






疲劳检测实验报告
邢益玮 201930101151 2021/1/13
(重度拖延症了,内容又有点多,学长和老师不好意思了🙏🙏🙏)
前言
实验目的:
本次探索性实验——疲劳检测的实验目的是通过计算机视觉,对于驾驶员的状态进行“疲劳”、“有点疲劳”、“清醒”三个状态的分类,其中需要实现无遮挡与戴口罩两种状态下的分类。
准备工作:
在第一周,我们所做的准备工作是录制自己在六种状态(有无口罩、疲劳程度)下的视频。
我录制了不同状态共六段,每段长约一分钟的视屏文件,为了方便,之后的尝试都以我自己的六个视频作为数据集。
实验平台:
Python+Anaconda+spyder
小背景:
通过查阅资料,我发现在无遮挡状态下的疲劳检测已经有人用dlib库比较好的解决了,而戴口罩状态下的疲劳检测还尚待解决。
最初,我想先尝试现有的dlib方案,然而安装的时候出了问题,dlib库用不了。
不得已,我只能尝试另一条路——深度学习。
然而在开始实验时,我的编程水平还只停留在大一上学期,只会一些python基础,对于深度学习,唯一的印象就是人工智能,热门。
而它的相关知识,我一点都不知道,原理也更是一窍不通。
于是我只能从零开始,去阅读各种网页,学习各种东西,尝试着一步一步走,遇到什么问题解决什么问题。
由于无口罩状态下的分类已经较好的解决了,我后期的尝试主要专注于戴口罩状态下的分类。
最终,耗时三四个星期,还是做出了一套“理论上可行”的疲劳检测方法。
下面,我将逐步阐述我的实验过程
以下是正文部分
一、最初的尝试——dlib库
1.1 信息收集
首先查阅资料,搜索“python疲劳检测”等关键词。得到的结果中有许多方法,例如dlib、cnn等,然而完全看不懂。
于是我试着阅读了老师与学长给的opencv教程等资料,但是依然没有什么头绪。
直到我找到了几篇博客与视频,比较系统的阐述了dlib人脸识别的方法,再结合对于opencv的初步理解,我大概明白了利用dlib检测的大概流程。
dlib库实现疲劳检测的方法:
Dlib模型之驾驶员疲劳检测一(眨眼)
dlib库检测人脸使用方法与简单的疲劳检测应用
基于图像驾驶员疲劳检测技术研究fatigue_detecting
dlib库进行检测的原理是通过人脸提取器,识别人脸68个特征点,然后提取坐标进行计算,通过眼部或嘴部特征点的距离判断是否眨眼或打哈欠,实现眨眼与打哈欠检测后再设置参数,当眨眼或打哈欠超过阈值,则认定为疲劳,并报警。有人还做了一个界面,将这个功能打包可视化。
这一方法有两个不满足要求之处:一是无法区分疲劳与有点疲劳状态;二是在戴口罩状态下其检测效果未知。
不过总的来说,这一方案已经很成熟了。
于是在开始阶段,我当然是放弃了那些看不懂的cnn什么的,选择先去尝试这样一个原理相对简单的方法。
1.2 为Anacoda安装opencv
(当我把源码复制到初始的的spyder里面,点击运行,当然是没有成功的。)
费了点功夫才知道,首先当然要安装dlib库与cv2(opencv)等库才能运行。于是上网百度安装方法。
由于当时还不清楚ide与anaconda是两个环境,安装的时候踩了点坑
在安装opencv的时候,我使用学长和同学提供的pip install方法安装成功。
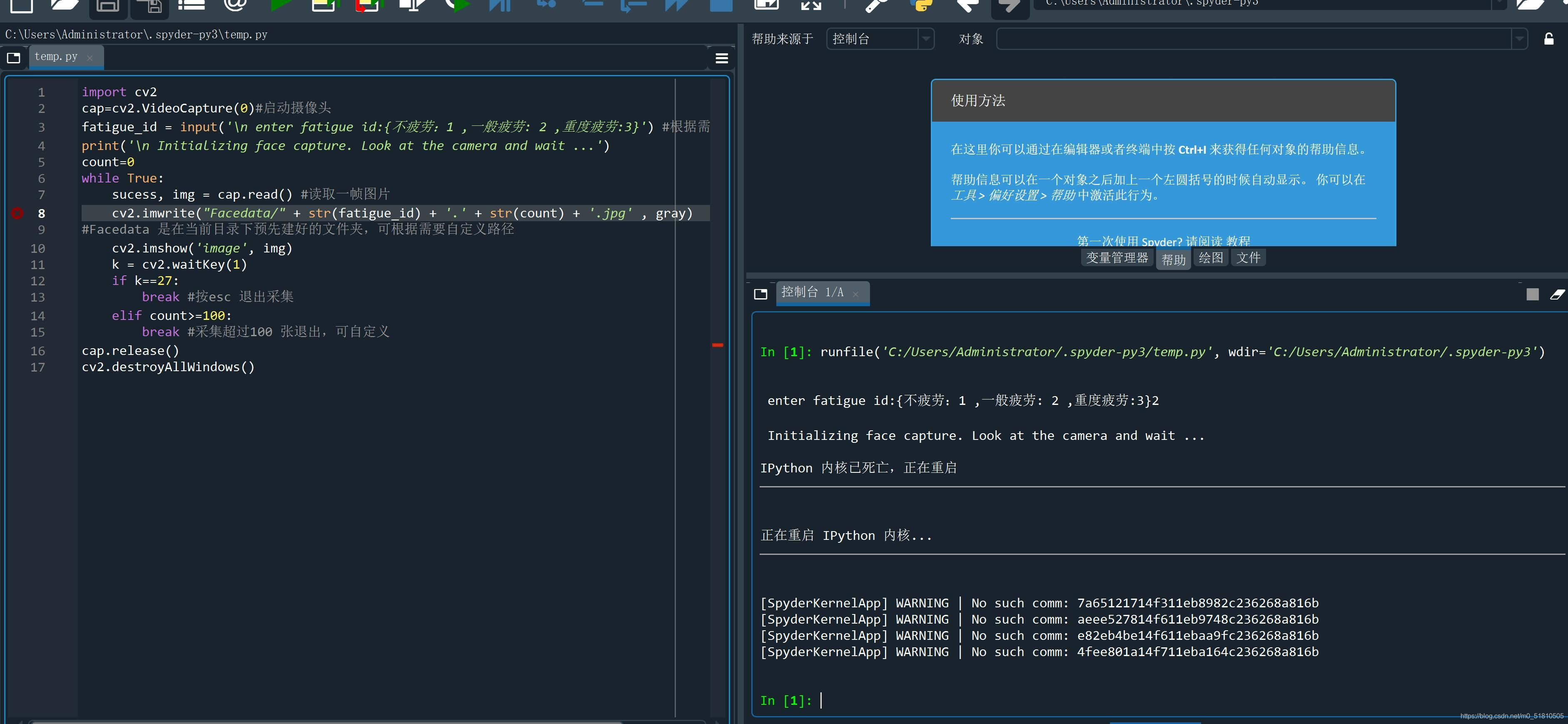
结果运行的时候,spyder提示“内核死亡”,无论怎么尝试都不行。
于是又费了点功夫,才查到使用whl文件安装的办法。用whl文件安装成功。
然而还是出现内核死亡的问题。查了不少资料,都没有这个情况。最后我花了一个小时重装了anaconda才解决。
安装opencv:
Anaconda安装opencv-python
windows环境下的Anaconda安装与OpenCV机器视觉环境搭建
1.3 为Anacoda安装dlib
安装dlib:
Anaconda安装Dlib库
Anaconda安装Dlib库(亲测成功)
然而在dlib安装时,按照查阅到的资料,使用第一个方法——pip install,安装boost、cmake成功,但是安装dlib失败了,用系统给的的错误信息在百度搜索,也搜不到相关信息。
然后就尝试使用第二个方法——whl文件安装。我使用从网上找到的whl文件进行安装(版本等都对应),虽然显示安装成功,但是在spyder内运行imoprt dlib时,依然出现错误,提示
ImportError:DLL load failed:动态链接库(DLL)初始化失败
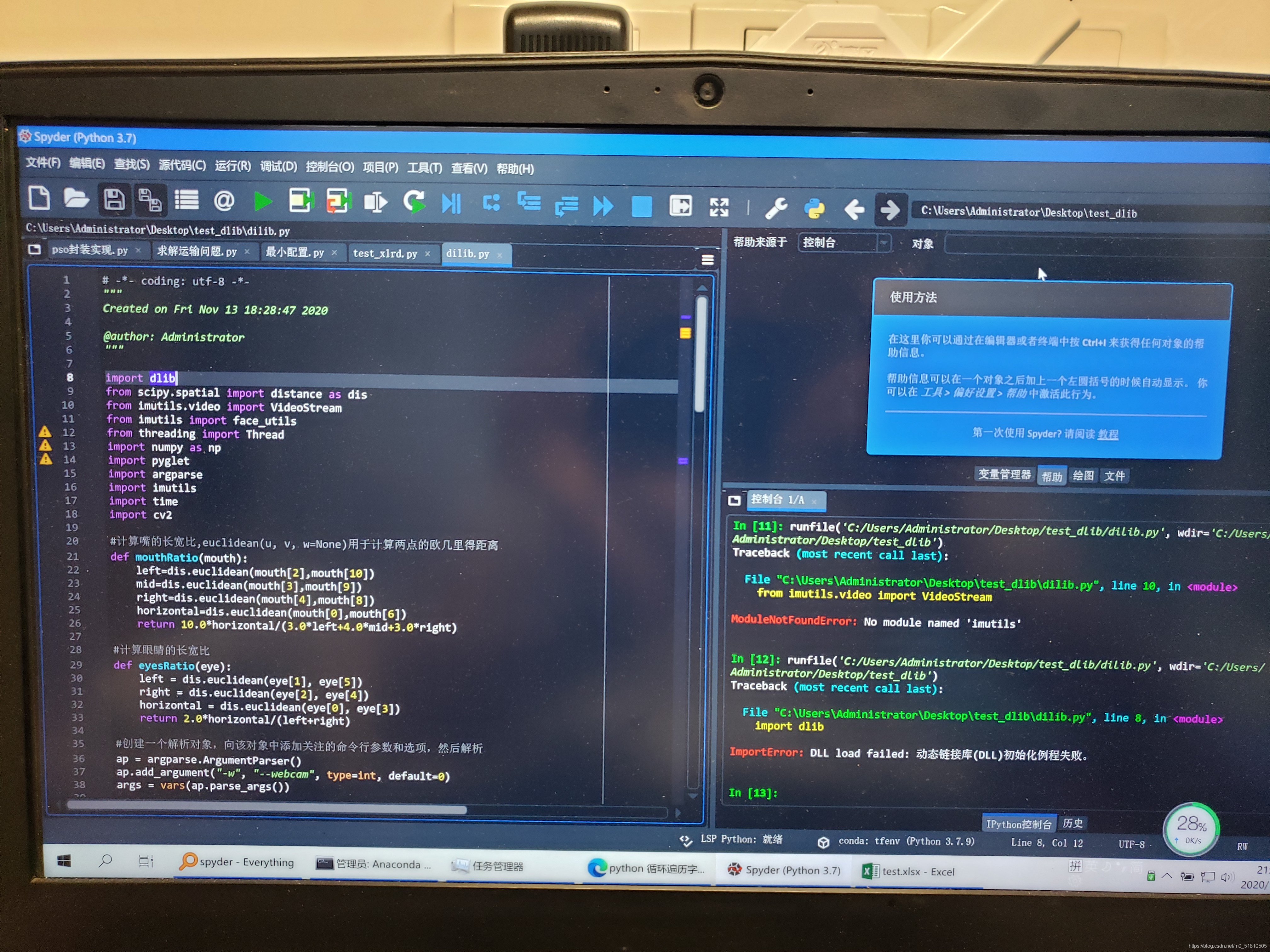
之后我重装anaconda,或是尝试把python版本降至3.7、3.6等,也添加了环境变量,都失败了,前后折腾了好几天。
于是我只能尝试在百度上继续搜索错误,然后找到了如下网页:
与dlib安装出错原因相关的网页:
Tensorflow安装在windows 上面出现ImportError: DLL load failed: 动态链接库(DLL)初始化例程失败。
有人在安装tensorflow时遇到了类似的错误,原因是cpu不支持avx指令集,而他安装的tensorflow版本需要调用avx指令集。
依照我的硬件知识,我记得我电脑的cpu是g4560,恰好是不支持avx指令集的,而whl文件安装的dlib库应该是没有考虑过低端cpu不支持avx的问题的。所以我开始把重心放在dlib和avx上。
有关dlib与avx指令集的网页:
Dlib支持CPU指令集编译问题(SSE4.2或者AVX)
Ubuntu 16.04开启dlib对于AVX或者CUDA的支持
Dlib was compiled to use AVX instructions, but these aren’t available on your machine.
