







跳表概念
跳表:一种解释是一种多层的有序链表,在链表基础上结合二分的思想,把改造后的数据结构叫做跳表。另一种解释是一种概率平衡,而不是严格平衡的二叉树。有序链表更容易理解,平衡树更形象。
跳表需要建立索引,使用空间换时间的思想,通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集,所以跳表的索引查找和平衡树差不多,插入和删除算法比平衡树更简单。
跳表的数据结构
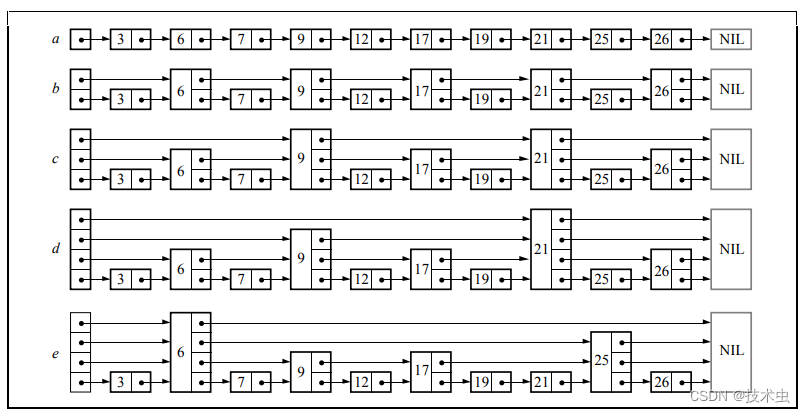
跳表特性分析
1 . 跳表的本质是一个多层的有序链表,同时结合二分查找的思想;
2. 跳表由很多层索引组成,每一层索引是通过随机函数随机产生的,每一层都是一个有序的链表,默认是升序 ;
3. 底层链表包含所有元素;
4. 如果一个元素出现在第i层链表中,那么在第i层下的链表也会出现;
5. 跳表的每个节点包含两个指针,一个指向有序链表下一节点,一个指向下一层相同节点。
综上所述,跳表相比有序链表,需要建立很多索引节点,会占用额外内存开销。所以当数据量比较大时内存的消耗相比时间查找的优化可以忽略不计。
跳表相比红黑树,内存占用开销差不多,查询效率也差不多,但是有几点差异:
1. 跳表实现更简单,不需要旋转节点和着色,插入删除效率更高;
2. 跳表范围查找效率高于红黑树,跳表从上层往下层查找,跳表的上层可以快速查询到指定范围;
3. 跳表通过随机函数创建索引,在极端情况下可能会出现退化成有序链表情况。
跳表实现原理
1. 查询数据
假设链表上有序数据为【9,11,14,19,20,24,27】,如果我要查找的数据是20,只能从头结点沿着链表依次比较查找。

借鉴数组的思路,顺着指针的方向,使用二分查找快速查询,类似书本上目录和子目录一样,找到每个章节对应的内容。这样我们可以根据索引目录,先找到对应章节,再找到对应的内容。
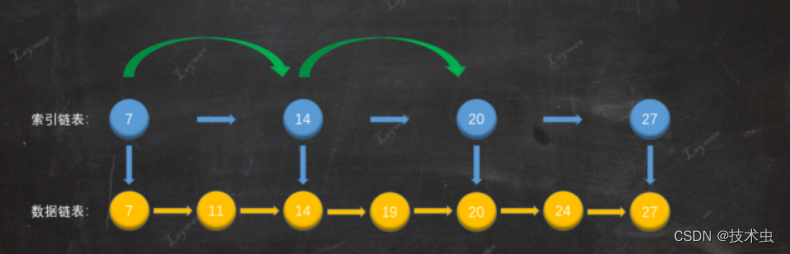
两级索引还是比较慢,可以建立多级索引目录;直到最高层只有两张目录。
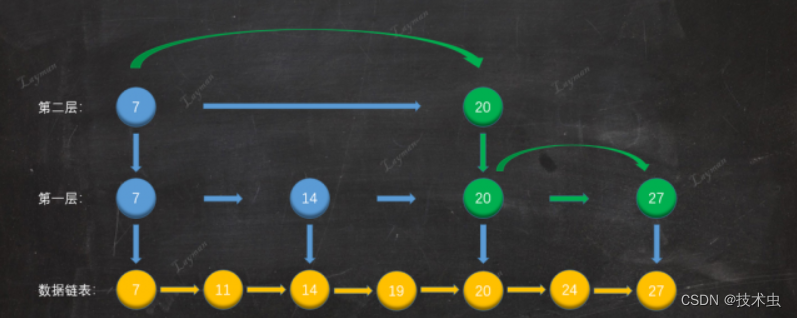
2. 插入数据
1. 找到插入数据的前置节点,小于待插入节点18
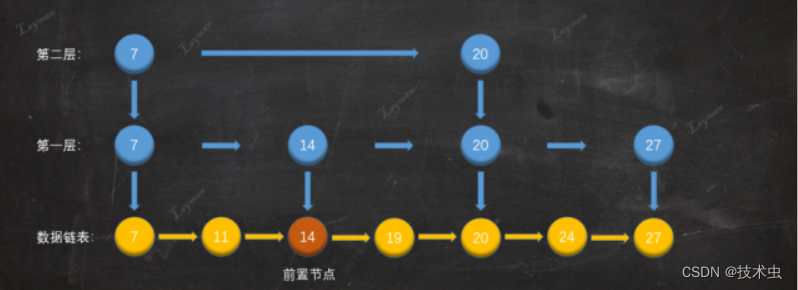
2. 插入原始链表
插入原始链表中,插入操作并没有结束。新插入节点随机晋升,抛硬币的方式,创建索引节点,跳表也被称为随机化的数据结构。
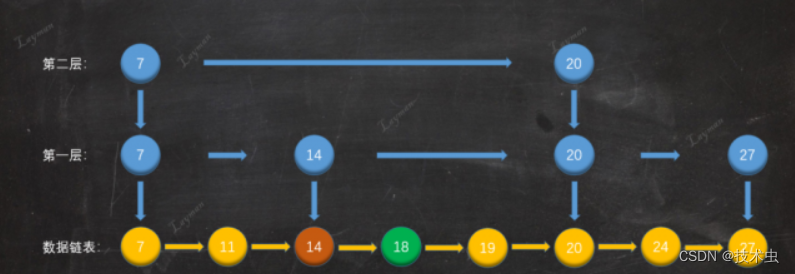
3. 创建索引节点
假设第一二次随机结果都要创建索引节点,并且向下指向原始相同节点
