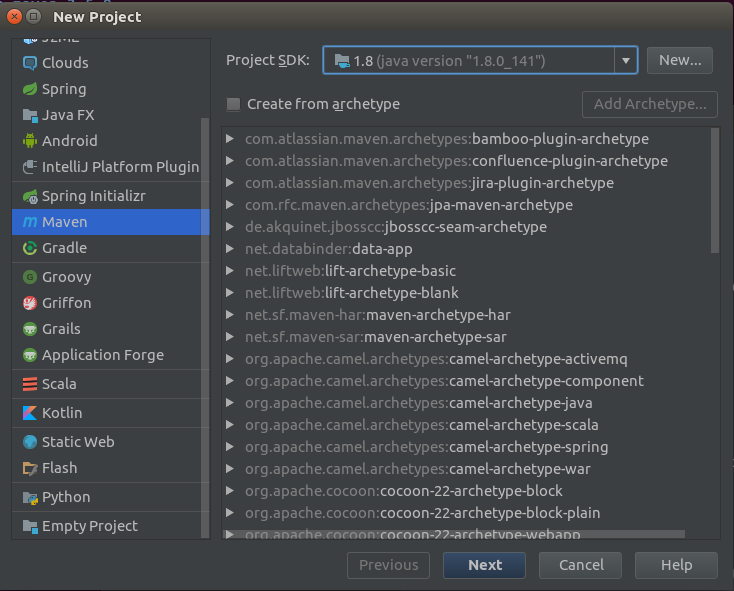
- Intellij中 File->New->Project 弹出的对话框中选择Maven,Project SDK 选择1.8,点击next
- GroupId 与 ArtifactId 根据自己的需求填写。然后点击next
I
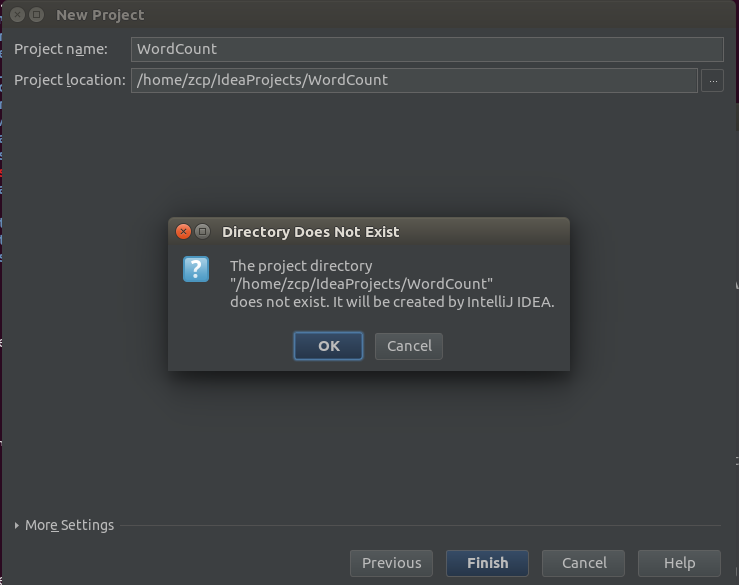
注:groupid和artifactId被统称为“坐标”是为了保证项目唯一性而提出的,如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。groupId 一般分为多个段,这里我只说两段,第一段为域,第二段为公司名称。