Dlib安装遇到的坑
最后搜集到的信息告诉我,大概要编译dlib才能解决这个问题。但是我完全没有接触过编译,一点概念都没有,也没有现成的博客可以套用。所以没办法,只能接着查。
与编译dlib有关的网页:
安装与编译Dlib(以Ubuntu16.04+Python3.6+pip为例)
dlib库编译与使用
Windows下的编译安装dlib(cmake)
Win10下安装CMake3.14.2以及CMake使用教程
最后我尝试着按照博客所教的,下载安装cmake并尝试进行dlib的编译,但是由于相关信息太少,最后还是没有成功。而且在使用cmake的过程中又出现了新的错误,导致连初始的几步都完成不了,只得作罢。
由于安装dlib始终无法成功,我不得不考虑新的路线——深度学习。
二、深度学习方法(基于keras)
在经过一段时间的信息收集之后,我认识到疲劳检测问题本质上就是对不同状态进行分类的问题,而深度学习方法(cnn等)是十分适合解决分类问题的,网上也有很多现成的资源。在电脑装不上dlib库的情况下,我最终学习并尝试使用深度学习进行疲劳检测。
2.1 信息收集
由于最初收集信息的时候,我看到了有文章提到了使用cnn进行疲劳检测。在经过查询后我了解到cnn其实是卷积神经网络,属于深度学习的范畴,用在图片识别中。所以我的第一步是收集与cnn相关的疲劳检测方法,并尝试理解这一东西。
基于cnn的疲劳检测方法:
基于 CNN 的疲劳检测源码-Python
基于MTCNN+CNN的疲劳(危险)驾驶检测系统设计
GitHub - Revan-github/Fatigue-Driven-Detection-Based-on-CNN: 本科毕设内容:基于卷积神经网络的疲劳驾驶检测。
结果我对着一堆源码和博客发呆了半天,完全看不懂(更别提这些源码有一些基于keras,有一些基于pytorch)。迫不得已,我准备从零开始学习深度学习的相关知识,以便读懂源码。于是我花了一两天时间,陆续阅读了这本教材的相关部分:
Python深度学习
(pdf版本是咸鱼花了几块钱买的,除了这本书之外还有一堆其他资源,懒得看了。)
这本教材比较详细的介绍了深度学习的基本知识,然后介绍了深度学习的实践。
我在里面主要参考了深度学习的基础内容与它在计算机视觉的运用,即卷积神经网络(cnn)的运用。读完之后我对其中的原理与语法有了一个大概的了解,而且我注意到一个省事的方法——使用预训练的卷积神经网络,即迁移学习。书上所举的例子使用vgg16网络进行特征提取(卷积),效果比最开始使用几个卷积层进行分类的效果好很多,并且所需要的数据集大大缩小。最重要的是我可以跳过最繁琐复杂的添加卷积层的步骤,而直接调用现成的模型。
此时我产生了一条基本思路:
将戴口罩下三个状态的视频分别按帧切分,产生三组图片——疲劳、有点疲劳、清醒,作为数据集。然后将这些数据集使用预训练模型进行训练,得到一个权重模型。在实际使用中,让摄像头隔一段时间拍一张人脸照,用这个权重模型去判断人脸照片的状态,进而通过一些参数的设定,确定驾驶员的状态。
接下来是进一步搜集信息,进一步理解预训练模型:
与预训练模型有关的文章:
卷积神经网络VGG16这么简单,为什么没人能说清?
mlnd_distracted_driver_detection
【转载】ResNet论文笔记((对比vgg16网络))
学习笔记:大话经典模型AlexNet、VGGNet、GoogLeNet、ResNet
老司机坐稳了,Kaggle竞赛-深度学习检测疲劳驾驶简要回顾
在对书中介绍的几种模型进行了解后,我选择了resnet50模型,理由是它在imagenet比赛中打败其他众多模型,精确度较高,而且在keras中可以由一行代码很方便的调用。
接下来是搜集有关resnet50模型运用在图像分类与迁移学习中的示例进行参考。但是在这一步中,我搜索到的示例所使用的数据集格式都不是图片,而是hdf5格式,于是我又搜索了一些通过图片制作数据集的文献,不过最后没有用到。
最后解决问题的是两篇博客,也是之后工作的模板与参考的重点:
在使用这两篇博客的内容完成主体模型的构建工作后,剩下的内容就是一些改进、完善与小修小补了。
下面,我将介绍实现整一套模型构建的流程,并给出源码
2.2 为Anaconda安装tensorflow+keras
在读完书并做了一些其他的理论准备后,我尝试搭建了自己的keras深度学习平台,并且在上面成功的运行了书上示例的mnist手写数据集的训练。(顺便一提,我的电脑显卡是1060 6g,刚好是深度学习推荐配置的最低要求,这也是我选择尝试的一个重要前提)
以下是我的配置与安装的各个版本:
显卡:gtx1060 6g
驱动程序版本:442.50
python:3.7.9
opencv:4.4.0
CUDA:10.0.130(与博客相同)
cudnn:v7.6.4(与博客相同)
tensorflow-gpu:1.15.0(与博客相同)
keras:2.3.1
spyder:4.1.5
安装tensorflow:
使用anaconda 3安装tensorflow 1.15.0 (win10环境)
安装keras:
tensorflow和keras版本对应关系
conda创建TensorFlow和Keras指定版本环境
安装spyder:
WIN10+Anaconda3+spyder安装tensorflow避坑攻略
在windows Anaconda中安装tensorflow 以及安装spyder(在Spyder中编辑tensorflow代码)
整个流程中最麻烦,最难的就是安装tensorflow。创建新环境,安装cuda,搞了一大堆,非常耗时。我当时还完全搞不懂创建环境等操作(甚至不知道在prompt里要先要激活环境),还重装了驱动,感觉整个安装的过程比较繁琐。而且后来遇到了一些问题,折腾了一个下午才装好tensorflow。不过装好以后还是挺有成就感的,毕竟dlib折腾了一星期还是安不上QAQ
安装keras就比较简单了,直接一行命令搞定。
装好keras之后还要在环境中重新安装spyder,试了两种方法才成功,也装了挺久。
但是搞完之后出现在spyder中无法import tf、keras版本过高等问题。我又按照当时查到的资料,在prompt里面重装hdf5库,不行;又重装spyder,也不行。最后查到了另一篇资料,升级conda库解决,成功安装。
装好keras之后,我尝试运行了书中示例:mnist手写数据集,成功。
minist手写数据集.py
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 30 15:53:02 2020
@author: xyw
"""
from keras.datasets import mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
network.fit(train_images, train_labels, epochs=5, batch_size=128)
运行结果:
60000/60000 [==============================] - 2s 31us/step - loss: 0.2558 - accuracy: 0.9247
Epoch 2/5
60000/60000 [==============================] - 1s 21us/step - loss: 0.1041 - accuracy: 0.9700
Epoch 3/5
60000/60000 [==============================] - 1s 21us/step - loss: 0.0685 - accuracy: 0.9795
Epoch 4/5
60000/60000 [==============================] - 1s 21us/step - loss: 0.0488 - accuracy: 0.9855
Epoch 5/5
60000/60000 [==============================] - 1s 21us/step - loss: 0.0375 - accuracy: 0.9885
成功之后我非常开心。至此,能够尝试新的方向了。
接下来就是尝试疲劳检测模型的训练了。
2.3 数据预处理(基于opencv)
我将目标放在戴口罩状态下的疲劳检测上,依照基本思路,我首先需要将戴口罩的三个视频按帧提取,得到戴口罩状态下的三组照片,再进行下一步操作。
opencv视频转图片.py
import cv2
import os
#要提取视频的文件名,隐藏后缀
sourceFileName='3'
#在这里把后缀接上
video_path = os.path.join("C:\\Users\\Administrator\\Desktop\\pilaojiancexyw\\", sourceFileName+'.mp4')
times=0
#提取视频的频率,每1帧提取一个
frameFrequency=1
#输出图片到当前目录vedio文件夹下
outPutDirName='vedio/'+sourceFileName+'/'
if not os.path.exists(outPutDirName):
#如果文件目录不存在则创建目录
os.makedirs(outPutDirName)
camera = cv2.VideoCapture(video_path)
while True:
times+=1
res, image = camera.read()
if not res:
print('not res , not image')
break
if times%frameFrequency==0:
cv2.imwrite(outPutDirName + str(times)+'.jpg', image)
print(outPutDirName + str(times)+'.jpg')
print('图片提取结束')
camera.release()
利用这个代码,我将戴口罩下三个视频转为图片,放在了桌面的vedio文件夹中。下面给出文件夹的部分截图:
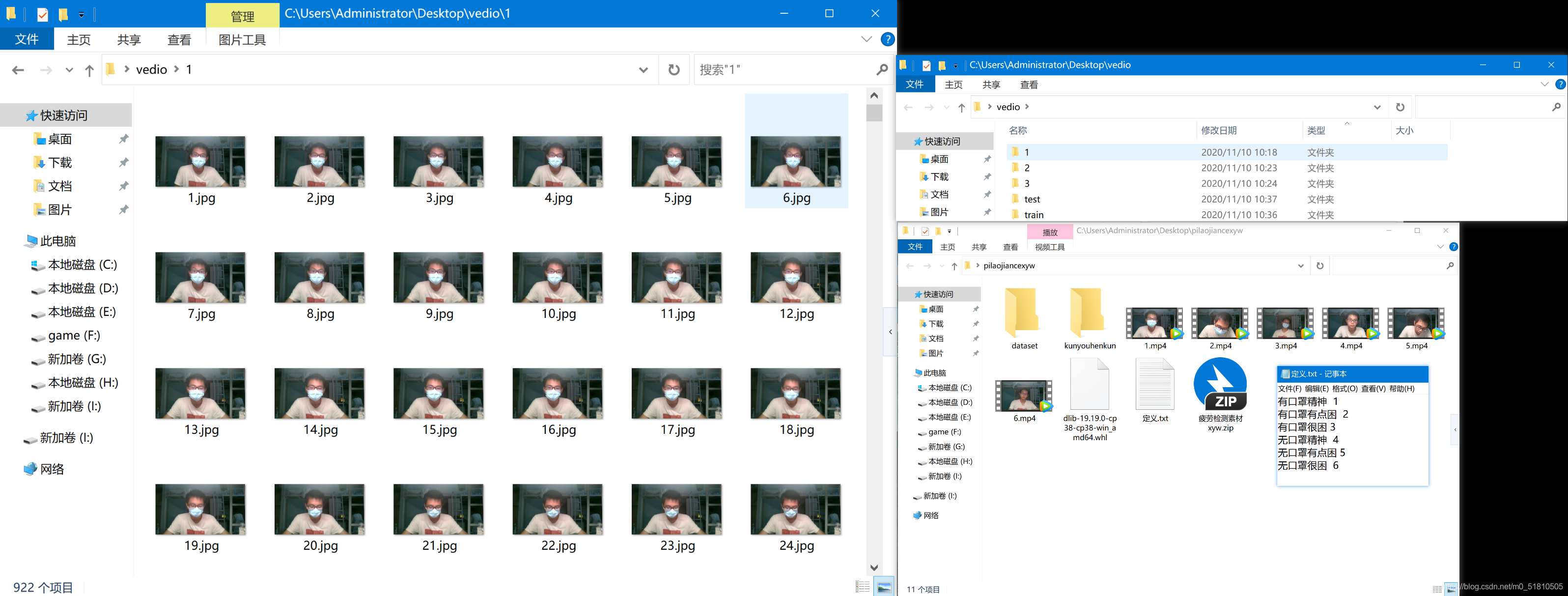
上面的文件夹分别是原始视频内容、存放处理后图片的文件夹、处理后的图片的部分示例。基本概况如下:
定义:
文件夹1(视频1):有口罩精神:视频文件1分01秒,60fps\图片922张
文件夹2(视频2):有口罩有点困:视频文件1分01秒,60fps\图片920张
文件夹3(视频3):有口罩很困:视频文件1分06秒,60fps\图片993张
尺寸均为:1920×1080
也就是说,我的数据集共约有3000张图片,这个数据集大小基本符合训练的条件。
但是这个数据集的背景、光线、人物等图片要素都比较相似。因此普适性很差,训练出来的模型肯定鲁棒性弱。如果要进行进一步的改进,就要收集更多的不同人、不同拍摄环境下的图片,并且可以进行数据增强。但是这些以我目前的条件很难采集,就暂且放弃了。
完成了数据的预处理之后,就要开始正式的工作了。
2.4 二分类(基于resnet50)
在这一步,我开始尝试使用该博客的代码进行二分类:
2.4.1 数据集制作
该博客使用的数据集由四个部分组成,分别是:X_train,Y_train,X_test,Y_test
意义是X、Y二分类,每类的数据集再划分为训练与测试集。这四个数据集分别对应四个存放图片的文件夹。
仿照这样的数据结构,我建立了四个文件夹,内容为:
train\qingxing:文件夹1的前500张
train\kun:2前500张、3前500张
test\qingxing:文件夹1的后面全部
test\kun :2的后面全部、3的后面全部
由于博客是二分类,我就将有点困、很困两种状态一并加到kun这一类里了。事实证明,这样做是不对的。当我训练出模型后,我发现不论是哪种状态,最后都会判定为一类。我在这篇博客的评论区找到了问题所在。
于是我手动将kun的train样本随机删去一部分,让两个状态的样本量变为:
train\qingxing:544张图片
train\kun:561张图片
test\qingxing:378张图片
test\kun :360张图片
这样处理之后,训练的模型能够正常区分两种状态了。
接下来是制作数据集。在博客中,博主在完整代码中直接读取文件夹的文件,将其转为X_train,Y_train,X_test,Y_test这四个numpy数组(array),然后直接用它进行下一步的训练,并没有保存这四个数组。而在实际运行中,读取数据图片并处理转化为数组需要一定时间。为了方便后续工作,我将制作数组的代码单独改写,保存最后得到的四个数组,并在后续直接读取使用。
数据集制作.py
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 10 11:55:52 2020
@author: xyw
"""
import os
import numpy as np
from tensorflow.keras.preprocessing import image
from PIL import Image
import random
def DataSet():
# 首先需要定义训练集和测试集的路径,这里创建了 train , 和 test 文件夹
# 每个文件夹下又创建了 glue,medicine 两个文件夹,所以这里一共四个路径
train_path_k ='C:\\Users\\Administrator\\Desktop\\vedio\\train\\kun\\'
train_path_qx = 'C:\\Users\\Administrator\\Desktop\\vedio\\train\\qingxing\\'
test_path_k ='C:\\Users\\Administrator\\Desktop\\vedio\\test\\kun\\'
