






WEB 通用
NIO,AIO,BIO,同步异步
HTTPS
- HTTP 由于是明文传输,主要存在三大风险:窃听风险、篡改风险、冒充风险。
- 中间人攻击
- 钓鱼网站
- https
- 秘钥交换,非对称加密
- 数据通信,对称机密
- https建立链接过程
TLS 的密码套件命名非常规范,格式很固定。基本的形式是密钥交换算法 + 签名算法 + 对称加密算法 + 摘要算法,比如刚才的密码套件的意思就是:
握手时使用 ECDHE 算法进行密钥交换,用 RSA 签名和身份认证,握手后的通信使用 AES 对称算法,密钥长度 256 位,分组模式是 GCM,摘要算法 SHA384 用于消息认证和产生随机数。
HTTP1.0/1.1/2.0
- 1.0 短连接,不支持keepalive
- 1.1
- 支持并默认开启keepalive ,关闭是短连接
- 缓存优化
- 断点续传优化, 206 请求部分资源
- 新增 PUT。DELETE,OPTIONS,TRACE, 请求方式
- Host 优化
- 支持只发送header
- 2.0
- 多路复用,基于requestId 实现多个请求复用同一链接
- 支持header 压缩
- 服务端推送
- 只能推送静态资源
- 二进制协议,1.1是文本协议
WebSocket
- http 是半双工, tcp 是 全双工, websocket 是全双工
- 因为各个浏览器都支持HTTP协议,所以websocket会先利用HTTP协议加上一些特殊的header头进行握手升级操作,升级成功后就跟HTTP没有任何关系了,之后就用websocket的数据格式进行收发数据。
常见状态码
- 499 客户端断开连接,一般可能是后端接口太慢
- 502 bad gateway , 后端服务不可用
- 540 gateway timeout ,后端服务超时
- 401 未授权
- 301 永久重定向
- 302 临时重定向
- 304 使用缓存的资源
TCP 相关
- 三次握手
- 四次挥手
- 拥塞控制
一次链接的访问过程
- 域名解析
- 浏览器dns缓存
- 系统DNS缓存
- 本地host文件
- 本地DNS解析IP (递归查询)
- 跟或其他DNS服务器 (迭代查询)
- 基于IP 建立链接
- https ssl/tls 握手
- ws 握手升级
- 发送请求
- 浏览器渲染视图
- cdn 请求静态资源
CPU 相关
业务架构设计的思考
- 业务解耦,但也不能脱离业务
- saas多租户
- 染色请求
- 队列解耦
- 柔性服务
- 削峰填谷
- 有损服务
- 预防雪崩
- 黑白名单
- 基础架构
- 线程池相关优化
- 无锁队列
- 任务窃取
- 延迟聚合队列
- 动态可监测
- 批量
- 数据源
- 动态可检测
- sql预检
- 分库分表
- 加密
- mybatis Auto 忽略主键
- 分布式主键id
- 通用组件
- 分布式锁
- 异步修复
- aop排序
- reqCache
- 重复提交
- 消息事务
- 消息 Listener Sender
- Sentinel APT组件
- 预热 APT组件
- spring bean替换
- spring 固定配置可变
- springboot 自定义排除扫描路径
- 动态配置
- 无注解 swager 注释集成
- 优雅关机, 中断指令
- RPC框架
- 可扩展header
- SkyWalking
- 可中断
- 无损停服
- 线程池相关优化
java 基础
jvm
内存结构
gc算法
- 常见oom
- 三色算法
CMS:写屏障 + 增量更新
G1、Shenandoah:写屏障 + 原始快照
ZGC:读屏障
上面的的方案为啥是这样的,你有想过为什么吗?