域又分为org、com、cn等等许多,其中org为非营利组织,com为商业组织。举个apache公司的tomcat项目例子:这个项目的groupId是org.apache,它的域是org(因为tomcat是非营利项目),公司名称是apache,artigactId是tomcat。比如我创建一个项目,我一般会将groupId设置为cn.zcp,cn表示域为中国,zcp是我个人姓名缩写,artifactId设置为testProjectName,表示项 目名称。 - 填写项目名与项目位置 点击Finish弹出的确认框中点OK
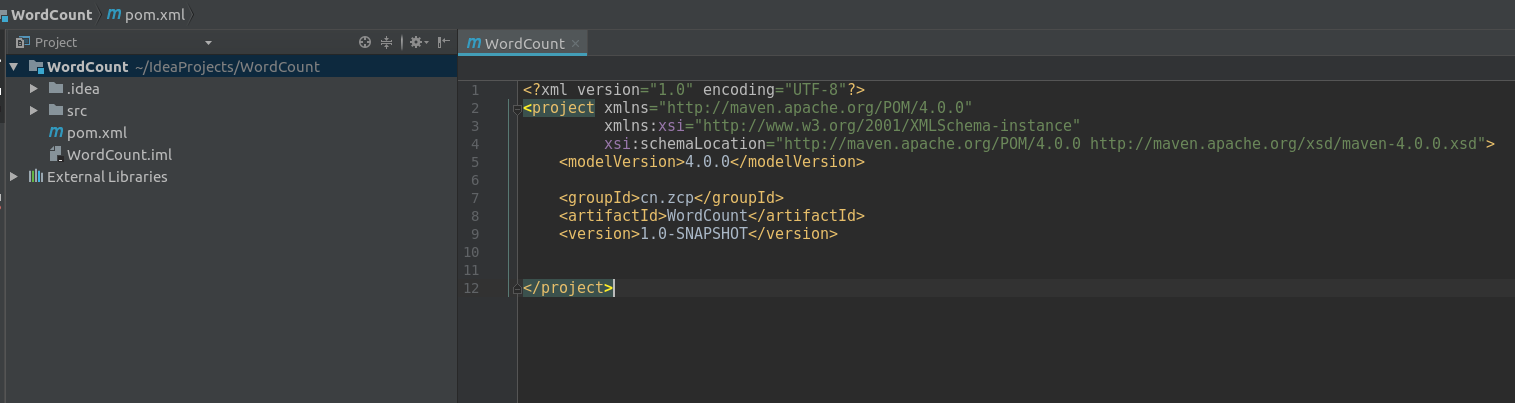
- 新建项目结构
-