test_path_qx = 'C:\\Users\\Administrator\\Desktop\\vedio\\test\\qingxing\\'
# os.listdir(path) 是 python 中的函数,它会列出 path 下的所有文件名
# 比如说 imglist_train_glue 对象就包括了/train/glue/ 路径下所有的图片文件名
imglist_train_k = os. listdir(train_path_k)
imglist_train_qx = os.listdir(train_path_qx)
# 下面两行代码读取了 /test/glue 和 /test/medicine 下的所有图片文件名
imglist_test_k= os.listdir(test_path_k)
imglist_test_qx = os.listdir(test_path_qx)
# 这里定义两个 numpy 对象,X_train 和 Y_train
# X_train 对象用来存放训练集的图片。每张图片都需要转换成 numpy 向量形式
# X_train 的 shape 是 (360,224,224,3)
# 360 是训练集中图片的数量(训练集中固体胶和西瓜霜图片数量之和)
# 因为 resnet 要求输入的图片尺寸是 (224,224) , 所以要设置成相同大小(也可以设置成其它大小,参看 keras 的文档)
# 3 是图片的通道数(rgb)
# Y_train 用来存放训练集中每张图片对应的标签
# Y_train 的 shape 是 (360,2)
# 360 是训练集中图片的数量(训练集中固体胶和西瓜霜图片数量之和)
# 因为一共有两种图片,所以第二个维度设置为 2
# Y_train 大概是这样的数据 [[0,1],[0,1],[1,0],[0,1],...]
# [0,1] 就是一张图片的标签,这里设置 [1,0] 代表 固体胶,[0,1] 代表西瓜霜
# 如果你有三类图片 Y_train 就因该设置为 (your_train_size,3)
X_train = np.empty((len(imglist_train_k) + len(imglist_train_qx), 224, 224, 3))
Y_train = np.empty((len(imglist_train_k) + len(imglist_train_qx), 2))
# count 对象用来计数,每添加一张图片便加 1
count1 = 0
# 遍历 /train/glue 下所有图片,即训练集下所有的固体胶图片
for img_name in imglist_train_k:
# 得到图片的路径
img_path = train_path_k + img_name
# 通过 image.load_img() 函数读取对应的图片,并转换成目标大小
# image 是 tensorflow.keras.preprocessing 中的一个对象
img = image.load_img(img_path, target_size=(224, 224))
# 将图片转换成 numpy 数组,并除以 255 ,归一化
# 转换之后 img 的 shape 是 (224,224,3)
img = image.img_to_array(img) / 255.0
# 将处理好的图片装进定义好的 X_train 对象中
X_train[count1] = img
# 将对应的标签装进 Y_train 对象中,这里都是 固体胶(glue)图片,所以标签设为 [1,0]
Y_train[count1] = np.array((1,0))
count1+=1
# 遍历 /train/medicine 下所有图片,即训练集下所有的西瓜霜图片
for img_name in imglist_train_qx:
img_path = train_path_qx + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_train[count1] = img
Y_train[count1] = np.array((0,1))
count1+=1
# 下面的代码是准备测试集的数据,与上面的内容完全相同,这里不再赘述
X_test = np.empty((len(imglist_test_k) + len(imglist_test_qx), 224, 224, 3))
Y_test = np.empty((len(imglist_test_k) + len(imglist_test_qx), 2))
count2 = 0
for img_name in imglist_test_k:
img_path = test_path_k + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_test[count2] = img
Y_test[count2] = np.array((1,0))
count2+=1
for img_name in imglist_test_qx:
img_path = test_path_qx + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_test[count2] = img
Y_test[count2] = np.array((0,1))
count2+=1
# 打乱训练集中的数据
index = [i for i in range(len(X_train))]
random.shuffle(index)
X_train = X_train[index]
Y_train = Y_train[index]
# 打乱测试集中的数据
index = [i for i in range(len(X_test))]
random.shuffle(index)
X_test = X_test[index]
Y_test = Y_test[index]
return X_train,Y_train,X_test,Y_test
X_train,Y_train,X_test,Y_test = DataSet()
np.save('C:\\Users\\Administrator\\Desktop\\test2\\X_train', X_train, allow_pickle=True, fix_imports=True)
np.save('C:\\Users\\Administrator\\Desktop\\test2\\Y_train', Y_train, allow_pickle=True, fix_imports=True)
np.save('C:\\Users\\Administrator\\Desktop\\test2\\X_test', X_test, allow_pickle=True, fix_imports=True)
np.save('C:\\Users\\Administrator\\Desktop\\test2\\Y_test', Y_test, allow_pickle=True, fix_imports=True)
print('X_train shape : ',X_train.shape)
print('Y_train shape : ',Y_train.shape)
print('X_test shape : ',X_test.shape)
print('Y_test shape : ',Y_test.shape)
运行结果如下:
X_train shape : (1105, 224, 224, 3)
Y_train shape : (1105, 2)
X_test shape : (738, 224, 224, 3)
Y_test shape : (738, 2)
在test2文件夹中的数据集:

数据集维度定义:
训练集:
X_train:1105张图片,尺寸224×224,颜色通道rgb共3个
Y_train:1105张图片,2个标签
(X_train、Y_train的图片与标签维度在顺序上是一一对应的)
测试集:
X_test、Y_test同理。
标签:
kun:(1,0)
qingxing:(0,1)
在代码中将图片尺寸进行了缩放(1920×1080 --> 224×224)以适应resnet50模型的需要。
得到了四个数据集文件之后,接下来就可以开展训练模型与检验模型的工作了。
2.4.2 训练模型
先给出训练模型的代码:
resnet训练模型.py
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 10 12:03:59 2020
@author: xyw
"""
import numpy as np
import scipy
from scipy import ndimage
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
# # model
X_train = np.load('C:\\Users\\Administrator\\Desktop\\test2\\X_train.npy')
Y_train = np.load('C:\\Users\\Administrator\\Desktop\\test2\\Y_train.npy')
X_test = np.load('C:\\Users\\Administrator\\Desktop\\test2\\X_test.npy')
Y_test = np.load('C:\\Users\\Administrator\\Desktop\\test2\\Y_test.npy')
model = ResNet50(weights=None,classes=2)
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# # train
history=model.fit(X_train, Y_train, epochs=10, batch_size=12,validation_data=(X_test, Y_test))
# # evaluate
model.evaluate(X_test, Y_test, batch_size=32)
# # save
model.save('C:\\Users\\Administrator\\Desktop\\test2\\my_resnet_model_e10bs12.h5')
# # draw
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
在训练模型的时候,我更改调试的参数为epochs(训练轮数,一般往多了设)、batch_size(越大越好,但是太大会爆显存,我试了batch_size=32,确实爆了)
在生成文件时,依据这两个参数的大小,定义命名规则如下:
my_resnet_model_e'x'bs'y'
其中'x'是epochs的大小,'y'是batch_size的大小
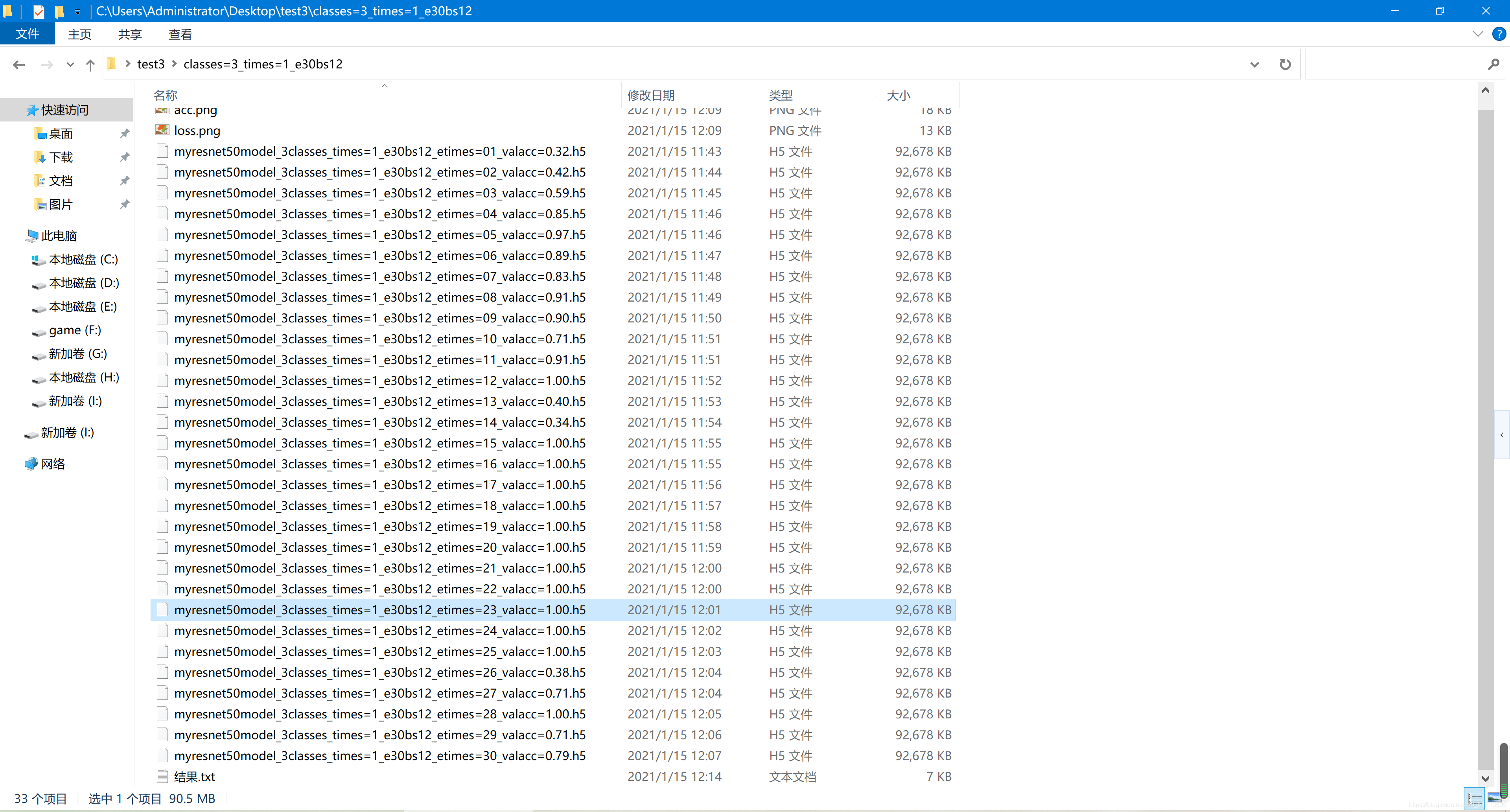
我改变参数训练了几次,得到以下几个模型文件:

它们训练的结果如下:
e5bs12
1105/1105 [==============================] - 30s 27ms/sample - loss: 0.4514 - acc: 0.8805
Epoch 2/5
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.2093 - acc: 0.9376
Epoch 3/5
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.1699 - acc: 0.9439
Epoch 4/5
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.0576 - acc: 0.9846
Epoch 5/5
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.0111 - acc: 0.9964
738/738 [==============================] - 6s 8ms/sample - loss: 8.0788 - acc: 0.4878
e1bs12
1105/1105 [==============================] - 30s 27ms/sample - loss: 0.3237 - acc: 0.9104
738/738 [==============================] - 6s 8ms/sample - loss: 7.0154 - acc: 0.4878
e6bs12
1105/1105 [==============================] - 30s 27ms/sample - loss: 0.4012 - acc: 0.8860
Epoch 2/6
1105/1105 [==============================] - 22s 20ms/sample - loss: 0.2523 - acc: 0.9222
Epoch 3/6
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.1121 - acc: 0.9538
Epoch 4/6
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.0404 - acc: 0.9864
Epoch 5/6
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.1458 - acc: 0.9529
Epoch 6/6
1105/1105 [==============================] - 23s 20ms/sample - loss: 0.0742 - acc: 0.9756
