






题目一
给定一个全是小写字母的字符串str.删除多余字符,使得每种字符只保留一个,并让最终结果字符串的字典序最小
str= "acbc", 删掉第一个c, 得到"abc", 是所有结果字符串中字典序最小的。str = "dbcacbca", 删掉第一个b'、 第一个'c'、 第二个c、第二个'a", 得到"dabc",是所有结果字符串中字典序最小的。
删除多余的 和保留该保留的是一致的
首先我们要知道 假如我们要选第一个字符 那么这个字符的后面 一定要包含所有的其他字符 要不然选了这个字符之后 剩下的字符无法满足条件
比如说
dcacadbbacdbcacb 我们第一个字符一定会在红色部分挑出有如果我们把b选为第一个字符 那么后面就没有d了 就选不了了 对应到coding中就是如果当前位置后面没有这个元素了 那它就是选择第一个字符的区间(R边界)
然后我们在这个范围之中选择字典序最小的作为它的第一个字符
那第二个字符选择在哪呢 首先它肯定会在第一个字符之后(就是L边界) 且要保证他后面除了第一个字符和当前选择的字符都有至少一个 在这个范围内选择字典序最小的字符
最后当R来到结尾的时候 一般就是说 当这个字符已经取了往下看 当这个字符不是最后一个往下看
也就是说 所有字符都已经被取过了
coding及其变态 注释比代码长
public static String removeDuplicateLetters2(String s) {
char[] str = s.toCharArray();
// 小写字母ascii码值范围[97~122],所以用长度为26的数组做次数统计
// 如果map[i] > -1,则代表ascii码值为i的字符的出现次数
// 如果map[i] == -1,则代表ascii码值为i的字符不再考虑
int[] map = new int[26];//桶排序
for (int i = 0; i < str.length; i++) {
map[str[i] - 'a']++;
}
char[] res = new char[26];//最多二十六个
int index = 0;
int L = 0;
int R = 0;
while (R != str.length) {
// 如果当前字符是不再考虑的,直接跳过
// 如果当前字符的出现次数减1之后,后面还能出现,直接跳过
if (map[str[R] - 'a'] == -1 || --map[str[R] - 'a'] > 0) {
R++;//右边界只会越来越右 所以一直推就可以了 并不是这个意思 只是每次都把右边界置为左边界了而已
} else { // 当前字符需要考虑并且之后不会再出现了
// 在str[L..R]上所有需要考虑的字符中,找到ascii码最小字符的位置
int pick = -1;
for (int i = L; i <= R; i++) {//注意这里是<= L可以等于R
if (map[str[i] - 'a'] != -1 && (pick == -1 || str[i] < str[pick])) {//!=-1 代表着没被置为无效 pick等于-1代表着没挑选过表示最开始它还没有指定任何一个值
pick = i;
}
}
// 把ascii码最小的字符放到挑选结果中
res[index++] = str[pick];
// 在上一个的for循环中,str[L..R]范围上每种字符的出现次数都减少了
// 需要把str[pick + 1..R]上每种字符的出现次数加回来
for (int i = pick + 1; i <= R; i++) {//减少是为了看后面还有没有了 如果没有了 就要在这停顿 也就是说只是拿它判断而已 现在判断完要复原 从L开始减的 就从L开始恢复 我们在结尾的时候 把R置成L了
if (map[str[i] - 'a'] != -1) { // 只增加以后需要考虑字符的次数
map[str[i] - 'a']++;
}
}
// 选出的ascii码最小的字符,以后不再考虑了
map[str[pick] - 'a'] = -1;
// 继续在str[pick + 1......]上重复这个过程
L = pick + 1;
R = L;//R=L 就是重新从L开始往下扩
}
}
return String.valueOf(res, 0, index);//直接tostring是会出空格的
}1.如果这个pick+1 换成L会报错
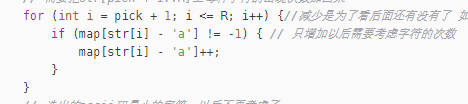
我当时的想法是 我从L开始加回去 多加一个没问题 反正不看的部分加了也就加了
但是 这个看的不是str 看的是map如果你多加了 就会导致这个范围的某个元素数量比实际的多
那为什么L和pick+1部分之间的不用管了呢 因为这里得从str里面看 我们之前不看的地方已经完全减掉了 只要新加我们要看的 就能对上了
2.这里的-1的作用是什么 是如果第一次判断直接把pick赋值 我改成L不行吗

改成这样呢

此时L = 7 R = 10 pick在L的位置上 这时候按照原本的逻辑不应该给他赋值得往下找第一个符合条件的才行 所以还是得-1 如果找到合适条件了再给他赋值 哎 会不会一直不符合条件啊 不会 如果都不符合那R直接走到底了
