







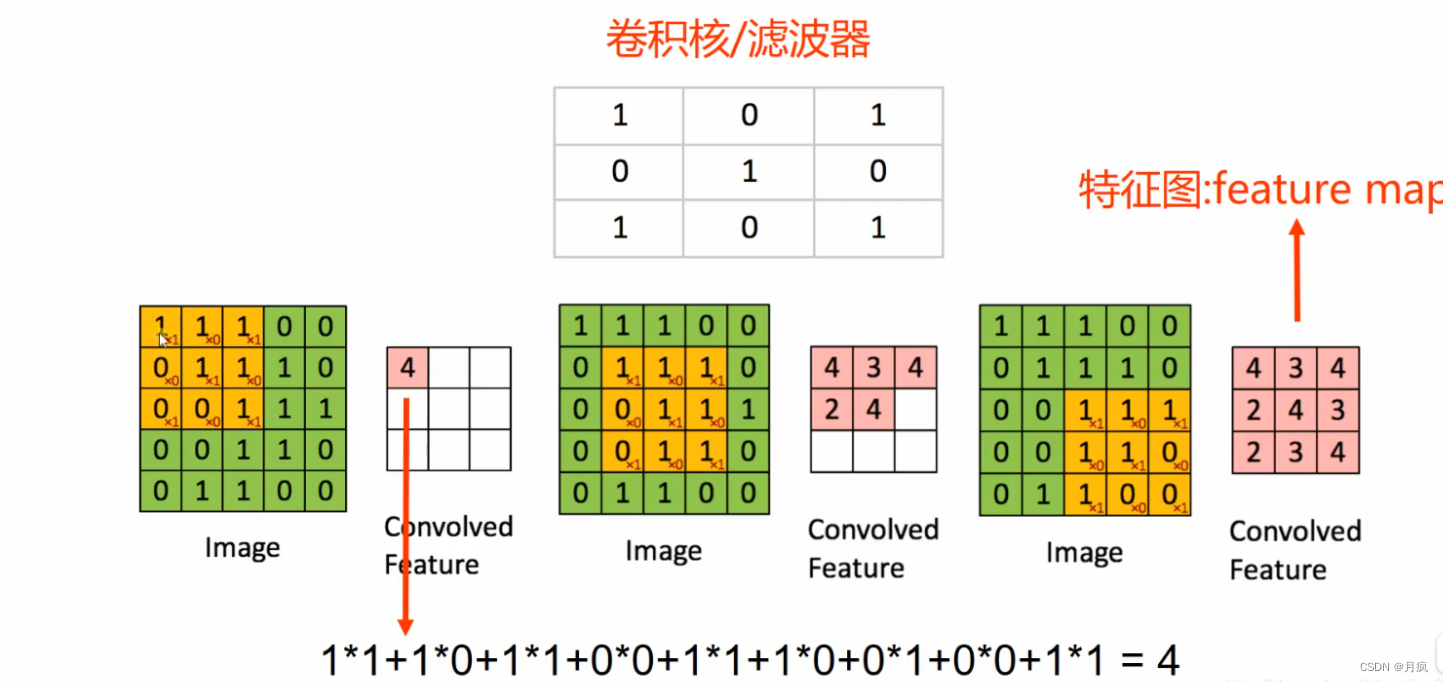
卷积核:
池化:
分为三种:
- 最大池化
- 平均池化
- 随机池化
from keras.datasets import mnist #直接从keras里面应用数据集
from keras.utils import np_utils #keras 里面用到的一个 np 的工具包
from keras.models import Sequential
#二维的卷积,二维的池化 Flatten是指把数据扁平化。
from keras.layers import Dense,Dropout,Convolution2D,MaxPool2D,Flatten #导入Dropt
from keras.optimizers import SGD,Adam #优化函数;
#载入数据
(x_train,y_train),(x_test,y_test)=mnist.load_data() #分为测试集和训练集
print(x_train.shape)
print(y_train[5])
# (60000,28,28) -> (60000,28,28,1) #最后一个参数是深度,黑白的深度为1,彩色的是3
#将数据转换为四维的格式.
x_train=x_train.reshape(-1,28,28,1)/255.0 #-1表示是自动判断,/225是表示归一化。
x_test=x_test.reshape(-1,28,28,1)/255.0#行数是 x_train.shape[0]行。
#标签转换成 one hot 格式
y_train=np_utils.to_categorical(y_train,num_classes=10)#专门用来转格式的包
y_test=np_utils.to_categorical(y_test,num_classes=10)
#定义模型的顺序
model=Sequential()
#第一个卷积层
model.add(Convolution2D(
input_shape=(28,28,1), #输入平面.后边的卷积层就不需要设置了。
filters=32, #卷积核个数.
kernel_size=5, #卷积窗口大小.
strides=1, #步长.
padding="same", #pading方式 same/valid. pad填充。使用same的话得到的特征图和上面的大小一样。
activation="relu" #激活函数.
))
#第一个池化层
#池化层有多大,可以算一下.14*14
model.add(MaxPool2D(
#输入的形状不需要特别指定了
pool_size=2,
strides=2,
padding='same',
))
#第二个卷积层
#python 的语法,如果顺序和参数默认一样,就可以直接写参数。不用写形参。
model.add(Convolution2D(64,5,strides=1,padding='same',activation='relu'))
#第二个池化层,池化完以后成7*7
model.add(MaxPool2D(2,2,"same"))
#把第二个池化层的输出扁平化为1维
#把 64*7*7 的图像扁平化,就是将所有特征作为神经网的输入
#为了和下边的全连接。
model.add(Flatten())
#第一个全连接层
model.add(Dense(1024,activation="relu"))
model.add(Dropout(0.5))
#第二个全连接层
model.add(Dense(10,activation="softmax"))
#定义优化器
#10的-4次方.
adam=Adam(lr=1e-4)
#定义优化器,在训练的过程中计算准确度。
model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=["accuracy"])
#训练模型
model.fit(x_train,y_train,batch_size=64,epochs=10)
#评估模型
loss,accuracy=model.evaluate(x_test,y_test)
print("test lost *********",loss)
print("test accuracy***",accuracy)















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