738/738 [==============================] - 6s 8ms/sample - loss: 0.6280 - acc: 0.8347
e10bs12
1105/1105 [==============================] - 36s 32ms/sample - loss: 0.4967 - acc: 0.8661 - val_loss: 4.1914 - val_acc: 0.4878
Epoch 2/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.1754 - acc: 0.9348 - val_loss: 22.9513 - val_acc: 0.4878
Epoch 3/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.1459 - acc: 0.9566 - val_loss: 6.2329 - val_acc: 0.4878
Epoch 4/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.1808 - acc: 0.9520 - val_loss: 0.8540 - val_acc: 0.6707
Epoch 5/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.1071 - acc: 0.9647 - val_loss: 3.1942 - val_acc: 0.5854
Epoch 6/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.1488 - acc: 0.9629 - val_loss: 1.3391 - val_acc: 0.6802
Epoch 7/10
1105/1105 [==============================] - 27s 25ms/sample - loss: 0.0722 - acc: 0.9810 - val_loss: 0.7883 - val_acc: 0.6003
Epoch 8/10
1105/1105 [==============================] - 28s 25ms/sample - loss: 0.0126 - acc: 0.9973 - val_loss: 3.1924 - val_acc: 0.6003
Epoch 9/10
1105/1105 [==============================] - 28s 25ms/sample - loss: 0.0189 - acc: 0.9919 - val_loss: 1.0980 - val_acc: 0.6504
Epoch 10/10
1105/1105 [==============================] - 28s 25ms/sample - loss: 0.0078 - acc: 0.9982 - val_loss: 3.8652 - val_acc: 0.5000
738/738 [==============================] - 5s 7ms/sample - loss: 3.8652 - acc: 0.5000
参数解释:
acc:代表模型分类图片的准确度,越高越好
loss:大意是模型输出与真实值的误差,是损失函数的值(例如交叉熵函数),越低越好
其中acc与loss是在训练集上训练模型的结果,val_acc与val_loss是在测试集上测试模型的结果。在结果中还能看出训练一轮的时间。
最好的一次训练结果,在训练集上训练的精度达到0.96,而在测试集上测试的精度达到0.68,不大高。出现这个结果的原因与我的数据集制作有关,在制作数据集的过程中,样本不够大,而且测试集与训练集的划分是手工随机的,并没有做到完全随机划分。但即便是在这样的情况下,在测试集上的测试精度也能接近百分之七十,勉强能用,也间接表明了resnet50模型的实用性不错。
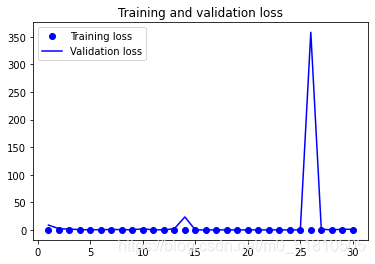
在训练完前几个模型后,我用教材中的代码完善了博客的代码,使得输出结果可以展示模型在测试集上测试的结果,并且做出acc与loss变化图,通过这些图片可以直观的感受训练过程中的acc与loss变化的趋势。如下是在epochs=10, batch_size=12的一次训练中生成的图片:
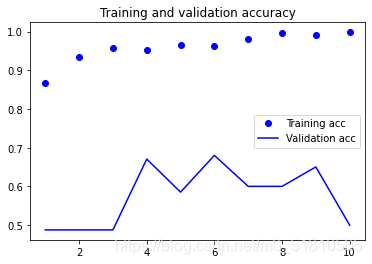
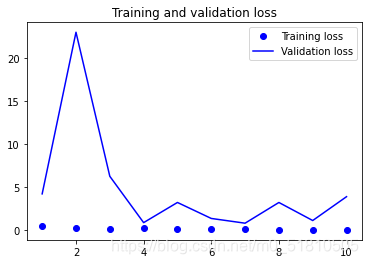
在训练并保存模型文件之后,就要看看模型文件如何调用,如何应用于实际的检测了。
2.4.3 调用模型
先给代码:
测试模型.py
# -*- coding: utf-8 -*-
"""
Created on Tue Nov 10 11:34:39 2020
@author: xyw
"""
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image
model = tf.keras.models.load_model('C:\\Users\\Administrator\\Desktop\\test2\\my_resnet_model_e10bs12.h5')
# # test
img_path = "C:\\Users\\Administrator\\Desktop\\vedio\\2\\338.jpg"
#测试的图片的路径
img = image.load_img(img_path, target_size=(224, 224))
#需要将测试用的1080p的原图缩放为模型匹配的224×224大小图片
plt.imshow(img)
img = image.img_to_array(img)/ 255.0
img = np.expand_dims(img, axis=0) # 为batch添加第四维
print(model.predict(img)) #keras调用模型只需要一个predict函数,非常方便
运行的结果与原图比较如下:
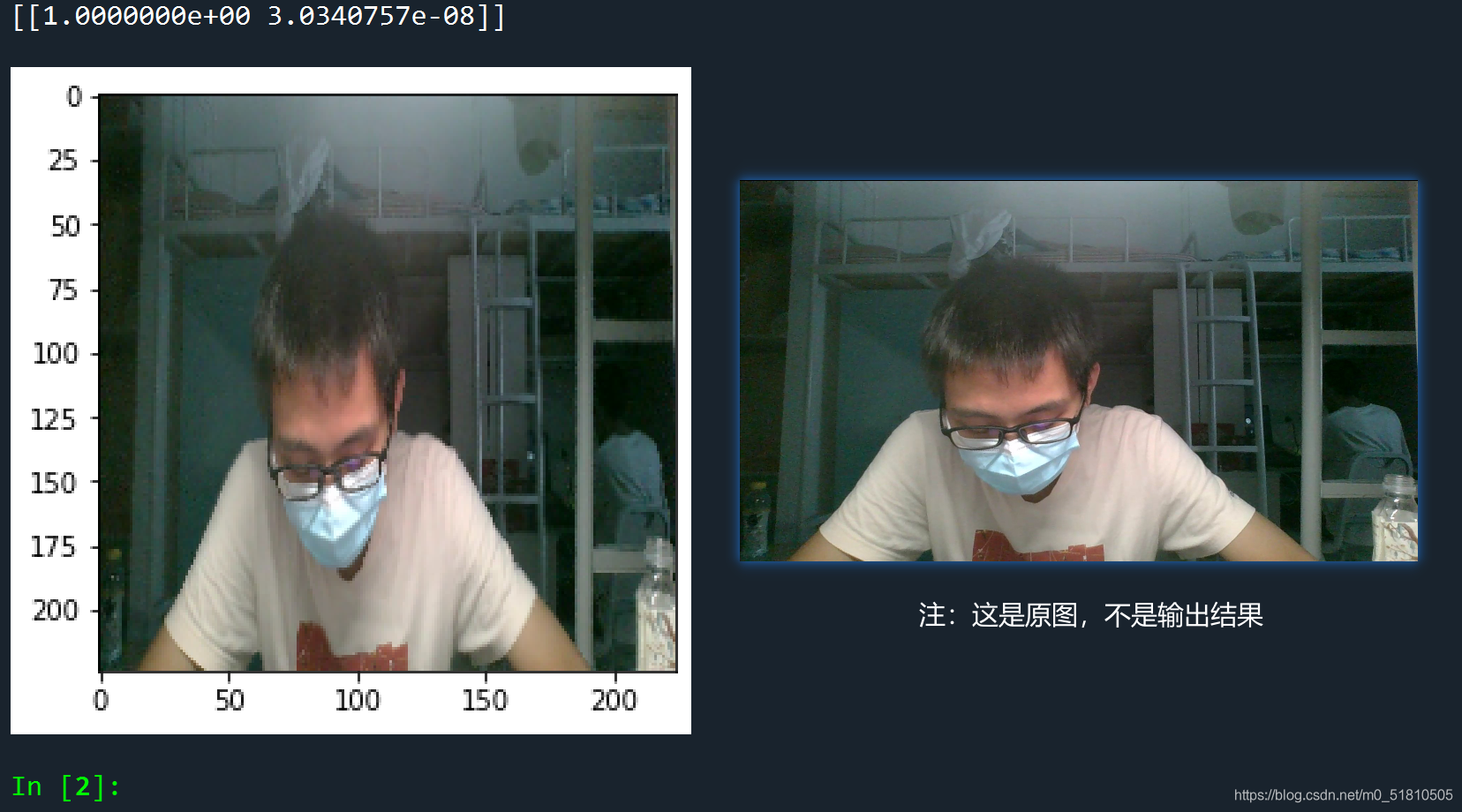
从运行结果可以看出,这张照片的标签被判定为(1,0),属于困。而我选择的图片正是来自有点困状态的文件夹,模型的判断是正确的。
进行到这一步,利用深度学习进行疲劳检测已经取得了初步成功。
2.5 三分类(基于resnet50)
测试二分类成功后,我接着朝着最初的三分类方向改进模型。在博客中已经提到三分类的办法,但是还没有具体 实现。有了二分类的经验,我将模型改为三分类也没有遇到太大的困难。
2.5.1 数据集制作
先给代码:
数据集制作_三分类.py
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 12 12:34:14 2020
@author: xyw
"""
import os
import numpy as np
from tensorflow.keras.preprocessing import image
from PIL import Image
import random
def DataSet():
train_path_k ='C:\\Users\\Administrator\\Desktop\\vedio\\3\\'
train_path_ydk ='C:\\Users\\Administrator\\Desktop\\vedio\\2\\'
train_path_qx = 'C:\\Users\\Administrator\\Desktop\\vedio\\1\\'
imglist_train_k = os. listdir(train_path_k)
imglist_train_ydk = os. listdir(train_path_ydk)
imglist_train_qx = os.listdir(train_path_qx)
#读取文件
X_train = np.empty((len(imglist_train_k) + len(imglist_train_qx) + len(imglist_train_ydk), 224, 224, 3))
Y_train = np.empty((len(imglist_train_k) + len(imglist_train_qx) + len(imglist_train_ydk), 3))
#创建numpy对象,由于是三分类,第四维是3,有三个标签
count1 = 0
# count 对象用来计数,每添加一张图片便加 1
# 遍历困状态下的所有图片并写入训练集
for img_name in imglist_train_k:
img_path = train_path_k + img_name
# 通过 image.load_img() 函数读取对应的图片,并转换成目标大小
# image 是 tensorflow.keras.preprocessing 中的一个对象
img = image.load_img(img_path, target_size=(224, 224))
# 将图片转换成 numpy 数组,并除以 255 ,归一化
# 转换之后 img 的 shape 是 (224,224,3)
img = image.img_to_array(img) / 255.0
# 将处理好的图片装进定义好的 X_train 对象中
X_train[count1] = img
# 将对应的标签装进 Y_train 对象中,困的标签设为(0,0,1)
Y_train[count1] = np.array((0,0,1))
count1+=1 #计数器+1
# 遍历清醒状态的所有图片并写入训练集
for img_name in imglist_train_qx:
img_path = train_path_qx + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_train[count1] = img
Y_train[count1] = np.array((1,0,0))
count1+=1
#遍历有点困状态下所有图片并写入训练集
for img_name in imglist_train_ydk:
img_path = train_path_ydk + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
X_train[count1] = img
Y_train[count1] = np.array((0,1,0))
count1+=1
# 不准备测试集,已经将所有图片写入训练集中
# 打乱训练集中的数据
index = [i for i in range(len(X_train))]
random.shuffle(index)
X_train = X_train[index]
Y_train = Y_train[index]
return X_train,Y_train #Dataset()函数返回两个训练集
X_train,Y_train = DataSet()
np.save('C:\\Users\\Administrator\\Desktop\\test3\\X_train', X_train, allow_pickle=True, fix_imports=True)
np.save('C:\\Users\\Administrator\\Desktop\\test3\\Y_train', Y_train, allow_pickle=True, fix_imports=True)
#保存数据集
print('X_train shape : ',X_train.shape)
print('Y_train shape : ',Y_train.shape)
输出结果:
X_train shape : (2835, 224, 224, 3)
Y_train shape : (2835, 3)
生成的文件:

与二分类时的操作不同,在三分类中,我查阅资料,在调用model.fit()训练模型时,通过validation_split参数来指定从数据集中切分出验证集的比例。也就是让系统在训练时自动将训练集划分一部分作为测试集。这样可以避免像二分类时那样手动划分训练集与测试集,使数据集的划分随机性更强,而且省事。因此我在数据集制作的时候将所有的图片都打包在一个数据集中。
数据集维度定义:
X_train:2835张图片,尺寸224×224,颜色通道rgb3个
Y_train:2835张图片,3个标签
标签:
清醒:qx,(1,0,0), 类别0,图片来自文件夹1
有点困:ydk,(0,1,0 ),类别1,图片来自文件夹2
困:k,(0,0,1),类别2,图片来自文件夹3
完成数据集制作之后,接下来进行模型的训练。
2.5.2 训练模型
先给代码:
resnet训练模型_三分类.py
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 12 12:56:57 2020
@author: xyw
"""
import numpy as np
import scipy
from scipy import ndimage
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.applications.resnet50 import ResNet50
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.resnet50 import preprocess_input, decode_predictions
from keras.callbacks import ModelCheckpoint
