






一、生产者消费者模式
1.什么是生产者消费者模式
「生产者消费者模型」(cp)是通过一个容器来解决生产者与消费者的强耦合关系,生产者与消费者之间不直接进行通讯,而是利用 「容器」来进行通讯
生产者?消费者?容器?耦合?晦涩难懂的名词难免让人打起退堂鼓,其实它们都很好理解,比如接下来我们可以借助一个 超市 的例子来深刻理解 生产者消费者模型
超市的工作模式
- 超市从工厂进货,工厂需要向超市提供商品
- 顾客在超市选购,超市需要向顾客提供商品
超市盈利的关键在于 平衡顾客与工厂间的供需关系
简单来说就是要做到 顾客可以在超市买到想要购买的商品,工厂也能同超市完成足量的需求订单,满足条件后,超市就可以盈利了
超市盈利的同时可以给供给双方带来便利
- 顾客不需要跑到工厂购买商品
- 工厂也不需要将商品配送到顾客手中
这就叫做 解决生产者与消费者间的强耦合关系
得益于 超市 做缓冲区,整个 生产消费 的过程十分高效,即便顾客没有在超市中找到想要的商品,也可借助超市之手向工厂进行反映,从而生产对应的商品,即 允许生产消费步调不一致
现实中的 超市工作模式 就是一个生动形象的 「生产者消费者模型」
- 顾客 -> 「消费者」
- 工厂 -> 「生产者」
- 超市 -> 「交易场所(容器)」
生产者消费者模型的本质:忙闲不均
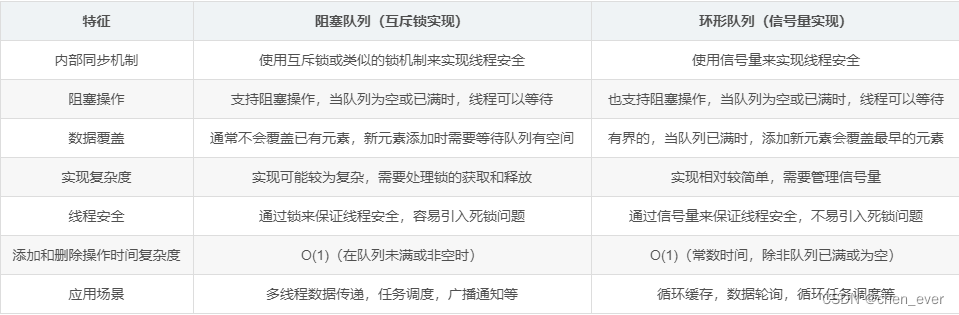
其中的 「交易场所」 是进行 生产消费 的容器,通常是一种特定的 缓冲区,常见的有 阻塞队列 和 环形队列
超市不可能只面向一个顾客及一个工厂,「交易场所」 也是如此,会被多个 生产者消费者(多个线程) 看到,也就是说 「交易场所」 注定是一个共享资源;在多线程环境中,需要保证 共享资源被多线程并发访问时的安全
1.2 cp模型的特点
「生产者消费者模型」 的最根本特点是 321原则
3种关系
- 生产者与生产者:互斥
- 消费者与消费者:互斥
- 生产者与消费者:互斥与同步
2种角色
- 生产者
- 消费者
1个交易场所
- 通常是一个特定的缓冲区(阻塞队列、环形队列)
注:321 原则并非众所周知的概念,仅供辅助记忆 「生产者消费者模型」的特点
任何 「生产者消费者模型」 都离不开这些必备特点
生产者与消费者间的同步关系
- 生产者不断生产,交易场所堆满商品后,需要通知消费者进行消费
- 消费者不断消费,交易场所为空时,需要通知生产者进行生产
通知线程需要用到条件变量,即维护 同步 关系
管道 本质上就是一个天然的 「生产者消费者模型」,因为它允许多个进程同时访问,并且不会出现问题,意味着它维护好了 「互斥、同步」 关系;当写端写满管道时,无法再写,通知读端进行读取;当管道为空时,无法读取,通知写端写入数据
1.3 cp模型的优点
「生产者消费者模型」为何高效?