所以梳理一下流程 R先扩 直到一个位置 这个位置后面有某个元素没有了 那么一定会在这个位置取第一个元素 取了第一个元素之后 第二个元素应该从这个元素位置之后开始取 这个就是取下一个元素区间的左边界 那右边界怎么看 还是说某个元素在这之后就没有了 但是这个已经取完的元素有没有就无所谓 然后一直这么循环 直到我的右边界能扩到最后了 这说明什么 我的R一直阔 阔到最后一个元素都没停下来 这个最后的元素 一定是已经出现过一次的了 如果没有出现过 那么R就会在这个最后的元素处停下来 也就是说所有元素都已经出现过一次了
题目二
一个数组中,如果两个数的最小公共因子大于1,则认为这两个数之间有通路返回数组中,有多少个独立的域
肯定是并查集 那么连接条件是什么呢
最暴力的方法是遍历所有元素看看能不能形成通路
优化一点呢做一个MAP 保存所有质数因子 如果包含此质数因子可以连在一起这样的话 复杂度就是O(N*V) 如果V的范围不大的话 可以用这个方法 (这个V是 啊 这个给的参数的情况 要是Integer.max就还不如用原来的了)
更优化呢
对于一个数 每个公因数都是一组一组的对吧 比如说18的公因数(1,18)(2,9)(3,6)对吧 我们对于每一组来说 只需要找第一个 那么第二个就出来了 这个分界线就是根号这个数 如果把这个分界线之前的数都找过一次了 那么所有的对 都找过了
class unionfind{
HashMap<Integer, Integer> size = new HashMap<Integer, Integer>();
HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
int date [];
public void init(int [] arr) {
for (int i : arr) {
father.put(i, i);
size.put(i, 1);
}
date = arr;
}
public void union(int num1,int num2) {
if(num1==num2) {
return;
}
int fa1 = getfather(num1);
int fa2 = getfather(num2);
if(fa1!=fa2) {
int big = size.get(fa1)>size.get(fa2)?fa1:fa2;
int small = big==fa1?fa2:fa1;
int bigsize = size.get(big);
int smallsize = size.get(small);
size.put(big,bigsize+smallsize);
size.remove(small);
father.put(small,big);
}
}
public int getfather(int num) {
Stack<Integer> stack = new Stack<Integer>();
while(father.get(num)!=num) {
stack.push(num);
num = father.get(num);
}
while(!stack.isEmpty()) {
father.put(stack.pop(),num);
}
return num;
}
public boolean issame(int num1,int num2) {
return father.get(num1)==father.get(num2);
}
public int maxSize() {
int max = 0;
int cur = 0;
for (int i : date) {
cur = size.get(getfather(i));
max = Math.max(cur, max);
}
return max;
}
}
public static int largestComponentSize(int[] nums) {
unionfind union = new unionfind();
union.init(nums);
int limit = 0;
HashMap<Integer, Integer> fatorsMap = new HashMap<>();
for(int i = 0;i<nums.length;i++) {
int num = nums[i];
limit = (int)Math.sqrt(num);
for(int j = 1;j<=limit;j++) {
if (num % j == 0) {
if (j != 1) {
if (!fatorsMap.containsKey(j)) {
fatorsMap.put(j, i);
} else {
union.union(nums[fatorsMap.get(j)], num);
}
}
int other = num / j;//这边也同理
if (other != 1) {
if (!fatorsMap.containsKey(other)) {
fatorsMap.put(other, i);
} else {
union.union(nums[fatorsMap.get(other)], num);
}
}
}
}
}
return union.maxSize();
}题目三
给定两个数组arrx和arry.长度都为N。代表二维平面上有N个点,第i个点的x
坐标和y坐标分别为arrx[]和arry[],返回求一条 直线最多能穿过多少个点?