原始快照相对增量更新来说效率更高(当然原始快照可能造成更多的浮动垃圾),因为不需要在重新标记阶段再次深度扫描被删除引用对象。
而 CMS 对增量引用的根对象会做深度扫描,G1 因为很多对象都位于不同的 region,CMS 就一块老年代区域,重新深度扫描对象的话 G1 的代价会比 CMS 高,所以 G1 选择原始快照不深度扫描对象,只是简单标记,等到下一轮 GC 再深度扫描。
反射机制
语法糖
常见设计模式
spring
常见问题
- aop 失效
- 作用域
- Controller 作用域
- this 调用
- init-method 自调用,导致 aop 失效
- 循环依赖
- 三级缓存
- Lazy
- ConditionalOnBean 失效
- 原型 destory 无效
- destroy bean NotFound ,用 ContextClosedEvent 解决
- destroy 串行执行耗时久
- init-method 耗时长
- init-method 无序执行,依赖没有准备好的资源, 用ContextRefreshedEvent 解决
- 静态成员变量导致 依赖关系混乱,导致启动过程中出现空指针
- bean 顺序不可控
- Binder 不支持 大写字符
- 中间件 AOP 顺序不可控
- 单例 成员变量导致多线程出错
spring mvc 执行原理
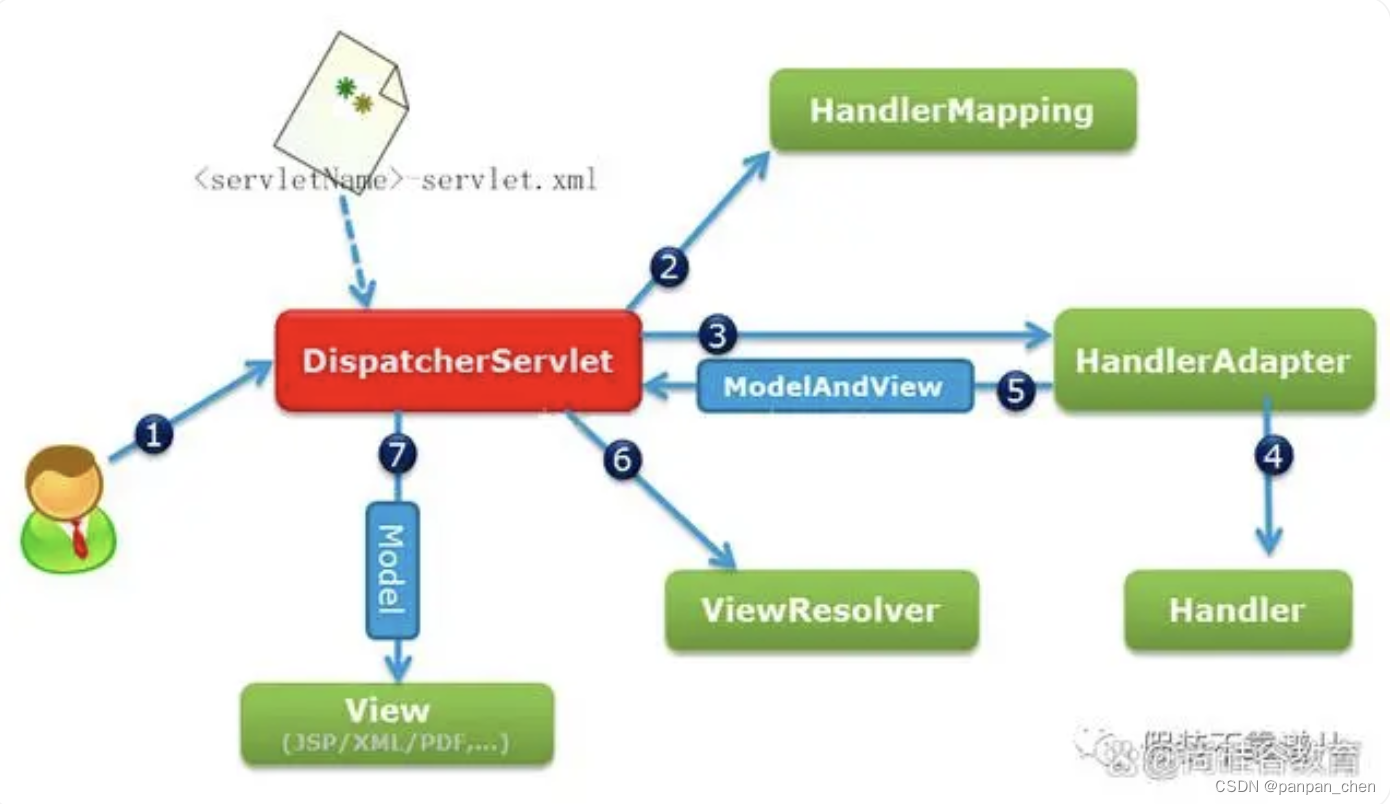
-
- DispatchServlet
- 2.HandlerMapping[] (RequestMappingHandlerMapping)
- MappingRegistry
- 基于URL 匹配 HandlerMehod
- MappingRegistry
- getHandler, HandlerExecutionChain
- 构建拦截器
- 3.getHandlerAdapter RequestMappingHandlerAdapter
applyPreHandle 前置拦截器返回false 直接return- 4.HandlerAdapter.handler
invokeHandlerMethod 不同于aop的动态代理,直接反射调用 Method, 所以 private 的能正常调用,bean 空指针- 5.return ModelAndView
- applyPostHandle (HandlerInterceptor) 后置拦截器
- processDispatchResult
- 6.ViewResolver
- 7.view.render
设计模式
- beanFactory 工厂模式
- getSingleton 单例模式
- aop 代理模式
- event 观察者模式
- Filter 职责链模式
- AdvisorAdapter,HandlerAdapter 适配器模式
- 主要是把把源接口转换成目标接口
- DispatcherServlet,TypeConverterSupport 委派模式
- DispatcherServlet中的多个HandlerMapping 策略模式