- 生产者、消费者 可以在同一个交易场所中进行操作
- 生产者在生产时,无需关注消费者的状态,只需关注交易场所中是否有空闲位置
- 消费者在消费时,无需关注生产者的状态,只需关注交易场所中是否有就绪数据
- 可以根据不同的策略,调整生产者于与消费者间的协同关系
生产者消费者模型」可以根据供需关系灵活调整策略,做到 忙闲不均
除此之外,「生产者消费者模型」 划分出了三个不同的条件:生产者、消费者、交易场所 各司其职,可以根据具体需求自由设计,很好地做到了 解耦,便于维护和扩展
二、基于阻塞队列的cp模型
2.1 阻塞队列
编写 「生产者消费者模型」 需要用到 互斥与同步 的知识,这里先选择 阻塞队列 作为交易场所进行实现,在正式编写代码前,需要先认识一下 阻塞队列
阻塞队列 Blocking Queue 是一种特殊的队列,作为队列家族的一员,它具备 先进先出 FIFO 的基本特性,与普通队列不同的是: 阻塞队列 的大小是固定的,也就说它存在 容量 的概念
阻塞队列可以为空,也可以为满
将其带入 「生产者消费者模型」 中,入队 就是 生产商品,而 出队 则是 消费商品
- 阻塞队列为满时:无法入队 -> 无法生产(阻塞)
- 阻塞队列为空时:无法出队 -> 无法消费(阻塞)

2.2 单cp模型
首先来实现最简单的 单生产单消费者模型,首先搭好 阻塞队列类 的框架
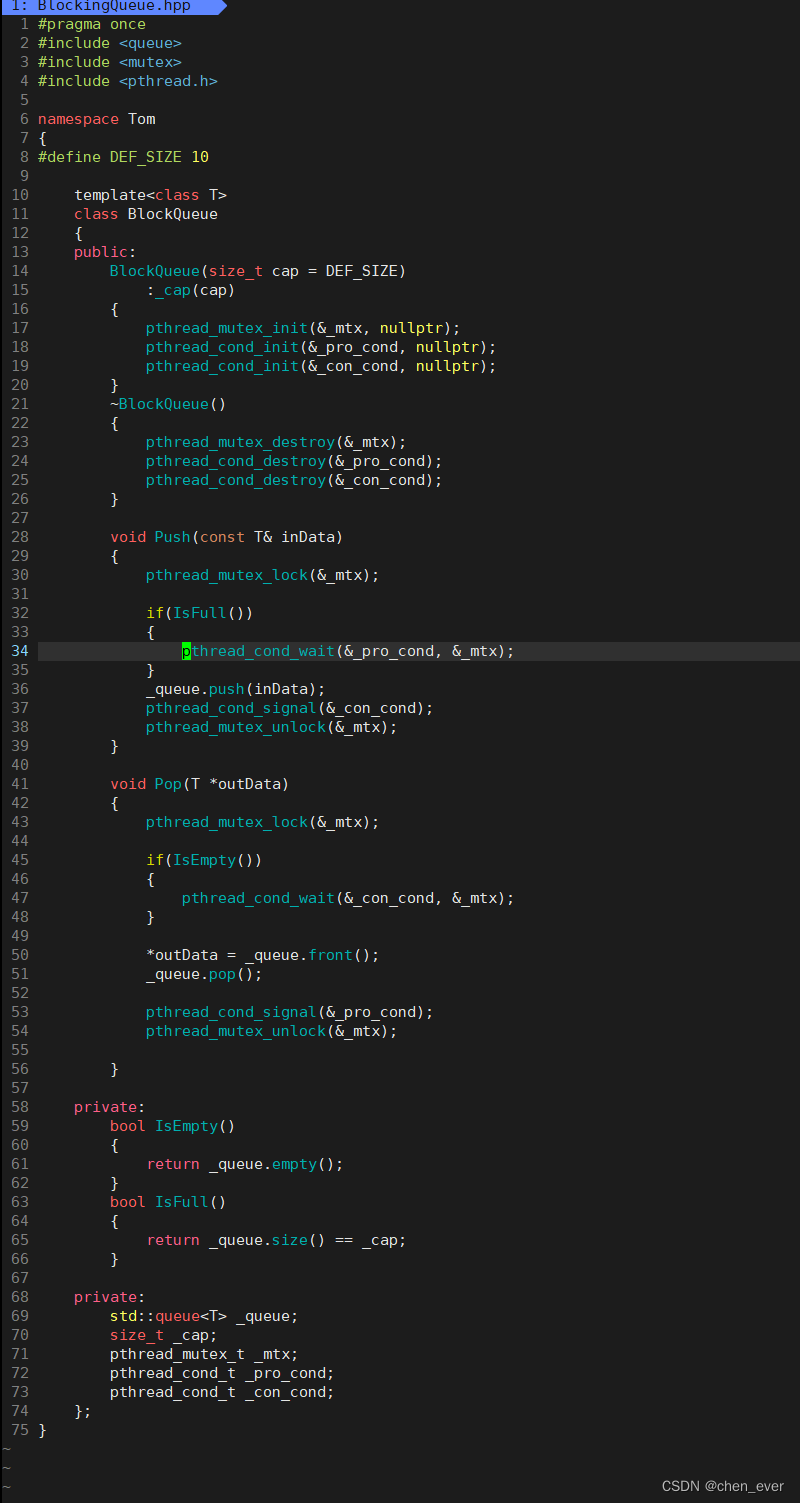
创建
BlockingQueue.hpp头文件
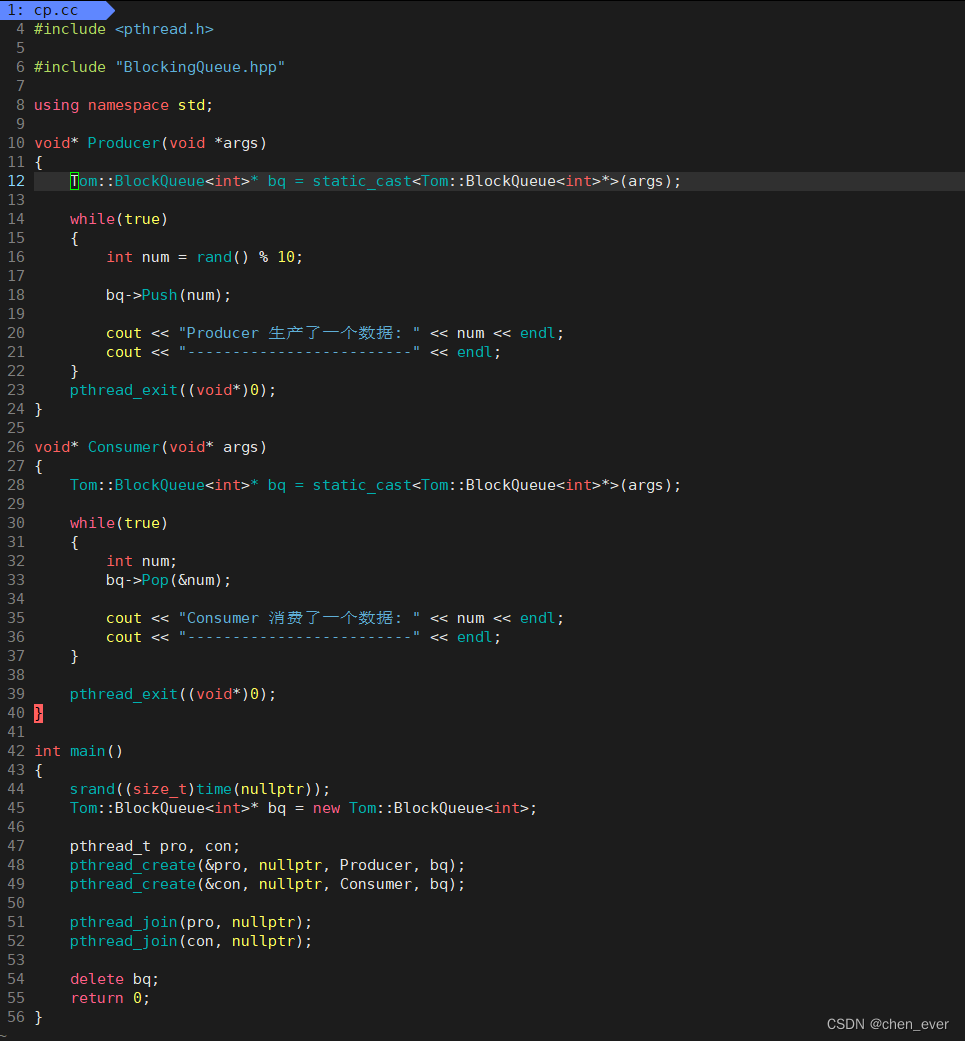
创建
cp.cc源文件
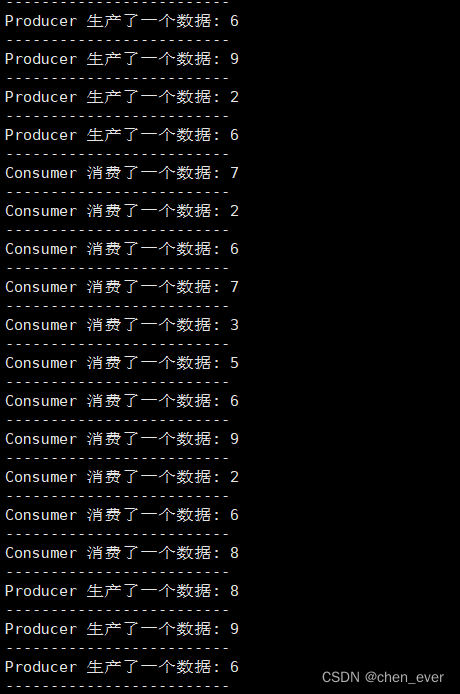
此时可以编译并运行程序,可以看到 生产者疯狂生产,消费者疯狂消费
这样不容易观察到 阻塞队列 的特点,我们可以通过 睡眠 的方式模拟效果
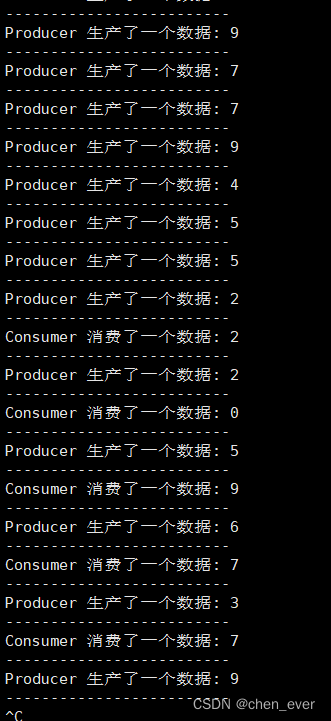
策略1:消费者每隔一秒消费一次,生产者疯狂生产
应该观察到的现象是 生产者很快就把阻塞队列填满了,只能阻塞等待,1 秒之后,消费者进行消费,消费结束后唤醒生产者,两者进入协同状态:生产者生产一个数据、消费者消费一个数据
void* Consumer(void *args)
{
Yohifo::BlockQueue<int>* bq = static_cast<Yohifo::BlockQueue<int>*>(args);
while(true)
{
// 消费者每隔一秒进行一次消费
sleep(1);