# # model
X_train = np.load('C:\\Users\\Administrator\\Desktop\\test3\\X_train.npy')
Y_train = np.load('C:\\Users\\Administrator\\Desktop\\test3\\Y_train.npy')
model = ResNet50(weights=None,classes=3)
model.compile(optimizer=tf.train.AdamOptimizer(0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# # 保存模型路径
filepath='C:\\Users\\Administrator\\Desktop\\test3\\classes=3_times=1_e30bs12\\myresnet50model_3classes_times=1_e30bs12_etimes={epoch:02d}_valacc={val_acc:.2f}.h5'
# # # 需要按命名规则修改文件名(第一处需要修改的地方):classes times epoches batchsize etimes valacc
# # # 需要自己手动按命名规则创建文件夹来存放模型
# 第一种保存方式:有一次提升, 则保存一次.
#checkpoint = ModelCheckpoint(filepath, monitor='val_acc', verbose=1,save_best_only=True,mode='max')
#callbacks_list = [checkpoint]
# 第二种保存方式:保存每一次(我采用的方法)
checkpoint = ModelCheckpoint(filepath, verbose=1,save_best_only=False,save_weights_only=False)
callbacks_list = [checkpoint]
# # train
history=model.fit(X_train, Y_train, epochs=30, batch_size=12,validation_split=0.25,callbacks=callbacks_list)
# # #可以修改的参数(第二个需要改的地方):epoches batchsize validation_split
# # evaluate
# # 第三种保存方式:仅保存最终模型
#model.save('C:\\Users\\Administrator\\Desktop\\test3\\myresnet50model_3classes_times=1_e30bs1_{epoch:02d}etimes_valacc={val_acc:.2f}.h5')
# # # 按命名规则修改(第三个需要改的地方):classes times epoches batchsize etimes valacc
# # draw 并保存图片到文件夹下(手动另存为)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
命名规则(方便后续整理):
例如test3\\classes=3_times=1_e30bs12\\myresnet50model_3classes_times=1_e30bs12_etimes={epoch:02d}_valacc={val_acc:.2f}.h5',其中最后两个参数由模型的callback函数提供,前面的参数由模型参数手动更改。
代表模型存在test3\\classes=3_times=1_e30bs12文件夹下(文件夹需要手动建),三分类,第一次在该参数下进行训练,epochs=30, batch_size=12。
模型的名字myresnet50model_3classes_times=1_e30bs12_etimes=01_valacc=0.32,代表三分类,第一次在该参数下训练得到,epochs=30, batch_size=12,训练的轮数为01,测试集精度为0.32
运行结果(选择了最好的一次):
参数:epochs=30, batch_size=12,validation_split=0.25(划分0.25的数据来作为测试集)
2126/2126 [==============================] - 76s 36ms/sample - loss: 0.5426 - acc: 0.8269 - val_loss: 8.7729 - val_acc: 0.3159
Epoch 2/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.2788 - acc: 0.9101
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.2799 - acc: 0.9097 - val_loss: 2.2470 - val_acc: 0.4175
Epoch 3/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1219 - acc: 0.9586
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1218 - acc: 0.9586 - val_loss: 1.3937 - val_acc: 0.5910
Epoch 4/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1075 - acc: 0.9670
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1075 - acc: 0.9671 - val_loss: 0.6032 - val_acc: 0.8463
Epoch 5/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1129 - acc: 0.9600
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1139 - acc: 0.9595 - val_loss: 0.1106 - val_acc: 0.9704
Epoch 6/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1221 - acc: 0.9647
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1222 - acc: 0.9647 - val_loss: 0.2295 - val_acc: 0.8942
Epoch 7/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0609 - acc: 0.9783
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0622 - acc: 0.9779 - val_loss: 0.9590 - val_acc: 0.8322
Epoch 8/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1305 - acc: 0.9647
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1305 - acc: 0.9647 - val_loss: 0.3354 - val_acc: 0.9055
Epoch 9/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0188 - acc: 0.9944
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0214 - acc: 0.9939 - val_loss: 0.4358 - val_acc: 0.9013
Epoch 10/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0880 - acc: 0.9727
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0879 - acc: 0.9727 - val_loss: 1.8988 - val_acc: 0.7109
Epoch 11/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0343 - acc: 0.9896
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0343 - acc: 0.9897 - val_loss: 0.1955 - val_acc: 0.9140
Epoch 12/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0025 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0025 - acc: 1.0000 - val_loss: 6.6829e-04 - val_acc: 1.0000
Epoch 13/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0143 - acc: 0.9944
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0143 - acc: 0.9944 - val_loss: 2.2343 - val_acc: 0.4034
Epoch 14/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1135 - acc: 0.9609
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1134 - acc: 0.9610 - val_loss: 23.4646 - val_acc: 0.3441
Epoch 15/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0151 - acc: 0.9972
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0151 - acc: 0.9972 - val_loss: 0.0014 - val_acc: 1.0000
Epoch 16/30
2124/2126 [============================>.] - ETA: 0s - loss: 8.6257e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 8.6390e-04 - acc: 1.0000 - val_loss: 7.1752e-04 - val_acc: 1.0000
Epoch 17/30
2124/2126 [============================>.] - ETA: 0s - loss: 4.7914e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 4.9877e-04 - acc: 1.0000 - val_loss: 1.6481e-04 - val_acc: 1.0000
Epoch 18/30
2124/2126 [============================>.] - ETA: 0s - loss: 2.7230e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 2.7305e-04 - acc: 1.0000 - val_loss: 9.6378e-05 - val_acc: 1.0000
Epoch 19/30
2124/2126 [============================>.] - ETA: 0s - loss: 1.0641e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 1.0662e-04 - acc: 1.0000 - val_loss: 8.4853e-05 - val_acc: 1.0000
Epoch 20/30
2124/2126 [============================>.] - ETA: 0s - loss: 1.4195e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 1.4551e-04 - acc: 1.0000 - val_loss: 1.1583e-04 - val_acc: 1.0000
Epoch 21/30
2124/2126 [============================>.] - ETA: 0s - loss: 6.5002e-05 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 6.4958e-05 - acc: 1.0000 - val_loss: 8.6277e-05 - val_acc: 1.0000
Epoch 22/30
2124/2126 [============================>.] - ETA: 0s - loss: 8.2017e-05 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 8.2002e-05 - acc: 1.0000 - val_loss: 7.6832e-05 - val_acc: 1.0000