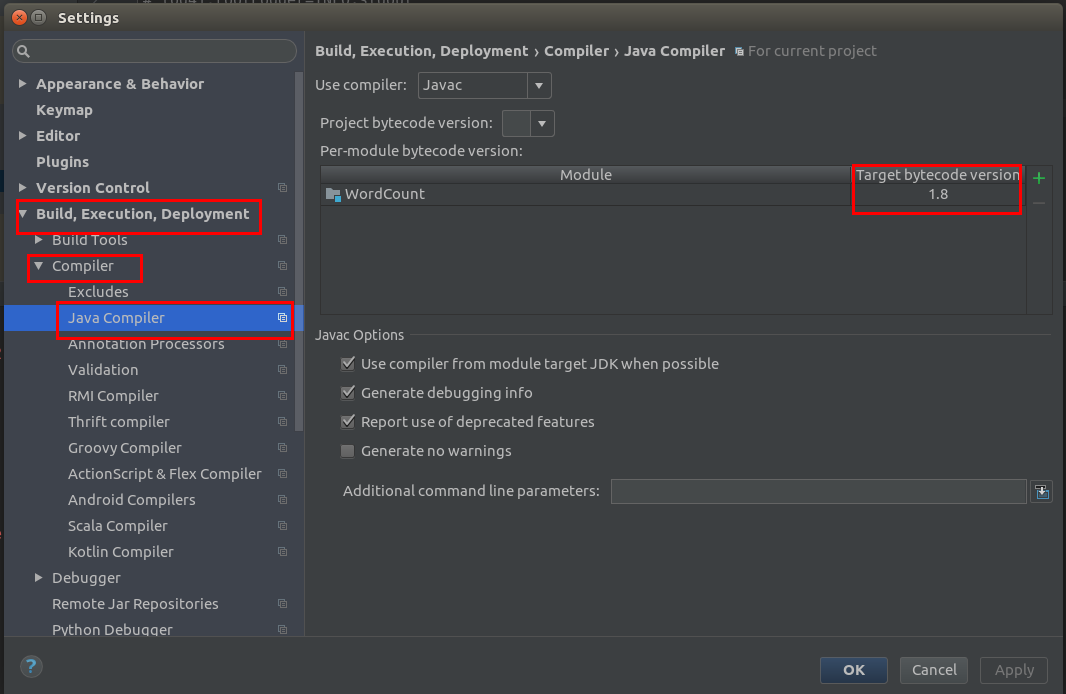
File->Settings 弹出对话框中将 将Target bytecode version 改为1.8
配置依赖包
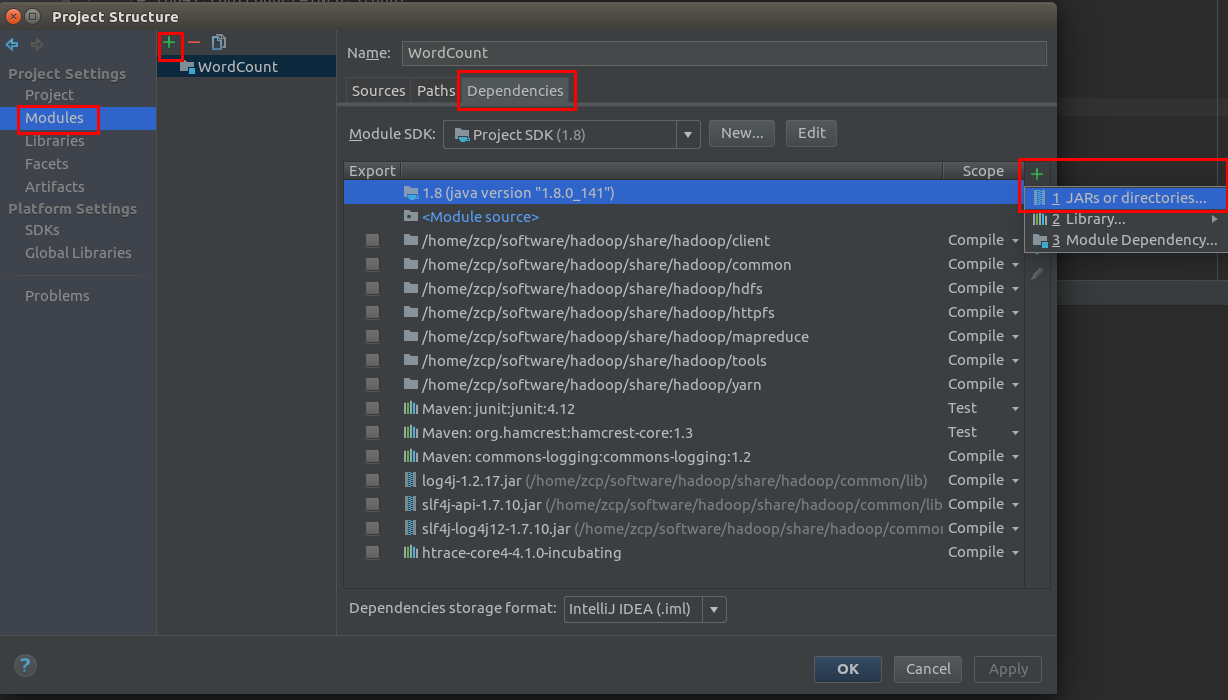
- 添加依赖的jar包:File->Project Structure 中弹出的对话中选择Modules点击"+" 选择新建的项目,切到Dependencies的 选择 + JARs or directories部分。注:hadoop的依赖包都在安装包中的 share/hadoop,但是这个不能直接添加 share/hadoop 目录,添加的目录只能是jar所在的目录,如xx.jar所在的路径经 /share/hadoop/common/lib/xx.jar 添加 /share/hadoop/common/lib 正确, /share/hadoop/common 则无法找到xx.jar包。
-
不添加目录时可以配置pom.xml,IDEA会自动下载配置的jar
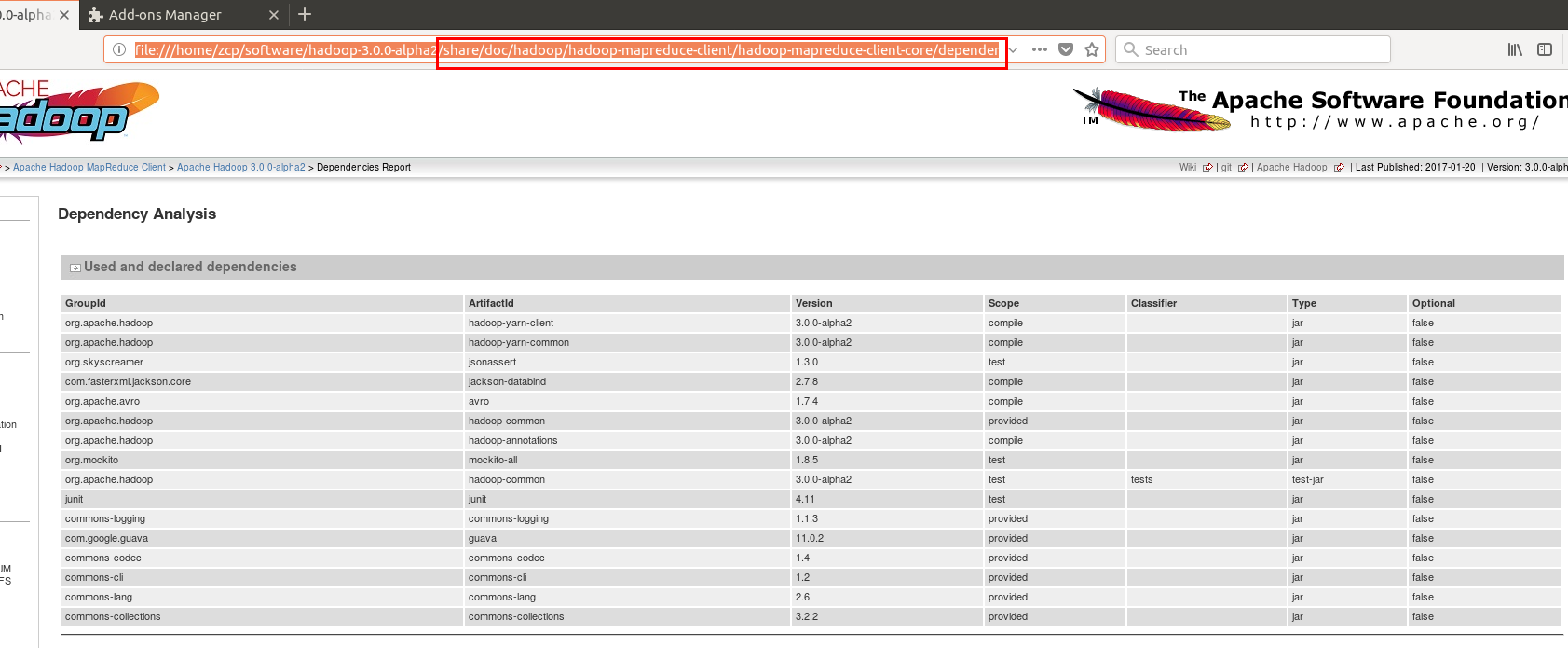
注:不清楚groupId artifactId version 这三个部分填写的,可以参考 hadoop p安装包中的帮助 文档 share/doc/hadoop/hadoop-mapreduce-client/hadoop-mapreduce-client-core/dependency-analysis.html.