// 1.从阻塞队列中获取商品
int num;
bq->Pop(&num);
// 2.消费商品(结合某种具体业务进行处理)
std::cout << "Consumer 消费了一个数据: " << num << std::endl;
std::cout << "------------------------" << std::endl;
}
pthread_exit((void*)0);
}
策略2:生产者每隔一秒生产一次,消费者不断消费
预期结果为 刚开始阻塞队列为空,消费者无法进行消费,只能阻塞等待,一秒后,生产者生产了一个数据,并立即通知消费者进行消费,两者协同工作,消费者消费的就是生产者刚刚生产的数据
void* Producer(void *args)
{
Yohifo::BlockQueue<int>* bq = static_cast<Yohifo::BlockQueue<int>*>(args);
while(true)
{
// 生产者每隔一秒生产一次
sleep(1);
// 1.生产商品(通过某种渠道获取数据)
int num = rand() % 10;
// 2.将商品推送至阻塞队列中
bq->Push(num);
std::cout << "Producer 生产了一个数据: " << num << std::endl;
std::cout << "------------------------" << std::endl;
}
pthread_exit((void*)0);
}
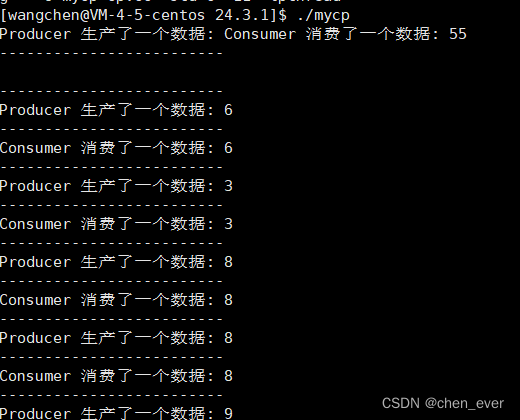
两种策略都符合预期,证明当前的 「生产者消费者模型」 是可用的(单生产单消费场景中)
2.3 多cp模式
在上面的 「生产者消费者模型」 中,存在一些细节问题
问题1:只有当条件满足时,才能进行 生产/消费
之前单纯使用一个 if 进行判断过于草率
理由如下:
pthread_cond_wait函数可能调用失败(误唤醒、伪唤醒),此时如果是if就会向后继续运行,导致在条件不满足的时候进行了 生产/消费- 在多线程场景中,可能会使用
pthread_cond_broadcast唤醒所有等待线程,如果在只生产了一个数据的情况下,唤醒所有线程,会导致只有一个线程进行了合法操作,其他线程都是非法操作了
所以需要把条件判断改成 while,直到条件满足后,才向后运行
问题2:生产者消费者模型的高效体现在 「解耦」
生产、消费 的过程是加锁的、串行化执行,可能有的人无法 get 到 「生产者消费者模型」 的高效,这是因为没有对 「生产者消费者模型」 进行一个全面的理解