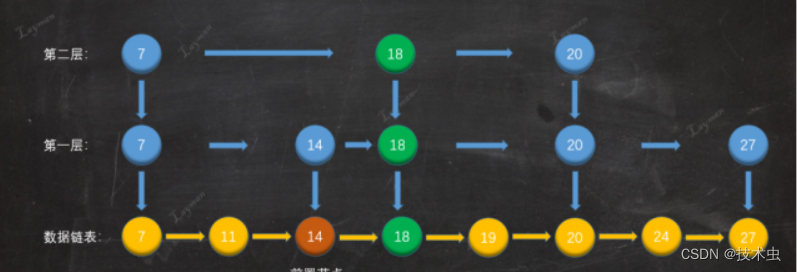
4. 添加索引层
创建索引节点后,下一此随机结果仍然成功,这个时候我们要创建索引层。
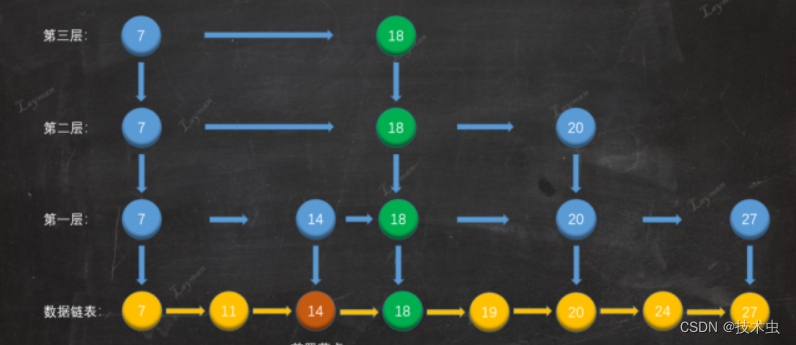
3. 删除数据
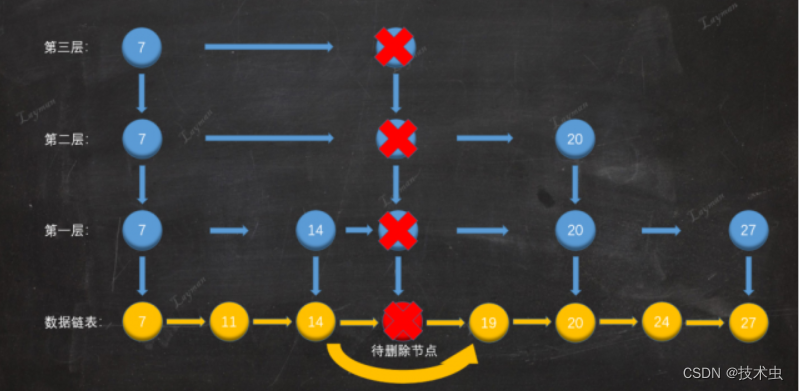
1. 假设我们删除18数据,先查找到18待删除节点。
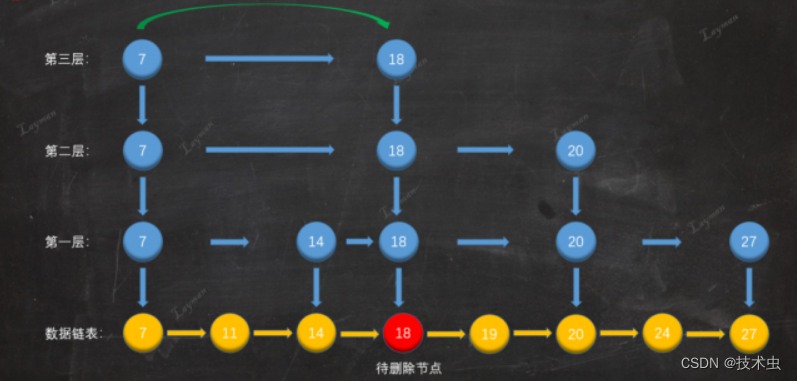
2. 删除原始链表节点,把18从原始链表中删除。

3. 删除索引节点
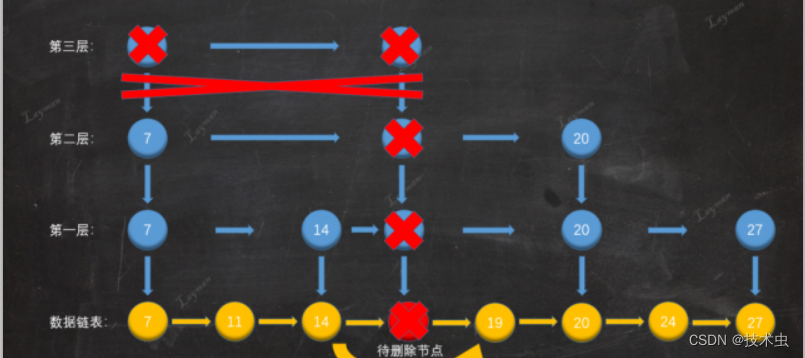
4. 删除索引层,删除索引层后第三层只剩下一个节点,所以索引层已经无意义
跳表代码实现
#include<iostream>
#include<ctime>
using namespace std;
const int MAXN_LEVEL=10;
struct SNode
{
int key;
SNode *forword[MAXN_LEVEL];
};
struct SkipList
{
int nowLevel;
SNode *head;
};
/************************************************
*参数:myList为指向跳表头结点的指针
*功能:初始化跳表
*************************************************/
void InitSkipList(SkipList *& myList)
{
myList=new SkipList;
myList->nowLevel=0;
myList->head=new SNode;
for(int i=0;i<MAXN_LEVEL;i++)
myList->head->forword[i]=NULL;
}
/************************************************
*参数:myList为指向跳表头结点的指针,x为待插入元素,countRet为查找次数
*功能:在跳表中插入元素x
*************************************************/
bool InsertSkipList(SkipList *myList,int val)
{
if(NULL==myList)
return false;
int k=myList->nowLevel;
SNode *q,*p=myList->head;
SNode *upDateNode[MAXN_LEVEL];