两个点的关系
1.同x
2.同y
3.重合(既同x又同y)
4.能用斜线连在一起
那么对于a这个点来说
1.有多少个点与a重合
2.same y数量
3same x数量
4.来一个表 看共斜率的 共的点有多少个
情况1+每种情况 都是并列的 我们从这几种情况中取一个最大的
假如说有 a b c d e f
点 我们只需要从a往后看
从b往后看
从c往后看
以此类推 前面的不需要看 因为如果c真的有一条线的最长结果包括a 那么我们在处理a的结果的时候已经看过了(一个贪心)
这是这个业务的特殊性决定的 如果真的 它包含前面的结果 那就说明他们共线 那如果共线了 那后面的结果 就是前面的结果 所以实际上我们是这么考虑的 如果答案包含前面的点 那就说明共线 共线就一定是之前的结果 不需要更新结果用之前的就行 因为此点的答案肯定比前面的答案要小 如果不共线呢 那不需要前面的点作为结果 直接看后面就行
还说一个问题 就是我们如果直接用y1-y2/x1-x2 会有一个精度损耗
即使你用小数也一样会有精度损耗 你想啊 它会在某位被截断 那么后面的某些位不一致了 你也不知道
除法有问题 所以我们直接用分数表示 用最大公约数给他们约分了之后 保存成字符串的形式
比如三分之一 和 三百分之一百 就都是三分之一
本来会出现精度损耗的 比如(9,10) 和 (0,0) (0,1) 求出斜率都是一 但是他们其实一个斜率是10/9和9/9(小数同理 例子不好找 不再赘述)
顺便说下 如果这样判断的话 那就是-1/3 1/-3 就是判定为不同 所以要注意负数
这个求最大公约数方法 如果a为负数 就会返回负 如果b为负数就会返回正
就可以把x y维持在x 正 y负
public static int largestComponentSize(Point[] points) {
if (points == null) {
return 0;
}
if (points.length <= 2) {
return points.length;
}
HashMap<Integer, HashMap<Integer, Integer>> map = new HashMap<Integer, HashMap<Integer,Integer>>();
int res = 0;
for(int i = 0;i<points.length;i++) {
map.clear();
int samex = 0;
int samey = 0;
int samepoint = 1;
int line = 0;
for(int j = i+1;j<points.length;j++) {
int x = points[i].x - points[j].x;
int y = points[i].y - points[j].y;
if(x==0&&y==0) {
samepoint++;
}
else if(x==0) {
samex++;
}
else if(y==0) {
samey++;
}
else{
int gcd = gcd(x, y);
x /= gcd;
y /= gcd;
if(!map.containsKey(x)) {
map.put(x, new HashMap<Integer, Integer>());
}
if(!map.get(x).containsKey(y)) {
map.get(x).put(y,0);
}
map.get(x).put(y, map.get(x).get(y) + 1);
line = Math.max(line, map.get(x).get(y));
}
}
res = Math.max(res, Math.max(Math.max(samex, samey), line) + samepoint);//这个samepoint 一定会加 最差情况也会包含它自己本身
}
return res;
}
public static int gcd(int a, int b) {
return b == 0 ? a : gcd(b, a % b);
}














 2629
2629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