单纯的向队列中放数据、从队列中取数据本身效率就很高,但 生产者从某种渠道获取数据、消费者获取数据后进行某种业务处理,这是效率比较低的操作,「生产者消费者模型」 做到了这两点
1.消费者在进行业务处理时,生产者可以直接向队列中 push 数据
比如 消费者 在获取到数据后,需要进行某种高强度的运算,当然这个操作与 生产者 是没有任何关系的,得益于 阻塞队列 作为缓冲区,生产者 可以在 消费者 进行运算时 push 数据
2.生产者在进行数据生产时,消费者可以直接向队列中 pop 数据
同上,消费者 不需要关心 生产者 的状态,只要 阻塞队列 中还有数据,正常 pop 获取就行了;也就是说你在超市购物时,无需关心工厂的生产情况,因为这与你无关
一句话总结:生产者不必关心消费者的消费情况,消费者也不需要关心生产者的生产情况
问题3:阻塞队列中不止能放 int,还能放对象
实际还可以放入更复杂的任务,比如 网络请求、SQL 查询、并行 IO
尤其是 IO,使用 「生产者消费者模型」 可以大大提高效率,包括后面的 多路转接,也可以接入 「生产者消费者模型」 来提高效率
现在可以尝试修改代码以适应 多生产多消费场景 了
需要改吗?不需要,至少在当前的代码设计中,我们的代码完全可以应付 多线程多消费
接下来在原有代码的基础上,直接多创建几个线程
int main()
{
// 种 种子
srand((size_t)time(nullptr));
// 创建一个阻塞队列
Yohifo::BlockQueue<Yohifo::Task<int>>* bq = new Yohifo::BlockQueue<Yohifo::Task<int>>;
// 创建多个线程(生产者、消费者)
pthread_t pro[2], con[3];
for(int i = 0; i < 2; i++)
pthread_create(pro + i, nullptr, Producer, bq);
for(int i = 0; i < 3; i++)
pthread_create(con + i, nullptr, Consumer, bq);
for(int i = 0; i < 2; i++)
pthread_join(pro[i], nullptr);
for(int i = 0; i < 3; i++)
pthread_join(con[i], nullptr);
delete bq;
return 0;
}

为什么当前代码设计中不需要修改就能适用于 多生产多消费场景 呢?