- BeanWrapper 装饰器模式
- 装饰器模式主要是给对象添加新的行为,,代理模式是对行为的扩展
- JdbcTemplate TransactionTemplate,RestTemplate,RedisTemplate 模板方法
- 定义算法的骨架,将实现推迟到子类实现
mybatis
常见问题
- mapper location 绑定错误 ,导致 not found
- update set null 失效
- auto主键, 高版本语义混乱
- sql 注入 ${}
- 分页缺少 page拦截器
- 批量插入没有开启优化配置 rewriteBatchedStatements
- update 更新影响行数 useAffectedRows
- 链接池初始化耗时长
- 连接泄露
- 慢查询,导致链接用尽,导致雪崩
- 一级缓存导致重复读
- autocommit 导致多次IO请求
- mybatis 无效sql 发送远端,无效IO
- mybatis console log 导致程序性能
- mybatis ServiceImpl 默认使用事务,复杂度高,不支持多数据源
- mapper 方法名不可重载
- @Param缺失 或者 编译的时候没有编译参数名,导致 参数不存在
- 时区,编码 问题
- utf8 不支持表情
mysql
常见问题
- 索引失效
- 函数
- 类型转换
- not in !=
- 索引识别错误
- 强制索引
- 组合索引
- limit 深分页 导致 扫描行数太多
- select * 导致无效回表
- 索引过多,导致更新性能下降
- 数据过多,导致索引匹配多次磁盘IO
- 改表导致锁表
- 改表导致binlog 程序 qps 高
- 碎片整理
- 大事务
- slow query
- cpu 过高
- too many connection
- 超过innodb_thread_concurrency时,等待
- sleep 链接
- slow query
- 全表更新
- 添加 limit
- sql预检
- sql_safe_updates 服务端保护
- io 忙定位
- iotop
- select * from performance_schema.threads where thread_os_id=37012
B+树能存多少数据


锁
- 意向锁
- 排他锁
- 共享锁
- 间隙锁
- next-key lock
- insert intention lock

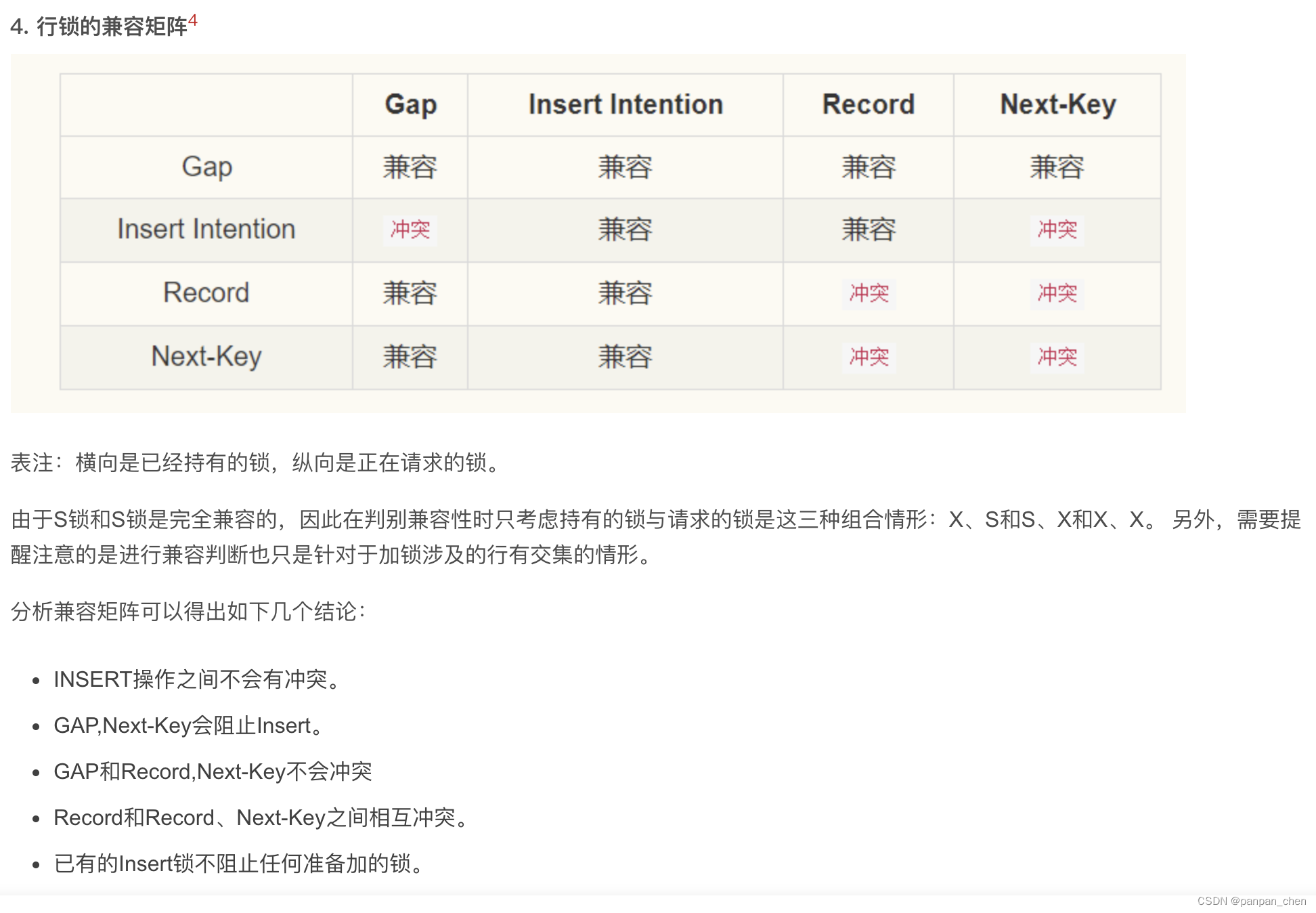
事务隔离级别
- 读未提交(Read Uncommitted)。这是最低的隔离级别,允许事务读取其他未提交事务的数据。这可能导致脏读、不可重复读和幻读问题。
- 读已提交(Read Committed)。在该级别下,事务只能读取已经提交的数据。这避免了脏读问题,但仍然可能存在不可重复读和幻读问题。
- 可重复读(Repeatable Read)(mysql 默认)。在该级别下,事务在执行过程中多次读取相同的数据时,能够保证数据不会被其他事务修改。这避免了脏读和不可重复读问题,但仍然可能存在幻读问题。