while(k>=0)
{
q=p->forword[k];
while(NULL!=q&&q->key<val)
{
p=q;
q=p->forword[k];
}
if(NULL!=q&&q->key==val)
return false;
upDateNode[k]=p;
--k;
}
k=rand()%(MAXN_LEVEL-1);
if(k>myList->nowLevel)
{
k=++myList->nowLevel;
upDateNode[k]=myList->head;
}
p=new SNode;
p->key=val;
for(int i=0;i<=k;i++)
{
q=upDateNode[i];//q指向前面小于x的
p->forword[i]=q->forword[i];
q->forword[i]=p;
}
//for(int i=k+1;i<=myList->nowLevel;i++)
for(int i=k+1;i<MAXN_LEVEL;i++)
p->forword[i]=NULL;
return true;
}
/************************************************
*参数:myList为指向跳表头结点的指针,x为待查找元素,countRet为查找次数
*功能:查找跳表中是否存在元素x
*************************************************/
SNode* FindSkipList(SkipList * myList,int val,int &countRet)
{
if(NULL==myList)
return NULL;
int k=myList->nowLevel;
SNode *q,*p=myList->head;
while(k>=0)
{
q=p->forword[k];
++countRet;
while(NULL!=q&&q->key<val)
{
++countRet;
p=q;
q=p->forword[k];
}
if(NULL!=q&&q->key==val)
return q;
--k;
}
return NULL;
}
/************************************************
*参数:myList为指向跳表头结点的指针,x为待删除元素
*功能:删除跳表中元素x
*************************************************/
bool DeleteSkipList(SkipList * myList,int val)
{
int tmpCountRet=0;