原因有两点:
- 生产者、消费者都是在对同一个
_queue操作,用一把锁,保护一个临界资源,足够了 - 当前的
_queue始终是被当作一个整体使用的,无需再增加锁区分
以上就是关于 基于阻塞队列实现「生产者消费者模型」的全部内容了,除了使用互斥锁外,还可以使用信号量,也就是使用环形队列来实现 「生产者消费者模型」
三、POSIX 信号量
3.1 信号量的基本知识
互斥、同步 不只能通过 互斥锁、条件变量 实现,还能通过 信号量 sem、互斥锁 实现(出自 POSIX 标准)
「信号量」 的本质就是一个 计数器
- 申请到资源,计数器
--(P操作) - 释放完资源,计数器
++(V操作)
「信号量」 的 PV 操作都是原子的,假设将 「信号量」 的值设为 1,用来表示 「生产者消费者模型」 中 阻塞队列 _queue 的使用情况
- 当
sem值为1时,线程可以进行 「生产 / 消费」,sem-- - 当
sem值为0时,线程无法进行 「生产 / 消费」,只能阻塞等待
此时的 「信号量」 只有两种状态:1、0,可以实现类似 互斥锁 的效果,即实现 线程互斥,像这种只有两种状态的信号量称为 「二元信号量」
「信号量」 不止可以用于 互斥,它的主要目的是 描述临界资源中的资源数目,比如我们可以把 阻塞队列 切割成 N 份,初始化 「信号量」 的值为 N,当某一份资源就绪时,sem--,资源被释放后,sem++,如此一来可以像 条件变量 一样实现 同步
- 当
sem == N时,阻塞队列已经空了,消费者无法消费 - 当
sem == 0时,阻塞队列已经满了,生产者无法生产
用来实现 互斥、同步 的信号量称为 「多元信号量」
综上所述,在使用 「多元信号量」 访问资源时,需要先申请 「信号量」,只有申请成功了才能进行资源访问,否则会进入阻塞等待,即当前资源不可用
在实现 互斥、同步 时,该如何选择?
结合业务场景进行分析,如果待操作的共享资源是一个整体,比较适合使用 互斥锁+条件变量 的方案,但如果共享资源是多份资源,使用 信号量 就比较方便
其实 「信号量」 的工作机制类似于 买电影票,是一种 预订机制,只要你买到票了,即使你晚点到达电影院,你的位置也始终可用,买到票的本质是将对应的座位进行了预订
对于 「信号量」 的第一层理解:申请信号量实际是一种资源预订机制
对于 「信号量」 的第二层理解:使用信号量时,就已经把资源条件判断转化成了信号量的申请行为
// 生产数据(入队)
void Push(const T& inData)
{
// 申请信号量 P操作
// ...
_queue.push(inData);
// ...
// 释放信号量 V操作
}
3.2 信号量操作函数
有了之前 互斥锁、条件变量 的使用基础,信号量 的接口学习是释放简单的,依旧是只有四个接口:初始化、销毁、申请、释放
初始化信号量
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数1:需要初始化的信号量,sem_t 实际就是一个联合体,里面包含了一个 char 数组,以及一个 long int 成员
typedef union
{
char __size[__SIZEOF_SEM_T];
long int __align;
} sem_t;
参数2:表示当前信号量的共享状态,传递 0 表示线程间共享,传递 非0 表示进程间共享
参数3:信号量的初始值,可以设置为双元或多元信号量
返回值:初始化成功返回 0,失败返回 -1,并设置错误码
销毁信号量
#include <semaphore.h>
int sem_destroy(sem_t *sem);
参数:待销毁的信号量
返回值:成功 0,失败 -1, 并设置错误码
申请信号量(等待信号量)
#include <semaphore.h>
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
主要使用 sem_wait
参数:表示从哪个信号量中申请
返回值:成功返回 0,失败返回 -1,并设置错误码
释放信号量(发布信号量)
#include <semaphore.h>
int sem_post(sem_t *sem);
