







Hive
1 hive概念
Hive:数据仓库,使用SQL读取、写入和管理分布式存储中的大型数据集。结构可以投影到存储中已有的数据上。提供了命令行工具和JDBC驱动程序,用于将用户连接到配置单元。
hive是Apache社区的顶级项目,构建在Hadoop之上的数据仓库 ,适合处理离线,由facebook贡献开源,是为了解决海量的结构化日志的统计问题。
Hive是一个客户端,不是一个集群,把SQL提交到Hadoop集群上去运行。是一个类似于SQL的框架, hiveQL和SQL没有关系,只是语法差不多。
HQL默认不支持行级别的增改删,需要手动配置
hive离线批处理里面是不考虑事务的
支持分区存储。
Hive职责是:SQL 变成MR/Spark,交到集群上去运行。底层支持的引擎是:MR/Spark/Tez。
统一的元数据管理
SQL on Hadoop : Spark SQL/Hive/Impala/Presto (这些框架创建好的表都是能相互使用)

2 hive架构
描述数据的数据是元数据。
Hive数据:HDFS (数据) + MySQL (元数据) (字段类型)
为什么能用SQL来进行大数据统计分析?
有元数据的支撑,我们知道HDFS上的数据每一列字段名是什么,字段类型是什么,数据在HDFS的什么位置。
hive的信息是可以配置在hive-site.xml里面 (全局)
命令行中也能设置 当前session(窗口)
set 参数; 查看当前参数的值
set 参数=值; 真正的设置参数对应的值
多个:hive --hiveconf k=v --hiveconf k=v
查看历史 Hadoop用户~/.hivehistory
3 Hive部署
1)下载:http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz
2)rz上传,解压: tar -zvxf hive-1.1.0-cdh5.15.1.tar.gz -C ~/app/
亦或软连接到~/app/
[hadoop@hadoop001 app]$ ll
total 0
lrwxrwxrwx 1 hadoop hadoop 43 Jul 8 10:56 hadoop -> /home/hadoop/software/hadoop-2.6.0-cdh5.7.0
lrwxrwxrwx 1 hadoop hadoop 42 Jul 26 13:36 hive -> /home/hadoop/software/hive-1.1.0-cdh5.15.1
[hadoop@hadoop001 app]$
3)将HIVE_HOME配置到系统环境变量(~/.bash_profile)
export HIVE_HOME=/home/hadoop/app/hive
export PATH=$HIVE_HOME/bin:$PATH
4)安装MySQL
5)将MySQL驱动(APP /lib包下的connector)拷贝到$HIVE_HOME/lib
6)MySQL赋权操作
7) /home/hadoop/app/hive/conf//hive-env.sh hadoop配了环境变量就不要改
/home/hadoop/app/hive/conf/hive-site.xml 配置文件到hive-site.xml 中
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop001:3306/ruoze_d7?createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
</configuration>8
7)启动hive
$HIVE_HOME/bin/hive亦或hive
4 基本操作
创建表
show databases;
use default;
show tables;
/home/hadoop/data/vi 文件,编辑内容
create table hello(id int,name string)
row format delimited fields terminated by ',';
show databases;
load data local inpath '/home/hadoop/data/hello.txt' overwrite into table hello;
select *from xxx
修改配置
默认的Hive数据存放在HDFS上:/user/hive/warehouse
hive.metastore.warehouse.dir Hive 数据存放的HDFS的路径
如果要调整,就把这个参数设置到hive-site.xml中去
<property>
<name>hive.metastore.warehouse.dir</name>
<value>xxxx</value>
</property>
创建的表默认属于default数据库,default数据库对应的目录就是hive.metastore.warehouse.dir
Hive中的表其实对应的就是HDFS上的一个目录,默认文件夹的名字就是tablename
找错误日志
hive/conf/log4.j.properties
hive详细日志:$HIVE_HOME/conf/hive-log4j.properties
hive.log.dir=${java.io.tmpdir}/${user.name}
hive.log.file=hive.log
/tmp/hadoop/hive.log
5 元数据信息
数据类型

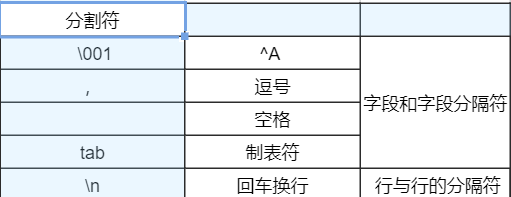
分割符案例:
日志文件分隔符和创建表的分隔符对上
1,ruoze
2,jepson
3,xingxing
==> row format delimited fields terminated by ',';
1$$$ruoze
2$$$jepson
3$$$xingxing
=> row format delimited fields terminated by '$$$';



select * from VERSION \G
VERSION 表中有且只能存在一条记录 当前的版本
DBS databases 库 存数据相关的
TBLS tables 表 描述表的
COLUMNS_V2 字段 描述字段
desc 表名;详细信息
desc extended 表名;更详细的表的信息
desc formatted 格式化的表名;常用
数据库/数据表案例
库
create database IF NOT EXISTS d7_hive; ==> /user/hive/warehouse/d7_hive.db 默认的待db
create database IF NOT EXISTS d7_hive2 LOCATION '/d7_hive';
use d7_hive
create table hello(id int,name string)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/data/hello.txt' overwrite into table hello;
删除
DROP DATABASE IF EXISTS d7_hive2 ;
数据库删除的时候,只要库下有表,默认就不能删除
DROP DATABASE IF EXISTS d7_hive2 CASCADE;
CASCADE 级联 慎用
表
vi 员工表到data目录下
CREATE TABLE ruozedata_emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/hadoop/data/emp.txt' overwrite into table ruozedata_emp;
查询表select
求每个部门多少人
select deptno,count(1) cnts from xxx_emp group by deptno;















 5313
5313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









