







在寻找知识图谱项目的时候发现很多都特别大的工程,完全不能让一个人搞懂,今天给大家分享下智能法务项目,该项目是基于 NLP 的知识图谱构建项目.能完成如下功能:

相关源码 http://pan.baidu.com/share/link?shareid=1208960088&uk=873411533
如遇失效请再评论区留言
1, 以罪名为核心,收集相关数据,建成基本的罪名知识图谱,法务资讯对话知识库,案由量刑知识库.
2, 分别基于步骤1的结果,完成以下四个方面的工作:
-
基于案由量刑知识库的罪名预测模型
-
基于法务咨询对话知识库的法务问题类型分类
-
基于法务咨询对话知识库的法务问题自动问答服务
-
基于罪行知识图谱的知识查询
目前知识图谱在各个行业中应用逐步打开,尤其在金融,医疗,法律,旅游方面.知识图谱助力法律智能,能够在一定程度上利用现有大数据以及机器学习/深度学习与自然语言处理技术,提供一些智能的解决方案.
罪名法务智能项目,内容包括856项罪名知识图谱, 基于280万罪名训练库的罪名预测,基于20W法务问答对的13类问题分类与法律资讯问答功能.
罪名预测
1, 问题类型: 罪名一共包括202种罪名,文件放在dict/crime.txt中, 详细内容举例如下:

2, 问题模型: 罪刑数据库一共有288万条训练数据,要做的是202类型的罪名多分类问题.本项目采用的方式为:

3, 效果: 执行 python crime_classify.py
Skip to content
Search or jump to…
Pull requests
Issues
Marketplace
Explore
@chaoren399
14
319 108 liuhuanyong/CrimeKgAssitant
Code Issues 6 Pull requests 0 Projects 0 Wiki Security Insights
CrimeKgAssitant/crime_classify.py
@liuhuanyong liuhuanyong 添加自动问答模块
9f9cbf7 on Nov 11, 2018
102 lines (87 sloc) 3.14 KB
#!/usr/bin/env python3
# coding: utf-8
# File: crime_classify.py.py
# Author: lhy<lhy_in_blcu@126.com,https://huangyong.github.io>
# Date: 18-11-11
import os
import numpy as np
import jieba.posseg as pseg
from sklearn.externals import joblib
class CrimeClassify(object):
def __init__(self):
cur = '/'.join(os.path.abspath(__file__).split('/')[:-1])
crime_file = os.path.join(cur, 'dict/crime.txt')
self.label_dict = self.build_crime_dict(crime_file)
self.id_dict = {j:i for i,j in self.label_dict.items()}
self.embedding_path = os.path.join(cur, 'embedding/word_vec_300.bin')
self.embdding_dict = self.load_embedding(self.embedding_path)
self.embedding_size = 300
self.model_path = 'model/crime_predict.model'
return
'''构建罪名词类型'''
def build_crime_dict(self, crimefile):
label_dict = {}
i = 0
for line in open(crimefile):
crime = line.strip()
if not crime:
continue
label_dict[crime] = i
i +=1
return label_dict
'''加载词向量'''
def load_embedding(self, embedding_path):
embedding_dict = {}
count = 0
for line in open(embedding_path):
line = line.strip().split(' ')
if len(line) < 300:
continue
wd = line[0]
vector = np.array([float(i) for i in line[1:]])
embedding_dict[wd] = vector
count += 1
if count%10000 == 0:
print(count, 'loaded')
print('loaded %s word embedding, finished'%count, )
return embedding_dict
'''对文本进行分词处理'''
def seg_sent(self, s):
wds = [i.word for i in pseg.cut(s) if i.flag[0] not in ['x', 'u', 'c', 'p', 'm', 't']]
return wds
'''基于wordvector,通过lookup table的方式找到句子的wordvector的表示'''
def rep_sentencevector(self, sentence, flag='seg'):
if flag == 'seg':
word_list = [i for i in sentence.split(' ') if i]
else:
word_list = self.seg_sent(sentence)
embedding = np.zeros(self.embedding_size)
sent_len = 0
for index, wd in enumerate(word_list):
if wd in self.embdding_dict:
embedding += self.embdding_dict.get(wd)
sent_len += 1
else:
continue
return embedding/sent_len
'''对数据进行onehot映射操作'''
def label_onehot(self, label):
one_hot = [0]*len(self.label_dict)
one_hot[int(label)] = 1
return one_hot
'''使用svm模型进行预测'''
def predict(self, sent):
model = joblib.load(self.model_path)
represent_sent = self.rep_sentencevector(sent, flag='noseg')
text_vector = np.array(represent_sent).reshape(1, -1)
res = model.predict(text_vector)[0]
label = self.id_dict.get(res)
return label
def test():
handler = CrimeClassify()
while(1):
sent = input('crime desc:')
label = handler.predict(sent)
print('crime label:', label)
if __name__ == '__main__':
test()
© 2019 GitHub, Inc.
Terms
Privacy
Security
Status
Help
Contact GitHub
Pricing
API
Training
Blog
About
法务咨询问题分类
1, 问题类型: 法务资讯问题一共包括13类,详细内容如下:

2, 问题模型: 法务咨询数据库一共有20万条训练数据,要做的是13类型咨询问题多分类问题.本项目采用的方式为:
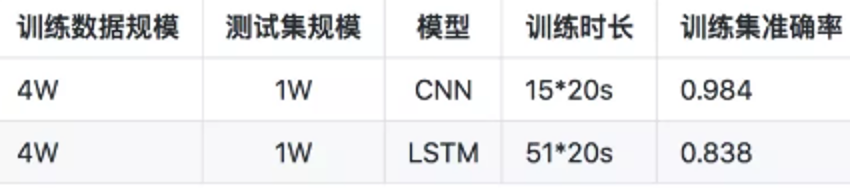
3, 效果: 执行 python question_classify.py
question:朋友欠钱不还咋办
answers: ['欠款金额是多少 ', '多少钱呢', '律师费诉讼费都非常少都很合理,一定要起诉。', '大概金额多少?', '需要看标的额和案情复杂程度,建议细致面谈']
*******************************************************
question:昨天把人家车刮了,要赔多少
answers: ['您好,建议协商处理,如果对方告了你们,就只能积极应诉了。', '您好,建议尽量协商处理,协商不成可起诉']
*******************************************************
question:最近丈夫经常家暴,我受不了了
answers: ['报警要求追究刑事责任。', '您好,建议起诉离婚并请求补偿。', '你好!可以起诉离婚,并主张精神损害赔偿。']
*******************************************************
question:毕业生拿了户口就跑路可以吗
answers: 您好,对于此类问题,您可以咨询公安部门
*******************************************************
question:孩子离家出走,怎么找回来
answers: ['孩子父母没有结婚,孩子母亲把孩子带走了?这样的话可以起诉要求抚养权的。毕竟母亲也是孩子的合法监护人,报警警察一般不受理。']
*******************************************************
question:村霸把我田地给占了,我要怎么起诉
answers: ['可以向上级主管部门投诉解决', '您好,您可以及时向土地管理部门投诉的!', '对方侵权,可以向法院起诉。', '你好,对方侵权,可以向法院起诉。', '你好,可起诉处理,一、当事人起诉,首先应提交起诉书,并按对方当事人人数提交相应份数的副本。当事人是公民的,应写明双方当事人的姓名、性别、年龄、籍贯、住址;当事人是单位的,应写明单位名称、地址、法定代表人或负责人姓名。起诉书正文应写明请求事项和起诉事实、理由,尾部须署名或盖公章。二、根据"谁主张谁举证"原则,原告向法院起诉应提交下列材料:1、原告主体资格的材料。如居民身份证、户口本、护照、港澳同胞回乡证、结婚证等证据的原件和复印件;企业单位作为原告的应提交营业执照、商业登记证明等材料的复印件。2、证明原告诉讼主张的证据。如合同、协议、债权文书(借条、欠条等)、收发货凭证、往来信函等。', '您好,起诉维权。', '您好,可以起诉解决。']
*******************************************************
question:售卖危违禁物品,有什么风险
answers: ['没什么']
*******************************************************
question:找不到女朋友啊..
answers: 您好,对于此类问题,您可以咨询公安部门
*******************************************************
question:我要离婚
answers: ['现在就可向法院起诉离婚。', '不需要分开两年起诉离婚。感情完全破裂就可以提起诉讼离婚。', '你可以直接起诉离婚', '直接起诉']
*******************************************************
question:醉驾,要坐牢吗
answers: ['要负刑事责任很可能坐牢', '由警方处理.,']
*******************************************************
question:你好,我向大学提出退学申请,大学拒绝,理由是家长不同意。我该怎么办?
answers: ['自己可决定的 ']
*******************************************************
question:请问在上班途中,出车祸我的责任偏大属于工伤吗?
answers: ['属于工伤']
*******************************************************
question:结婚时女方拿了彩礼就逃了能要回来吗
answers: ['可以要求退还彩礼。,']
*******************************************************
question:房产证上是不是一定要写夫妻双方姓名
answers: ['可以不填,即使一个人的名字,婚后买房是共同财产。', '不是必须的', '可以写一方名字,对方公证,证明该房产系你一人财产', '你好,不是必须']
*******************************************************
question:儿女不履行赡养义务是不是要判刑
answers: ['什么情况了?']
*******************************************************
question:和未成年人发生关系,需要坐牢吗
answers: ['女孩子在发生关系的时候是否满14周岁,如果是且自愿就不是犯罪', '你好,如果是双方愿意的情况下是不犯法的。', '发生性关系时已满十四岁并且是自愿的依法律规定不构成强奸罪,不构成犯罪的。', '若是自愿,那就没什么可说了。', '双方愿意不犯法', '你好 如果是自愿的 不犯法 ', '自愿的就没事']
*******************************************************
question:撞死人逃跑要怎么处理
answers: ['等待警察处理。,']
法务咨询自动问答
运行 python crime_qa.py
总结
1, 本项目实现的是以罪刑为核心的法务应用落地的一个demo尝试.
2, 本项目采用机器学习,深度学习的方法完成了罪名预测,客服问句类型预测多分类任务,取得了较好的性能,模型可以直接使用.
3,本项目构建起了一个20万问答集,856个罪名的知识库,分别存放在data/kg_crime.json和data/qa_corpus.json文件中.
4, 法务问答,可以是智能客服在法律资讯网站中的一个应用场景落地. 本项目采用的是ES+语义相似度加权打分策略实现的问答技术路线, 权值计算与阈值设定可以用户指定.
5, 对于罪名知识图谱中的知识可以进一步进行结构化处理,这是后期可以完善的地方.
6, 如何将罪名,咨询,智能研判结合在一起,形成通路,其实可以进一步提升知识图谱在法务领域的应用.

















 8253
8253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