参数:将资源释放到哪个信号量中
返回值:成功返回 0,失败返回 -1,并设置错误码
这批接口属于是看一眼就会用,再多看一眼就会爆炸(鸡~),参数、返回值含义基本都相同,非常容易上手,接下来直接用信号量实现 「生产者消费者模型」
四、基于环形队列的cp模型
4.1 环形队列
生产者消费者模型」 中的交易场所是可更换的,不仅可以使用 阻塞队列,还可以使用 环形队列,所谓的 环形队列 并非 队列,而是用数组模拟实现的 “队列”, 并且它的 判空、判满 比较特殊
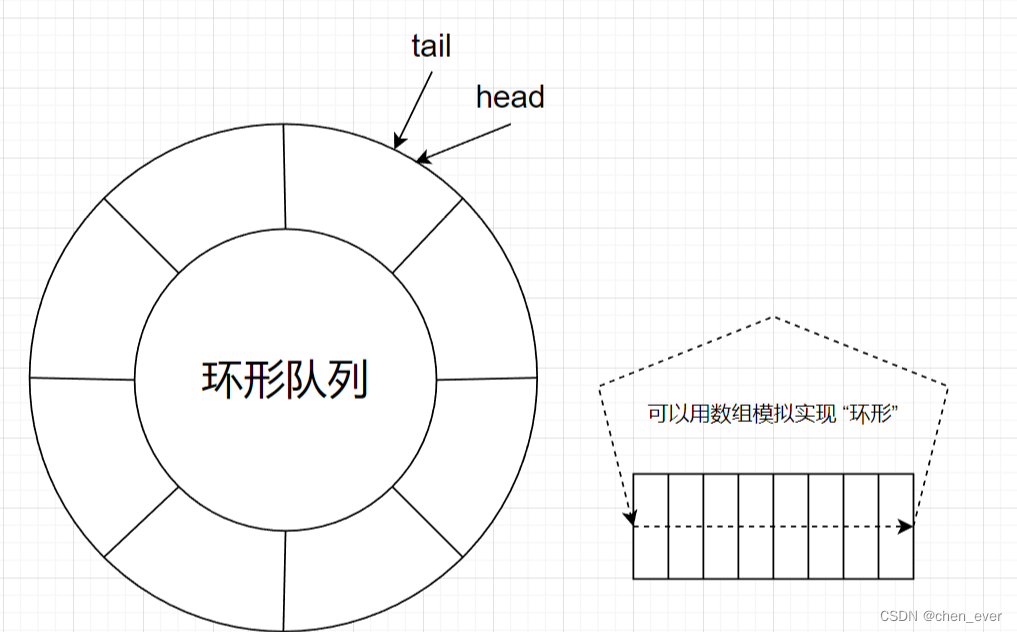
如何让 环形队列 “转” 起来?
- 可以通过取模的方式(可以重复获取一段区间值),确定下标
参考阻塞队列,搞一个计数器,当计数器的值为 0 时,表示当前为空,当计数器的值为容量时,表示队列为满
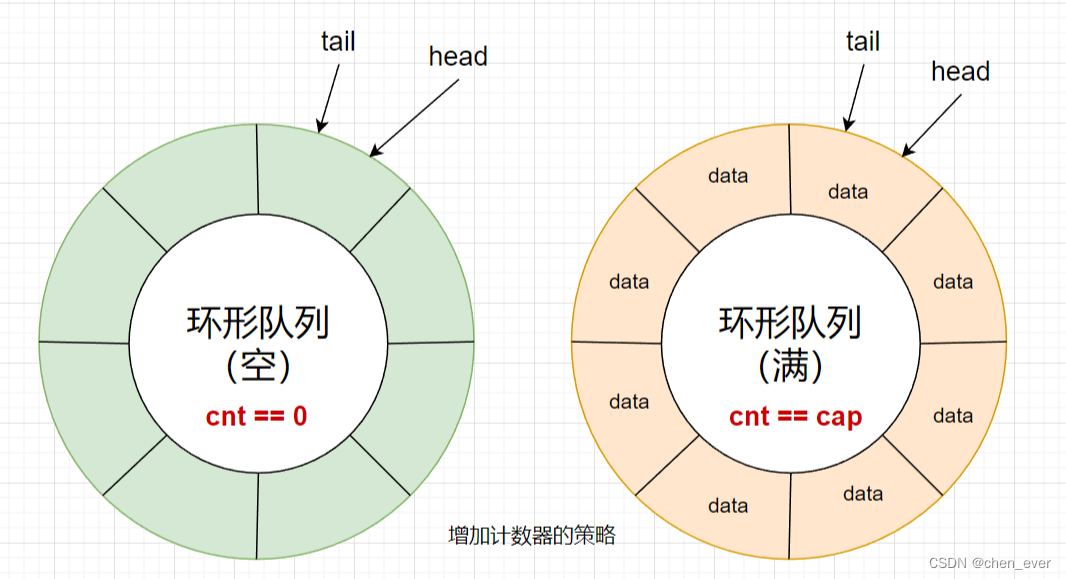
在 环形队列 中,生产者 和 消费者 关心的资源不一样:生产者只关心是否有空间放数据,消费者只关心是否能从空间中取到数据
除非两者相遇,其他情况下生产者、消费者可以并发运行(同时访问环形队列)
两者错位时正常进行生产消费就好了,但两者相遇时需要特殊处理,也就是处理 空、满 两种情况,这就是 环形队列 的运转模式
可以使用 「信号量」 标识资源的使用情况,但生产者和消费者关注的资源并不相同,所以需要使用两个 「信号量」 来进行操作
- 生产者信号量:标识当前有多少可用空间
- 消费者信号量:标识当前有多少数据
果说搞两个 条件变量 是 阻塞队列 的精髓,那么搞两个 信号量 就是 环形队列 的精髓,显然,刚开始的时候,生产者信号量初始值为环形队列的大小,消费者信号量初始值为 0
无论是生产者还是消费者,只有申请到自己的 「信号量」 资源后,才进行 生产 / 消费
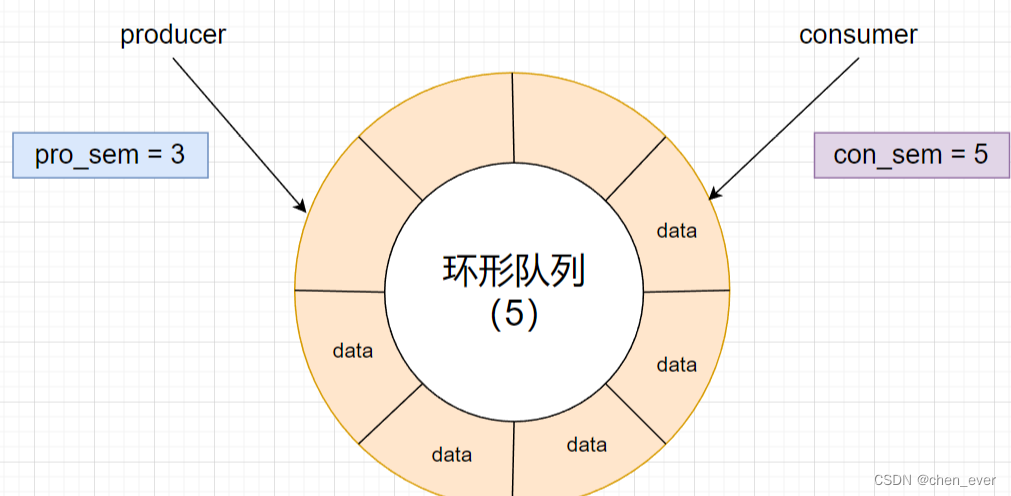
比如上图中的 pro_sem 就表示 生产者还可以进行 3 次生产,con_sem 表示 消费者还可以消费 5 次
生产者、消费者对于 「信号量」 的申请可以这样理解
// 生产者
void Producer()
{
// 申请信号量(空位 - 1)
sem_wait(&pro_sem);
// 生产商品
// ...
// 释放信号量(商品 + 1)
sem_post(&con_sem);
}
// 消费者
void Consumer()
{
// 申请信号量(商品 - 1)
sem_wait(&con_sem);
// 消费商品
// ...
// 释放信号量(空位 + 1)
sem_post(&pro_sem);
}
生产者和消费者指向同一个位置时保证线程安全,其他情况保证并发度
4.2 单环形队列cp模式
首先来实现简单点的单生产、单消费版 「生产者消费者模型」
起手先创建一个 环形队列 头文件
创建
RingQueue.hpp头文件
#pragma once
#include <vector>
#include <semaphore.h>
namespace Yohifo
{
#define DEF_CAP 10
template<class T>
class RingQueue
{
public:
RingQueue(size_t cap = DEF_CAP)
:_cap(cap), _pro_step(0), _con_step(0)
{
_queue.resize(_cap);
// 初始化信号量
sem_init(&_pro_sem, 0, _cap);
sem_init(&_con_sem, 0, 0);
}
~RingQueue()
{
// 销毁信号量
sem_destroy(&_pro_sem);
sem_destroy(&_con_sem);
}
// 生产商品
void Push(const T &inData)
{
// 申请信号量
P(&_pro_sem);
// 生产
_queue[_pro_step++] = inData;
_pro_step %= _cap;
// 释放信号量
V(&_con_sem);
}
// 消费商品
void Pop(T *outData)
{
// 申请信号量