Epoch 23/30
2124/2126 [============================>.] - ETA: 0s - loss: 4.4426e-05 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 4.7932e-05 - acc: 1.0000 - val_loss: 6.7494e-05 - val_acc: 1.0000
Epoch 24/30
2124/2126 [============================>.] - ETA: 0s - loss: 4.0728e-05 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 4.0696e-05 - acc: 1.0000 - val_loss: 8.3068e-05 - val_acc: 1.0000
Epoch 25/30
2124/2126 [============================>.] - ETA: 0s - loss: 3.0508e-04 - acc: 1.0000
2126/2126 [==============================] - 49s 23ms/sample - loss: 3.5365e-04 - acc: 1.0000 - val_loss: 5.0472e-04 - val_acc: 1.0000
Epoch 26/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.2603 - acc: 0.9218
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.2606 - acc: 0.9214 - val_loss: 358.0750 - val_acc: 0.3794
Epoch 27/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.1260 - acc: 0.9647
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.1259 - acc: 0.9647 - val_loss: 1.3363 - val_acc: 0.7094
Epoch 28/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0323 - acc: 0.9882
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0329 - acc: 0.9878 - val_loss: 0.0061 - val_acc: 0.9986
Epoch 29/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0403 - acc: 0.9873
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0402 - acc: 0.9873 - val_loss: 1.3600 - val_acc: 0.7094
Epoch 30/30
2124/2126 [============================>.] - ETA: 0s - loss: 0.0235 - acc: 0.9911
2126/2126 [==============================] - 49s 23ms/sample - loss: 0.0235 - acc: 0.9911 - val_loss: 0.9180 - val_acc: 0.7884
下面是输出的acc与loss变化图:
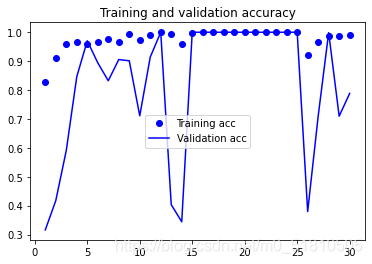
得到的模型文件一览(每轮训练都保存):
分割线
在模型训练这一步,我针对原先二分类时保存模型的问题做了改进。原先的博客只在训练完成后保存最终的模型,然而最后一个模型并不一定是最好的模型。在最开始的几次训练里,出现了这样的结果:
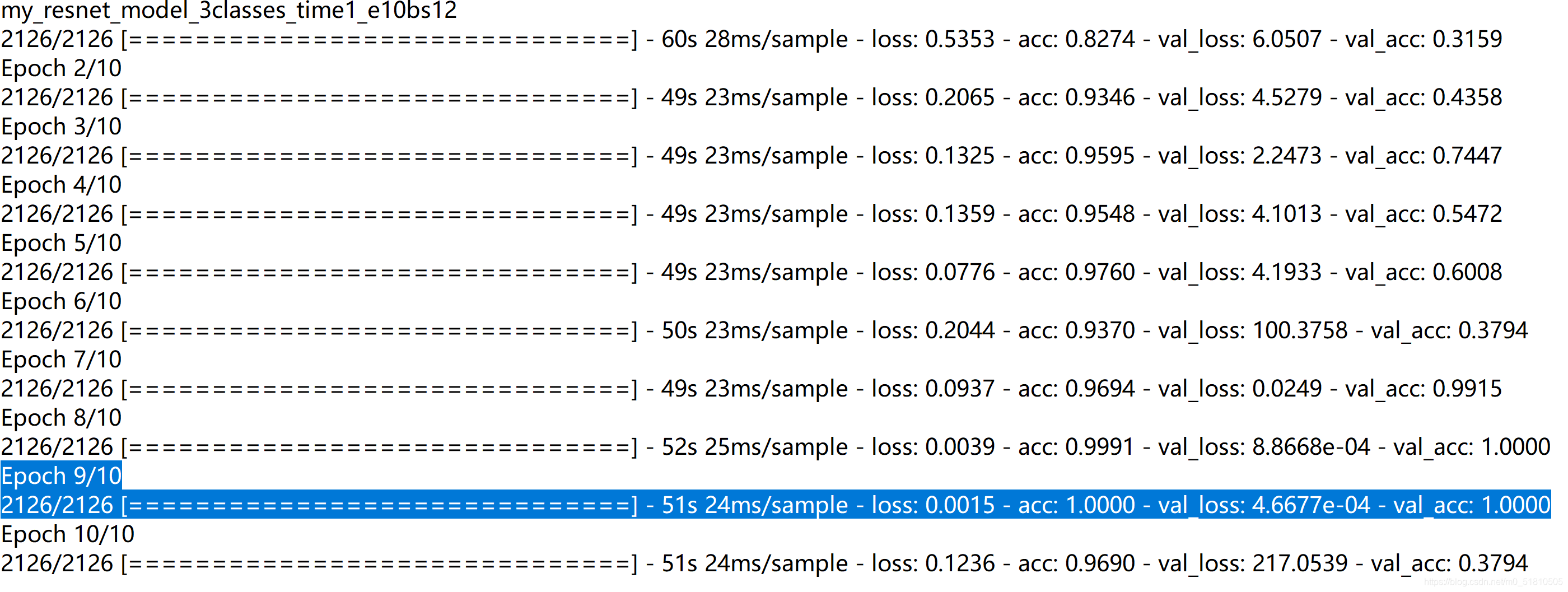
本来在第九轮训练出了一个val_acc=1模型,可是在第十轮的时候val_acc骤降到0.3794,然而我这时用的是之前博客的代码,所以只保存了最后的第十轮的模型,非常裂开!于是我查阅资料,找到了使用Callbacks函数,保存每一次训练的模型或者所有有提升的模型的方法。
保存模型:
Keras如何保存每轮(每个Epoch)训练后的模型?
Keras回调函数Callbacks使用详解及训练过程可视化
可以看到,在改变分类策略,改变数据集划分方法(增加划分随机性)后,训练的结果大大改善。有一段时间可以收敛得到到的acc与val_acc=1.0000的模型,也就是百分之百可以在训练集与测试集上成功分类!而且loss也非常低。我重复训练了多次,基本上每次训练都可以训练出acc达到1的模型。可以说,单看训练结果,这个模型的理论效果是极好的。
但是由于数据集过小的问题,模型自然是出现了严重的过拟合,鲁棒性很差!经过我后续的实际测试,这个模型只能在数据集上进行正确度极高的分类,一旦采用其他照片,分类的效果就不尽人意。
改进的方法也是老生常谈:增大数据集、进行数据增强。但是由于时间关系以及条件限制,我没有做进一步的改善。
由于训练模型之后,显存与内存都不会自动清空(特别是显存,每次训练都被吃满6g),所以每次训练完都要重启spyder才能进行下一步的训练,比较不爽。所以我就查阅资料,找到了清空显存的办法。不过这个代码执行完后,gpu无法调用,还是需要重启,所以就算了。内存的清空似乎没有很干脆的方法(大概把读进内存的数据集变量del就行了?),而且我的内存足够跑三次训练,就跳过了。
清理显存:
python – Keras:完成训练后释放内存
最后放一下我存放所有训练过的模型的文件夹:

接下来,进入调用模型进行检测的步骤。
2.5.3 调用模型
先给代码:
检测模型_test3.py
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 12 22:12:38 2020
@author: xyw
"""
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image
model = tf.keras.models.load_model('C:\\Users\\Administrator\\Desktop\\test3\\classes=3_times=1_e30bs12\\myresnet50model_3classes_times=1_e30bs12_etimes=23_valacc=1.00.h5')
#选择导入的模型
# # test
img_path = "C:\\Users\\Administrator\\Desktop\\vedio\\3\\338.jpg"
img = image.load_img(img_path, target_size=(224, 224))
plt.imshow(img)
img = image.img_to_array(img)/ 255.0
img = np.expand_dims(img, axis=0) # 为batch添加第四维
predict = model.predict(img)
print(predict) #预测标签
predict=np.argmax(predict,axis=1)
print(predict) #预测类别
输出的结果为:
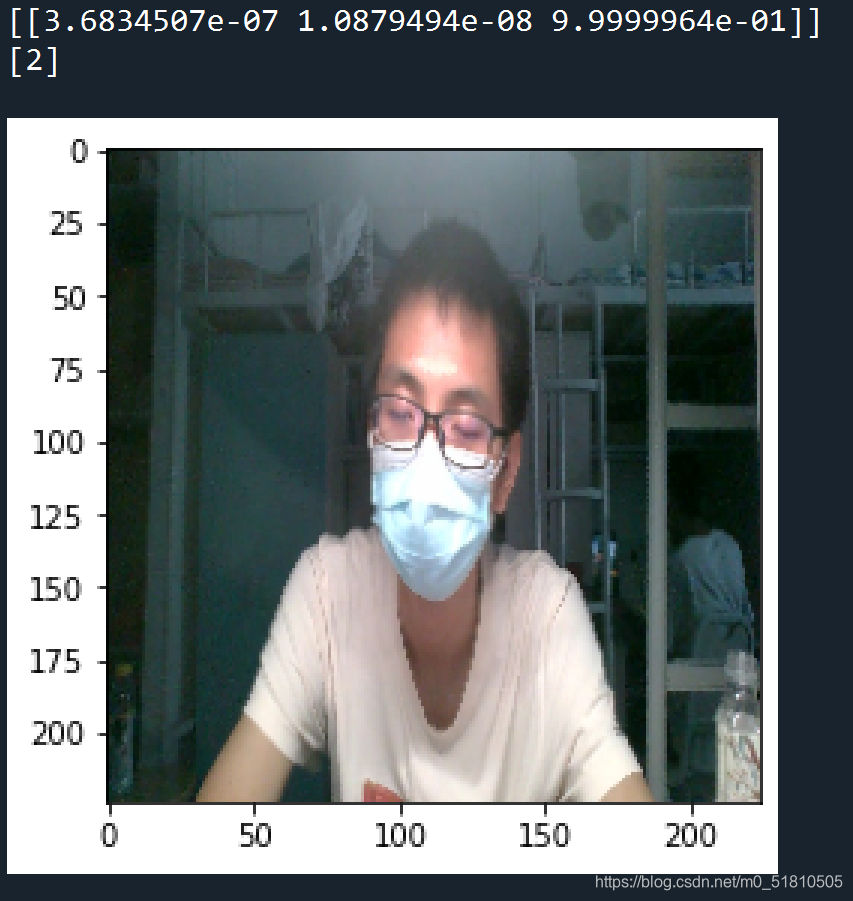
我调用的模型是myresnet50model_3classes_times=1_e30bs12_etimes=23_valacc=1.00.h5,这是所有模型中loss最低,acc最高的一个模型。
我选择的图片位于vidio\3\338,是一张困的图片,预测的标签为(0,0,1),预测的类别为2,结果正确。(状态与标签、类别的对应见2.5.1的定义)
经过实测,模型在数据集范围内是可用的。
接下来的工作就是将调用模型的代码打包,整合为一个可以实时预测驾驶员状态的代码文件了。
2.6 成品——整合检测模型(三分类)
先给代码,这个代码只是将数据集提取与调用模型整合了一下,改成了从摄像头定时拍照,并且加了一个循环用的函数来实现持续的检测。
整合检测模型.py
# -*- coding: utf-8 -*-
"""
Created on Fri Nov 13 14:40:29 2020
@author: xyw
"""
'''1、引入函数'''
import time
import cv2
import os
import shutil
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing import image
'''2、制作数据处理模块函数,思路:获取图片缓存--逐张检测--清缓存'''
def capimage(outPutDirName,img_num): #从摄像头提取图片的函数,两个参数分别是缓存文件夹路径、提取图片总数
print('start')
times=0
#提取视频的频率,每1帧提取一个
frameFrequency=1
#输出图片到当前目录vedio文件夹下q
if not os.path.exists(outPutDirName):
#如果文件目录不存在则创建目录
os.makedirs(outPutDirName)
camera = cv2.VideoCapture(0) #调用摄像头
while True:
times+=1
res, image = camera.read()
if not res:
print('not res , not image')
break
if times%frameFrequency==0 and times*0.1==int(times*0.1):
cv2.imwrite(outPutDirName + str(int(times*0.1))+'.jpg', image)
#每遍历10帧保存一张图片,可以修改times的倍率来修改提取的帧数间隔(提取速度)
print(str(int(times*0.1)))
if int(times*0.1)==int(img_num) :
break #如果提取的图片数=预设需要提取的总图片数,则打破循环。
print('图片提取结束,共'+img_num+'张')
camera.release()
def delateimage(outPutDirName): #用于清空缓存文件夹的函数
shutil.rmtree(outPutDirName)
os.makedirs(outPutDirName)
print('已清空cache文件夹')
'''前面是用摄像头采集图片缓存与清缓存,这个是测试函数'''
def test(cache_path,model_path): #用于调用模型预测的函数,
#两个参数是缓存文件夹路径(存有待预测的全部图片,与上面的文件夹是同一个)、调用模型文件的路径
pre_list=list() #用来保存预测结果的列表
model = tf.keras.models.load_model(model_path) #加载模型
for img_name in os.listdir(cache_path): #调用模型
img_path = cache_path + img_name
img = image.load_img(img_path, target_size=(224, 224))
img = image.img_to_array(img) / 255.0
img = np.expand_dims(img, axis=0) # 为batch添加第四维
predict = model.predict(img)
print(predict)
predict=np.argmax(predict,axis=1)
print(predict) #输出单张图片预测结果
lable=int(predict)
pre_list.append(lable) #将结果加入预测列表
print(pre_list) #输出预测结果列表
'''3、现在开始运行文件,确定三个参数'''
img_num = '10'
##修改这个参数来确定提取多少张图片-1
cache_path='C:\\Users\\Administrator\\Desktop\\test3\\cache\\'
##这是缓存文件夹的路径参数-2
model_path = 'C:\\Users\\Administrator\\Desktop\\test3\\classes=3_times=1_e30bs12\\myresnet50model_3classes_times=1_e30bs12_etimes=23_valacc=1.00.h5'
##这是预测选用的权重文件的路径参数-3
def loopMonitor(): #循环器函数,能够实现让内部的函数每隔一段时间运行一次的功能,即实现持续检测
while True:
capimage(cache_path,img_num) #若是使用自带的已经全部是待检测图片的文件夹(自带检测集)而非摄像头,则不要运行这个,直接使用test函数即可
test(cache_path,model_path) #若是使用自带检测集,则cache改为文件夹路径
delateimage(cache_path) #若是使用自带检测集,则千万不要运行这个,否则会清空文件夹
##下面是定时循环器,里面的参数是等待秒数,用time.sleep函数可以每隔一段时间做一次检测,这样循环是为了能随时用ctrl+c打断运行
print('wait...')
