







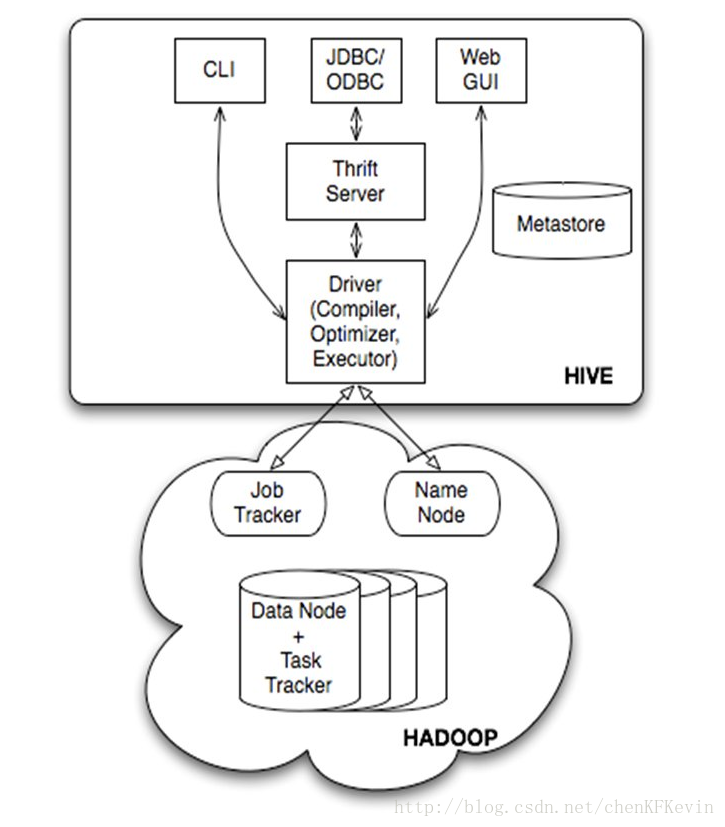
Hive——hdfs上的数据仓库
hive的架构主要分为以下几部分:
Driver组件:它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
Metastore组件:元数据服务组件,这个组件存储hive的元数据,hive的元数据存储在关系数据库里,hive支持的关系数据库有derby、mysql。
Thrift服务:thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
Thrift客户端:下面的架构图里没有写上Thrift客户端,但是hive架构的许多客户端接口是建立在thrift客户端之上,包括JDBC和ODBC接口。
WEBGUI:hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。(用的较少)
如下图:
Driver组件
一个hql语句,提交之后,具体的执行步骤:
由上图可以看出,Driver具体分为解析器、编译器、优化器。
首先由解析器进行词法分析,如果不符合语法,直接报错。
符合语法之后则编译为MapReduce程序,优化器优化之后再hdfs上执行。
所以hive说穿了就是将开发人员的hql语句转换为MapReduce程序之后,处理hdfs上的数据,免去了开发人员开发MapReduce的成本,大大降低了使用hadoop的门槛。
Metastore组件
hive的元数据不像表里的数据存在hdfs上,而是存在关系型数据库中。hive默认的元数据库为derby数据库,存储hive的元数据。一般现实中会存在远程服务器的mysql数据库。hive的元数据记录的是表的基本信息和属性。
Thrift服务:
能让不同的编程语言调用hive的接口,支持jdbc和odbc。
Thrift客户端和WEBGUI
了解较少,在工作中暂未用过。
这篇主要介绍了hive的架构和组成部分,下一篇具体介绍hive的文件存储以及基本用法。














 7380
7380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