P(&_con_sem);
// 消费
*outData = _queue[_con_step++];
_con_step %= _cap;
// 释放信号量
V(&_pro_sem);
}
private:
void P(sem_t *sem)
{
sem_wait(sem);
}
void V(sem_t *sem)
{
sem_post(sem);
}
private:
std::vector<T> _queue;
size_t _cap;
sem_t _pro_sem;
sem_t _con_sem;
size_t _pro_step; // 生产者下标
size_t _con_step; // 消费者下标
};
}
- 生产者的信号量初始值为
DEF_CAP - 消费者的信号量初始值为
0 - 生产者、消费者的起始下标都为
0
在没有 互斥锁 的情况下,是如何 确保生产者与消费者间的互斥关系的?
通过两个 信号量,当两个 信号量 都不为 0 时,双方可以并发操作,这是 环形队列 最大的特点;当 生产者信号量为 0 时,生产者陷入阻塞等待,等待消费者消费;同理当 消费者信号量为 0 时,消费者也会阻塞住,在这里阻塞就是 互斥 的体现。当对方完成 生产 / 消费 后,自己会解除阻塞状态,而这就是 同步
创建
cp.cc源文件(可以复用之前的测试代码)
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <time.h>
#include "RingQueue.hpp"
void* Producer(void *args)
{
Yohifo::RingQueue<int>* rq = static_cast<Yohifo::RingQueue<int>*>(args);
while(true)
{
// 生产者慢一点
sleep(1);
// 1.生产商品(通过某种渠道获取数据)
int num = rand() % 10;
// 2.将商品推送至阻塞队列中
rq->Push(num);
std::cout << "Producer 生产了一个数据: " << num << std::endl;
std::cout << "------------------------" << std::endl;
}
pthread_exit((void*)0);
}
void* Consumer(void *args)
{
Yohifo::RingQueue<int>* rq = static_cast<Yohifo::RingQueue<int>*>(args);
while(true)
{
// 消费者慢一点
// sleep(1);
// 1.从阻塞队列中获取商品
int num;
rq->Pop(&num);
// 2.消费商品(结合某种具体业务进行处理)
std::cout << "Consumer 消费了一个数据: " << num << std::endl;
std::cout << "------------------------" << std::endl;
}
pthread_exit((void*)0);
}
int main()
{
// 种 种子
srand((size_t)time(nullptr));
// 创建一个阻塞队列
Yohifo::RingQueue<int>* rq = new Yohifo::RingQueue<int>;
// 创建两个线程(生产者、消费者)
pthread_t pro, con;
pthread_create(&pro, nullptr, Producer, rq);
pthread_create(&con, nullptr, Consumer, rq);
pthread_join(pro, nullptr);
pthread_join(con, nullptr);
delete rq;
return 0;
}
注:如果想要提高并发度,可以增大环形队列的容量
4.3 基于环形队列的多cp模式
多生产多消费场景 中的 CP 模型了,多生产多消费无非就是增加了 消费者与消费者、生产者与生产者 间的 互斥 关系,加锁就行了,现在问题是加几把锁?