for i in range(30):
time.sleep(1)
loopMonitor() ##运行循环器函数(内部打包了其他函数)
我使用摄像头,对自己目前的状态进行判断,结果如下:
start
1
2
3
4
5
6
7
8
9
10
图片提取结束,共10张
[[1.8995142e-05 2.9743055e-04 9.9968362e-01]]
[2]
[[1.7572362e-06 9.3681127e-01 6.3186973e-02]]
[1]
[[1.0628138e-06 9.4999039e-01 5.0008602e-02]]
[1]
[[1.5084094e-06 9.2358166e-01 7.6416746e-02]]
[1]
[[6.7236647e-06 8.0073249e-01 1.9926082e-01]]
[1]
[[1.8759165e-06 9.3310726e-01 6.6890813e-02]]
[1]
[[1.3127151e-06 9.5798534e-01 4.2013396e-02]]
[1]
[[6.7462111e-07 9.6975416e-01 3.0245209e-02]]
[1]
[[2.6920061e-06 9.2666048e-01 7.3336884e-02]]
[1]
[[3.8068411e-06 8.9639020e-01 1.0360592e-01]]
[1]
[2, 1, 1, 1, 1, 1, 1, 1, 1, 1]
已清空cache文件夹
wait...
KeyboardInterrupt
这个检测器是使用capimage函数抓取一些照片,并存在缓存文件夹中,然后利用test函数调用模型,对缓存文件夹中的照片进行预测并输出结果。在预测完之后会清空缓存文件夹,以便执行下一个循环。(为了方便调试,将照片写入硬盘的缓存文件夹中而非内存,这一点可以改进,避免在硬盘上进行过多擦写)
按照loopMonitor的参数,每30秒会执行一次上述循环。我在控制台界面输入ctrl+c终止了该函数。这一点参考了以下网页:
利用这个函数,在实际运行时可以使这个检测器不断运行,实现每隔30s检测输出一次的功能。因为在time.sleep函数运行过程中时,只能等到时间结束,控制台才能用ctrl+c打断运行,所以使用了一个for循环方便打断。
理论上,利用最后的结果列表pre_list,就可以判断目前摄像头拍到的照片所处的状态。但是实际上并不能做到成功的预测,原因前面解释过,是数据集的问题。另外的改进方法是使用人脸识别器,在数据集制作与检测时将人脸单独提取出来进行使用,应该能够提高精度。
写到这里,我最主要的工作就介绍完毕了,开心!
下面我将简单梳理一下深度学习方法进行疲劳检测的基本思路。
2.7 深度学习方法小结
2.7.1 文件结构
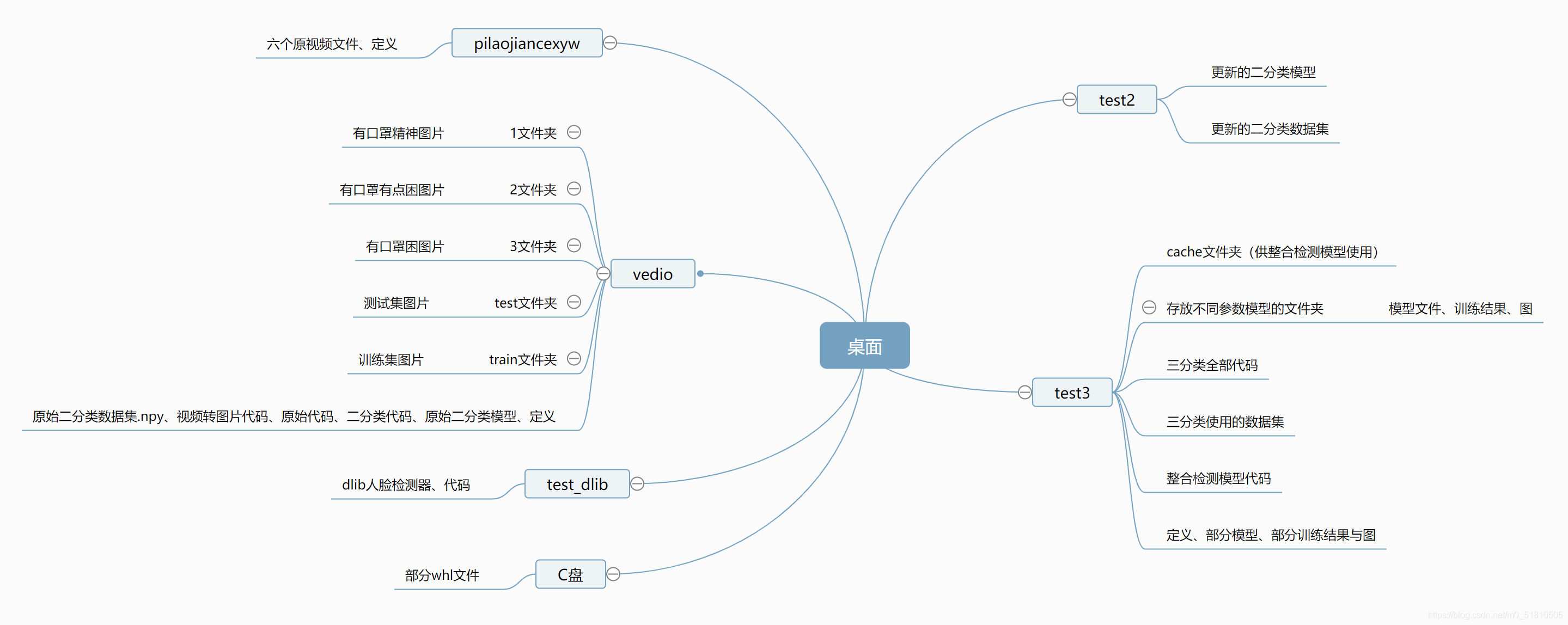
2.7.2 整体思路
原始视频 --> 数据预处理:opencv视频转图片.py --> 三种状态的图片 --> 数据集制作_三分类.py --> 数据集文件.npy --> resnet训练模型_三分类.py --> 可用的模型文件.h5 --> 进行实时疲劳检测:整合检测模型.py
2.7.3 改进方向
1、增大数据集,使用更多人、更多场景、更多角度、更多光线条件下的图片进行训练。
2、使用人脸检测器,提取人脸照片来进行训练与检测,与普通的检测模型结合使用。(为了不丢失体态、低头信息)
3、进行数据增强
4、改进神经网络模型,可以使用其他的神经网络模型或微调模型。
5、增加时间维度,结合动作检测,使用视频片段进行训练。这样能够保留动作与时序信息,效果应该更好,而且还能顺便检测其他危险驾驶行为。本来想尝试一下,不过查阅资料以后感觉能力不够,搞不出来,遂放弃。
视频片段识别与行为检测的一些综述:
驾驶员行为检测+疲劳驾驶
人工智能竞赛-行为识别参赛总结
视频的行为识别
PA3D-基于姿态的3D视频行为识别网络
三、dlib方法
3.1 问题所在
在完成了深度学习方法的疲劳检测后,我重新回到了dlib上。由于在编译上实在没什么办法,所以我想到了另一个途径——万能的淘宝。
我在淘宝上咨询了一下,得到了这个结果: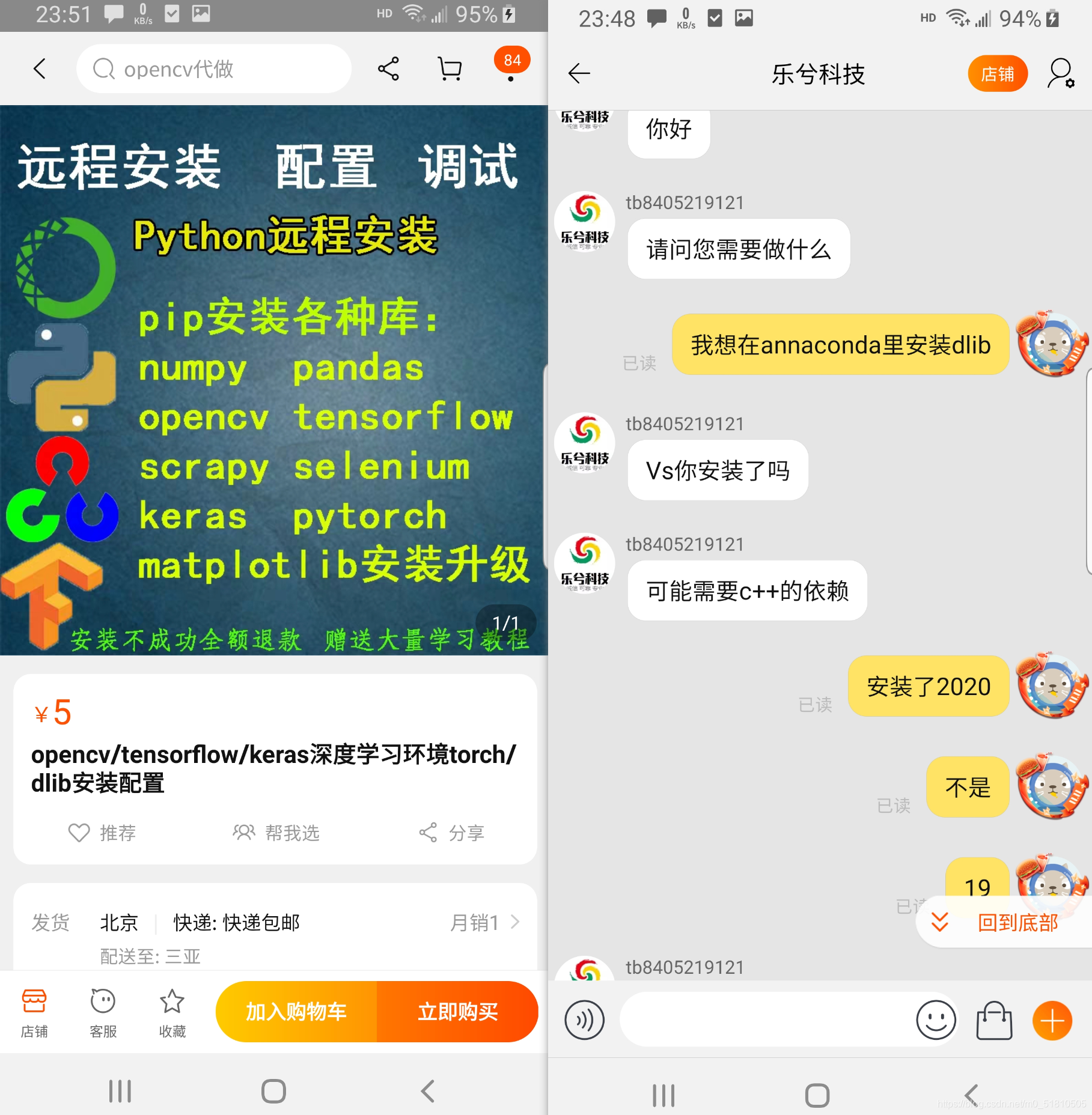
我之前在安装dlib的时候也按照一些教程安装了vs2019,不过当时在里面安装的是python,没有安装c++。(查到的资料只提到要安装vs,没有更进一步的说明,我太菜了。。)看到这里之后,我去vs里又把c++安装了一下。然后我卸载用whl装的dlib库,重新用pip install安装。在经过漫长的等待后,居然成功了。。。
当时人傻了,很无语,折腾了这么久,问题居然就这?