- 串行化(Serializable)。这是最高的隔离级别,事务会按顺序一个接一个地执行,不允许并发执行。这可以避免脏读、不可重复读和幻读等并发问题,但会降低系统的并发性能。
RR 加锁说明
- 锁是在索引上实现的
- 假设有一个key,有5条记录, 1,3,5,7,9. 如果where id<5 , 那么锁住的区间不是(-∞,5),而是(-∞,1],(1,3],(3,5] 多个区间组合而成
- RR隔离级别使用的是:next-key lock算法,即:锁住 记录本身+区间
- next-key lock 降级为 record lock的情况
如果是唯一索引,且查询条件得到的结果集是1条记录(等值,而不是范围),那么会降级为记录锁
典型的案例:where primary_key = 1 (会降级), 而不是 where primary_key < 10 (由于返回的结果集不仅仅一条,那么不会降级) - 上锁,不仅仅对主键索引加锁,还需要对辅助索引加锁,这一点非常重要
MVCC
- snapshot查询不会加锁,读和读,读和写之间互不影响,提高数据库的并发能力
- 隔离级别的实现
- readview = 活跃事务列表
readview(RR): 事务开始时产生readview
readview(RC): 每条语句都会产生readview
redis
集群
数据结构
常见应用
常见问题
-
oom
- excel 导出
- 流式处理
- 频次限制
- 全表
- 消息队列本地buffer
- 线程池默认队列
- 堆外内存泄露
- 中间件
- 线程创建过多
- 单例重复创建 httpclient
- hystrix配置太大
- excel 导出
-
慢接口
- 日志过多
- 同步日志
-
nginx
- request_time upstream_time
- accept队列阻塞
- ss -nltp (not accept)
-
慢sql
-
业务线程池
-
ForkJoinPool
-
第一次请求
-
任务积压
- 第三方慢
- 分布式锁
- binlog 该表
- cas冲突率
- 线程池设置
-
tcp
- 内存
- time_wait 时 只有 152 byte
- time_wait 过多
- lsof ss 命令变慢
- 创建链接变慢
- tcp_max_tw_buckets
-
close_wait 过多
- httpclient 链接没关闭
-
keepalive
- lvs 关闭链接
- cpu
- HugePages
- numa
- nginx
- accept_mutex 惊群(开启cpu小,关闭吞吐量高)
- dyups 热更新
-
cpu 100%
- 正则回溯
- io中断默认绑定单核
- 绑定多核
-
sync丢包
- 短连接
- somaxconn太小
- 端口复用
- 日志过多
- cache,buff,flush间隔
- time_wait 优化(NAT网丢包)
-
worker_shutdown_timeout