SNode *ret=FindSkipList(myList,val,tmpCountRet);
if(NULL==ret)
return false;
int k=myList->nowLevel;
SNode *q,*p=myList->head;
SNode *upDateNode[MAXN_LEVEL];
for(int i=0;i<MAXN_LEVEL;i++)
upDateNode[i]=NULL;
while(k>=0)
{
q=p->forword[k];
while(NULL!=q&&q->key<val)
{
p=q;
q=p->forword[k];
}
if(NULL!=q&&q->key==val)
upDateNode[k]=p;
--k;
}
for(int i=0;i<=myList->nowLevel;i++)
{
q=upDateNode[i];//q指向前面小于x
if(NULL!=q&&q->forword[i]==ret)
q->forword[i]=ret->forword[i];
}
delete ret;
return true;
}
int main()
{
int val;
SkipList * myList;
InitSkipList(myList);
while(cin>>val)
{
if(!InsertSkipList(myList,val))
cout<<val<<"插入失败!"<<endl;
else cout<<val<<"插入成功!"<<endl;
int countRet=0;
if(NULL!=FindSkipList(myList,val,countRet))
cout<<val<<"查找成功!"<<endl;
else cout<<val<<"查找失败!"<<endl;
cout<<"共查找了"<<countRet<<"次"<<endl;
DeleteSkipList(myList,val);
countRet=0;
if(NULL!=FindSkipList(myList,val,countRet))
cout<<val<<"查找成功!"<<endl;
else cout<<val<<"查找失败!"<<endl;
cout<<"共查找了"<<countRet<<"次"<<endl;
}
system("Pause");
}
参考文献
https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf















 7387
7387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