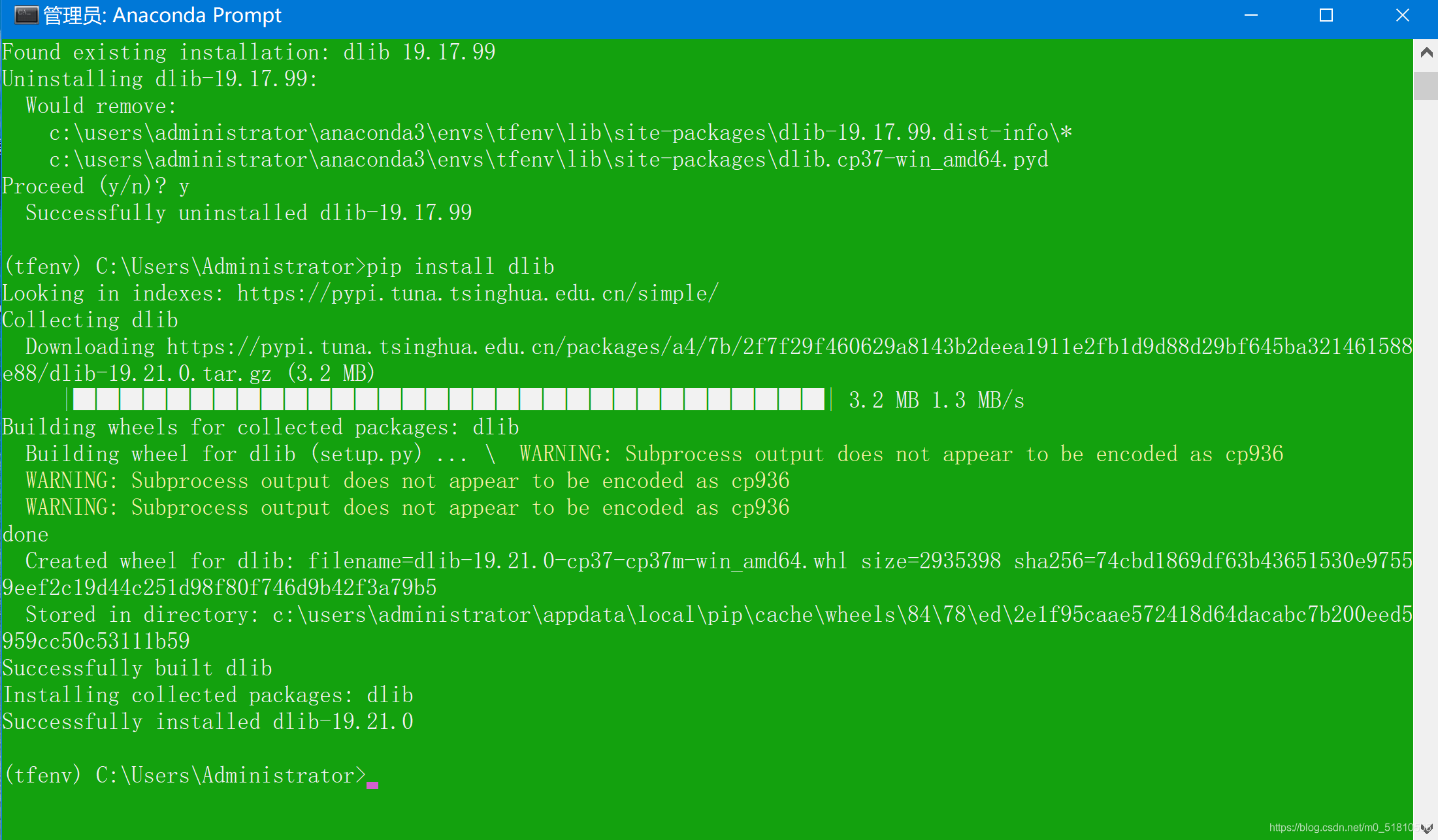
既然装好了dlib库,那么dlib方法也可以尝试一下了。
3.2 dlib疲劳检测
实测能用。
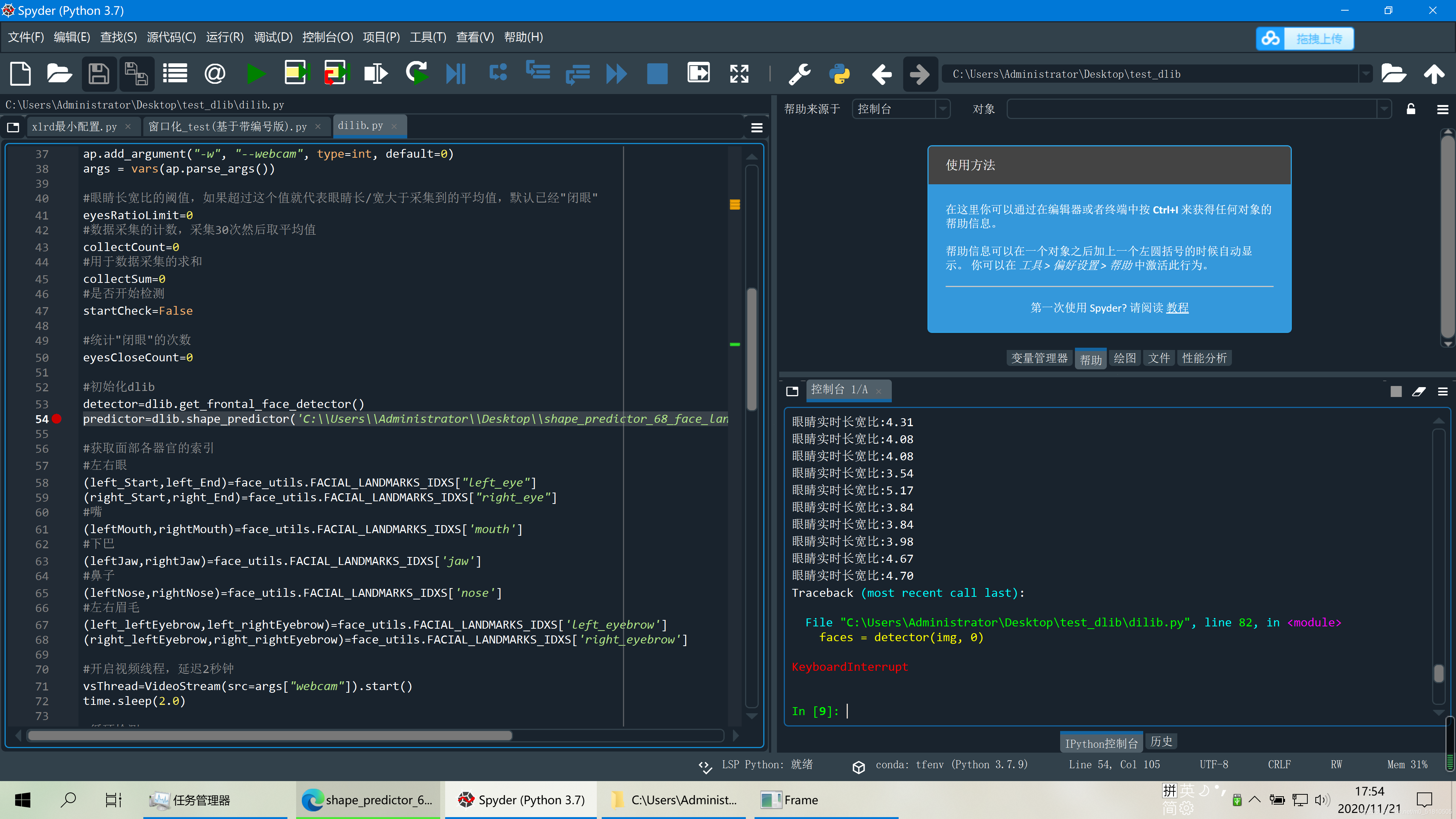
应该可以用dlib库来提取人脸,实现上文说的,在采集数据时单独提取使用人脸照片,进行训练与检测。不过由于时间关系,在dlib方法上,我没有做进一步的尝试了。
后记
本次的探索性实验开始于大二上学期第六周周五,本来应该是搞三周的,但是我在课余时间陆陆续续搞了挺久。我在第八周周三开始决定尝试深度学习,在10月30日周五配好环境,在11月12日做出了最终的成品,在11月21日终于安好了dlib。在尝试的过程中,我遇到了很多困难,踩了很多坑,最终做出了一个理论上可行的成品,也算完成任务了吧。
对我而言,这次的实验更大的意义是让我有了一个契机去学习一些课程之外的东西,而且我在不断学习尝试成功的过程中也挺开心,挺有成就感的,同时也打发了时间 ,这也是我在课余时间做下去的动力。
由于这次实验的过程非常曲折,做的挺开心,放寒假也没事干,有时间,我就决定试着将所有细节与读过的内容都写进报告里,既是纪念,也方便以后翻看。因此这个实验报告写的很长,也有很多口语化、情绪化的表达。我可能会将主要的部分挑出来复制粘贴,写一份简洁一些的报告,可能也方便老师学长交差 。同时学期结束后我大概要换电脑了,到时候要重新安装环境,免不了一番折腾,所以我才在安装上写了比较长的篇幅(对我来说,安装的过程比正式工作的部分还要困难)。把代码与读过的内容保存一下,也方便以后参考。
最后,衷心感谢黄玲老师提供了这次实验的机会,也衷心感谢洪佩鑫师兄在我遇到困难时无私的帮助我,希望大家新年快乐,来年一切顺利。
完结撒花~~
最后编辑于:2021.1.17 13:18















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