- websocket
-
buddyinfo 伙伴内存系统 导致内存分配失败
- 提前启动kswapd
- extra_free_kbytes
- min_free_kbytes
- 日志文件缓存
-
server-sock(listen) 单进程
- 增加 rcvbuff,sendbuff
- reuseport
-
netty
- 异步事件模型实现异步非阻塞IO模型
- 内存池
- mmap
- buffer 过大 导致 oom-killer
- ssl Record buffer=16384 实际上512 就够了
- 百万链接时候,内存消耗多
- 耗时任务,io线程阻塞 (https://blog.csdn.net/liangwenmail/article/details/120153746)
- 没有使用 subRefactor 模型
- ssl加密算法优化耗时
- DH(600),ECDH(1400),AES(2100)
- 指定优先使用RSA
-
redis
- jedis BIO
- lettuce netty NIO
- 链接池归还失败
- scan 需要显示关闭链接
- jar 版本冲突
-
sharding-jdbc
- 动态类导致 元空间溢出
- 翻页问题
- 多路由策略
-
elasticSearch
- 分区太多,导致查询慢
- flush 太慢导致,查询延迟
- flush 太快,影响写的吞吐量
- 管理节点和数据节点分离
- 深分页导致慢查询
- termIndex(跳表 FST),dicIndex(二分查找),数据合并(跳表),查询缓存(Roaring bitmap),LSM-Tree(结合WAL)
-
clickhouse
- MPP
- 列式存储
- LSM (https://zhuanlan.zhihu.com/p/415799237)
- 类SQL
- client max_threads 越小qps越高,默认cpu核数
-
hbase
- zookeeper
- RegionServer
- WAL
- MemStore->HFile
- Region 阈值(5G) 水平切分
- 列簇
- 本质上还是行式存储,除非每个列是单独的列簇
-
lsm
- 更高的写性能
- 没有修改,只有新增
- MemStore flush到hfile
- hfile compact
- 全量/局部
- 内存索引 跳表
- BloomFilter 优化查询,减少IO
-
mq
- rabbitmq
- rocketmq
- mmap
- kafka
- LSM
- 分区(并行)
- 日志分段处理
- 顺序写入
- 不支持事务,死信队列
- sendfile
-
debug
- 代理类 toString 触发代理逻辑
- threadlocal
- 自定义viewAs json.tostring 导致 lamda 提前执行
-
事务















 5191
5191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