答案是 两把,因为当前的 生产者和消费者 关注的资源不一样,一个关注剩余空间,另一个关注是否有商品,一把锁是无法锁住两份不同资源的,所以需要给 生产者、消费者 各配一把锁
阻塞队列 中为什么只需要一把锁?
因为阻塞队列中的共享资源是一整个队列,生产者和消费者访问的是同一份资源,所以一把锁就够了
#pragma once
#include <vector>
#include <mutex>
#include <semaphore.h>
namespace Yohifo
{
#define DEF_CAP 10
template<class T>
class RingQueue
{
public:
RingQueue(size_t cap = DEF_CAP)
:_cap(cap), _pro_step(0), _con_step(0)
{
_queue.resize(_cap);
// 初始化信号量
sem_init(&_pro_sem, 0, _cap);
sem_init(&_con_sem, 0, 0);
// 初始化互斥锁
pthread_mutex_init(&_pro_mtx, nullptr);
pthread_mutex_init(&_con_mtx, nullptr);
}
~RingQueue()
{
// 销毁信号量
sem_destroy(&_pro_sem);
sem_destroy(&_con_sem);
// 销毁互斥锁
pthread_mutex_destroy(&_pro_mtx);
pthread_mutex_destroy(&_con_mtx);
}
// 生产商品
void Push(const T &inData)
{
// 申请信号量
P(&_pro_sem);
Lock(&_pro_mtx);
// 生产
_queue[_pro_step++] = inData;
_pro_step %= _cap;
UnLock(&_pro_mtx);
// 释放信号量
V(&_con_sem);
}
// 消费商品
void Pop(T *outData)
{
// 申请信号量
P(&_con_sem);
Lock(&_con_mtx);
// 消费
*outData = _queue[_con_step++];
_con_step %= _cap;
UnLock(&_con_mtx);
// 释放信号量
V(&_pro_sem);
}
private:
void P(sem_t *sem)
{
sem_wait(sem);
}
void V(sem_t *sem)
{
sem_post(sem);
}
void Lock(pthread_mutex_t *lock)
{
pthread_mutex_lock(lock);
}
void UnLock(pthread_mutex_t *lock)
{
pthread_mutex_unlock(lock);
}
private:
std::vector<T> _queue;
size_t _cap;
sem_t _pro_sem;
sem_t _con_sem;
size_t _pro_step; // 生产者下标
size_t _con_step; // 消费者下标
pthread_mutex_t _pro_mtx;
pthread_mutex_t _con_mtx;
};
}
注意: 加锁行为放在信号量申请成功之后,可以提高并发度
在 环形队列 中,可以在申请 「信号量」 前进行加锁,也可以在申请 「信号量」 后进行加锁,这里比较推荐的是 在申请 「信号量」 后加锁
阻塞队列 效率已经够高了,那么创造 环形队列 的意义在哪呢?
首先要明白 「生产者消费者模型」 高效的地方从来都不是往缓冲区中放数据、从缓冲区中拿数据
对缓冲区的操作对于计算机说就是小 case,需要关注的点在于 获取数据和消费数据,这是比较耗费时间的,阻塞队列 至多支持获取 一次数据获取 或 一次数据消费,在代码中的具体体现就是 所有线程都在使用一把锁,并且每次只能 push、pop 一个数据;而 环形队列 就不一样了,生产者、消费者 可以通过 条件变量 知晓数据获取、数据消费次数,并且由于数据获取、消费操作没有加锁,支持并发,因此效率十分高
环形队列 中允许 N 个生产者线程一起进行数据获取,也允许 N 个消费者线程一起进行数据消费,简单任务处理感知不明显,但复杂任务就不一样了,这就有点像同时下载多份资源,是可以提高效率的
注意: 一起操作并非同时操作,任务开始时间有先后,但都是在进行处理的
环形队列 一定优于 阻塞队列 吗?
答案是否定的,存在即合理,如果 环形队列 能完全碾压 阻塞队列,那么早就不用学习 阻塞队列 了,这两种都属于 「生产者消费者模型」 常见的交易场所,有着各自的适用场景















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









