







意图
给定一种语言,定义他的文法的一种表示,并定义一个解释器,该解释器使用该表示来解释语言中句子。
动机
如果一种特定类型的问题发生频率足够高,那么可以将该问题的实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释该句子来解决问题。
适用性
1.当有一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树,可以使用解释器模式。而当存在以下情况时该模式效果最好
2.该文法的类层次结构变得庞大而无法管理。此时语法分析程序生成器这样的工具是最好的选择。他们无需构建抽象语法树即可解释表达式,这样可以节省空间而且还可能节省时间。
3.效率不是一个关键问题,最高效的解释器通常不是通过直接解释语法分析树实现的,而是首先将他们装换成另一种形式,例如,正则表达式通常被装换成状态机,即使在这种情况下,转换器仍可用解释器模式实现,该模式仍是有用的
结构图
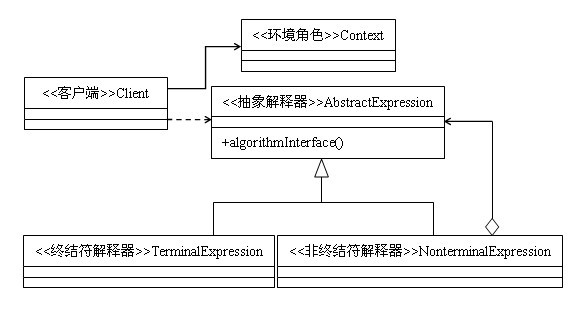
角色
抽象解释器:声明一个所有具体表达式都要实现的抽象接口(或者抽象类),接口中主要是一个interpret()方法,称为解释操作。具体解释任务由它的各个实现类来完成,具体的解释器分别由终结符解释器TerminalExpression和非终结符解释器NonterminalExpression完成。
终结符表达式:实现与文法中的元素相关联的解释操作,通常一个解释器模式中只有一个终结符表达式,但有多个实例,对应不同的终结符。终结符一半是文法中的运算单元,比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
非终结符表达式:文法中的每条规则对应于一个非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中,+就是非终结符,解析+的解释器就是一个非终结符表达式。非终结符表达式根据逻辑的复杂程度而增加,原则上每个文法规则都对应一个非终结符表达式。
环境角色:这个角色的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,很多情况下我们使用Map来充当环境角色就足够了。
实现
public abstract class Expression {
//每个表达式必须有一个解析任务
public abstract Object interpreter(Context ctx);
}
public class TerminalExpression extends Expression {
//通常终结符表达式只有一个,但是有多个对象
public Object interpreter(Context ctx) {
return null;
}
}
public class NonterminalExpression extends Expression {
//每个非终结符表达式都会对其他表达式产生依赖
public NonterminalExpression(Expression... expression){
}
public Object interpreter(Context ctx) {
//进行文法处理
return null;
}
}
public class Client {
public static void main(String[] args) {
Context ctx = new Context();
//通常定一个语法容器,容纳一个具体的表达式,通常为ListArray,LinkedList,Stack等类型
Stack<Expression> stack = null;
for(;;){
//进行语法判断,并产生递归调用
}
//产生一个完整的语法树,由各各个具体的语法分析进行解析
Expression exp = stack.pop();
//具体元素进入场景
exp.interpreter(ctx);
}
}优缺点
优点
解释器是一个简单语法分析工具,它最显著的优点就是扩展性,修改语法规则只要修改相应的非终结符表达式就可以了,若扩展语法,则只要增加非终结符类就可以了。
缺点
解释器模式会引起类膨胀
每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。
解释器模式采用递归调用方法
每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。想想看,如果要排查一个语法错误,我们是不是要一个一个断点的调试下去,直到最小的语法单元。
效率问题
解释器模式由于使用了大量的循环和递归,效率是个不容忽视的问题,特别是用于解析复杂、冗长的语法时,效率是难以忍受的。
最佳实践
解释器模式在实际的系统开发中使用的非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,比如一些数据分析工具、报表设计工具、科学计算工具等等,若你确实遇到“一种特定类型的问题发生的频率足够高”的情况,准备使用解释器模式时,可以考虑一下Expression4J、MESP(Math Expression String Parser)、Jep等开源的解析工具包,功能都异常强大,而且非常容易使用,效率也还不错,实现大多数的数学运算完全没有问题,自己没有必要从头开始编写解释器,有人已经建立了一条康庄大道,何必再走自己的泥泞小路呢?















 1217
1217

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