-
src->main->java 新建 java程序,WordCount 粘贴官网中的代码
打包程序:
-
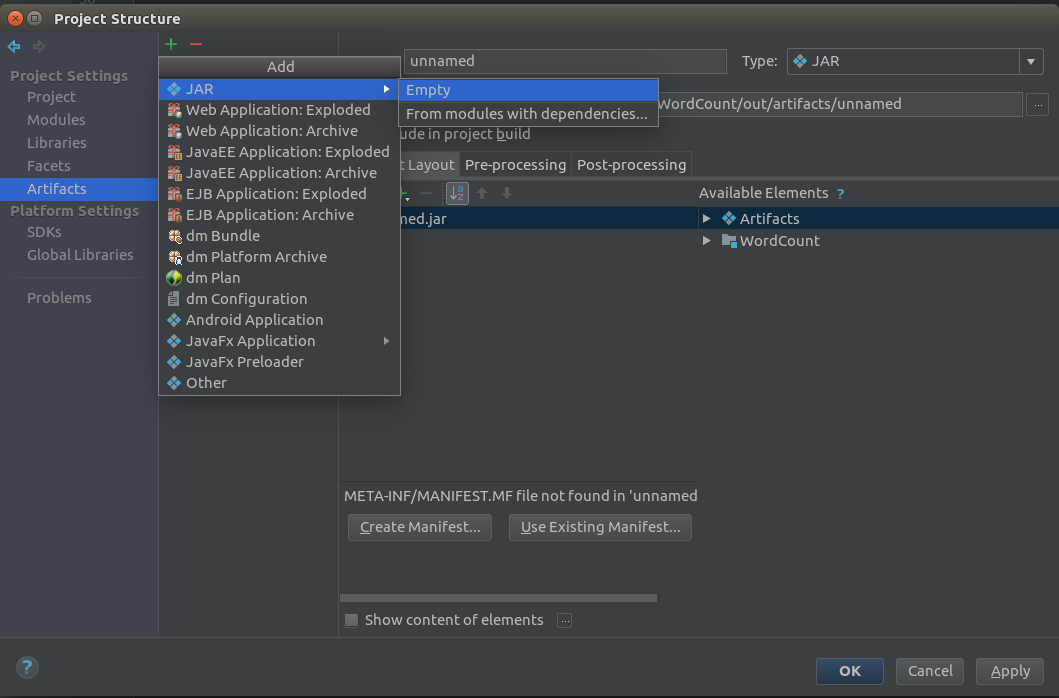
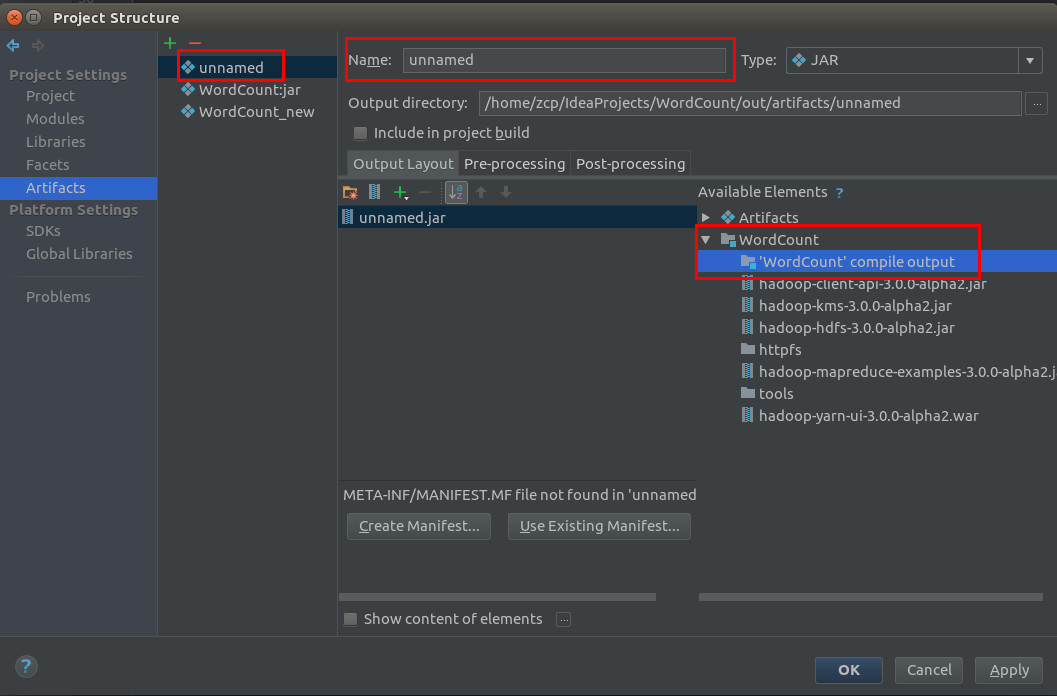
File->Project Structure 中选择 Artifacts 点击 ”+“ 选择 JAR->EmptyName 是需要打包的名称,在Available Elements中选择需要打包内容。
-
编译生成jar
-
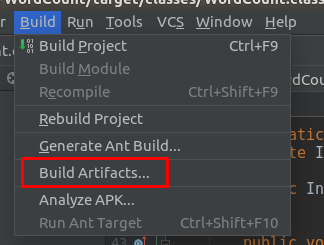
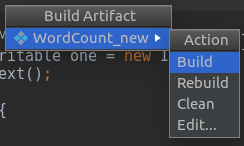
Build->Build Artifacts 弹出的对话框中选择Build
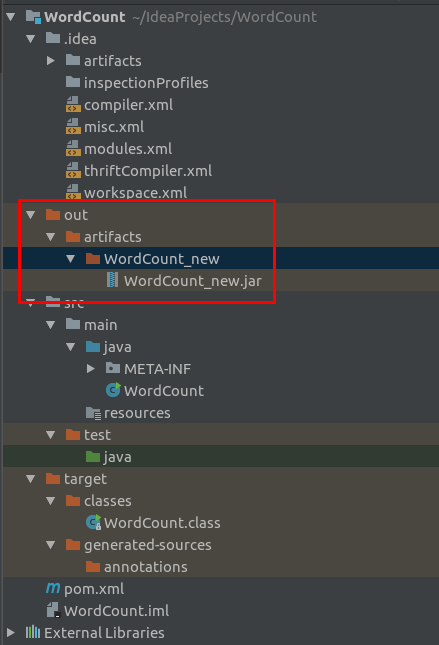
- 编译无错误时,在工程中会现out目录,在此目录中会生成编译成功的jar文件。可自行测试
在IDEA中运行MapReduce程序
-
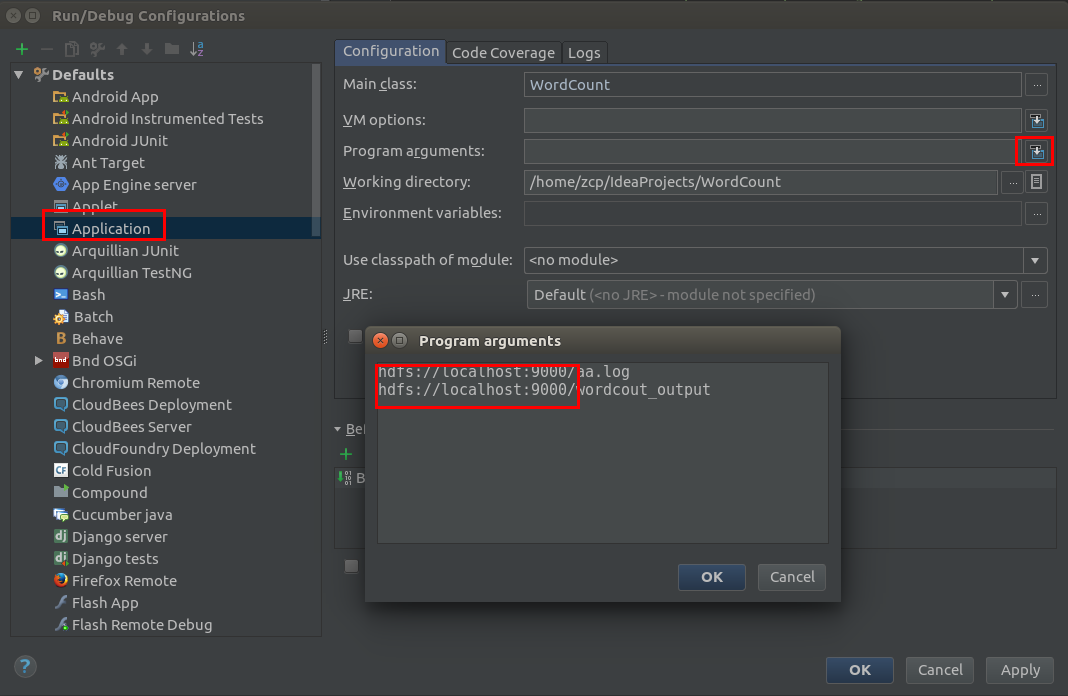
Run->Edit Configurations在弹出的对话框 选择Application,在Program arguments中输入程序所需要的运行参数注:远程调试代码 必须写上hdfs://localhost:9000部分,不然此处将识别为本地路径。hdfs://localhost:9000/aa.log hdfs://localhost:9000/wordcout_output
-
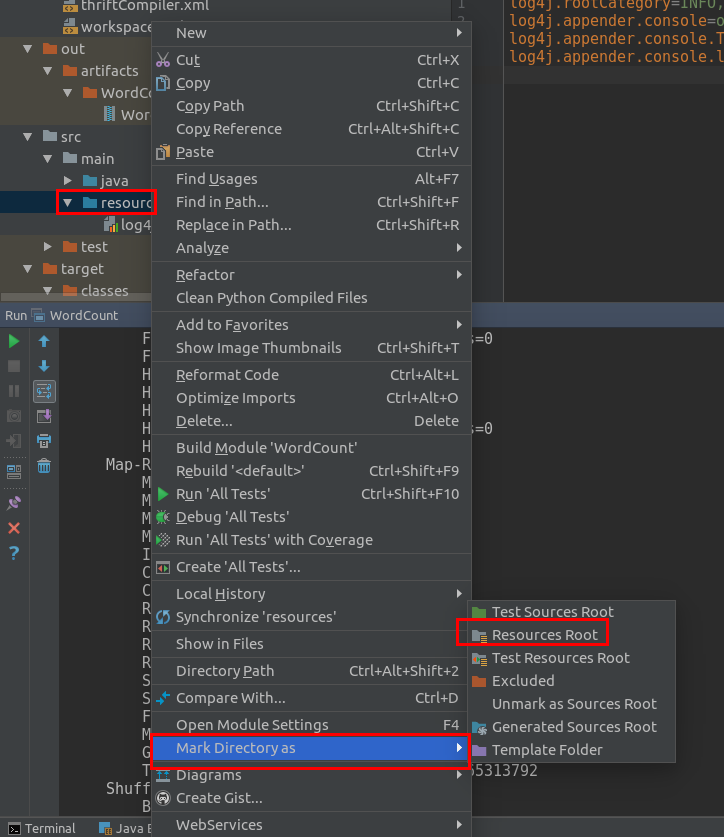
idea console中输出运行日志。默认条件下console只输出error 与fatal级别的log在src中目录中右击resources 选择 Mark Directory as 中 选中Resources Root在resources中新建log4j.properties文件。仿照 hadoop按装包中的 /conf/log4j.properties.template输入配置# set everything to be logged to the consolelog4j.rootCategory=INFO, consolelog4j.threshold=ALLlog4j.appender.console=org.apache.log4j.ConsoleAppenderlog4j.appender.console.target=System.errlog4j.appender.console.layout=org.apache.log4j.PatternLayoutlog4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
-
点击Run->Run 程序可以直接运行















 1229
1229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









