






目录
ahci_handle_port_interrupt (libahci.c)
sata_async_notification (libata-eh.c)
ata_scsi_media_change_notify (libata-eh.c)
ata_port_schedule_eh (libata-eh.c)
ata_eh_fastdrain_timerfn (libata-eh.c)
scsi_error_handler (scsi_error.c)
qc->complete_fn = ata_qc_complete_internal (libata-core.c)
qc->complete_fn = ata_scsi_qc_complete (libata-scsi.c)
相关寄存器
中断状态寄存器PxIS
规范文档位置:serial-ata-ahci-spec-rev1-3-1 (kdocs.cn)
简单翻译如下:
Cold Port Detect Status (CPDS[31]):置1表示已被cold presence detect(冷态检测)逻辑检测出设备状态变化。如当设备从无连接到连接设备或已连接设备到设备移除。PxCMD.CPD=1时生效;
Task File Error Status (TFES[30]):当设备更新状态寄存器并设置错误位(位0)时,将设置该位;
Host Bus Fatal Error Status (HBFS [29]):表示HBA遇到了无法恢复的主机总线错误,例如坏的软件指针。在PCI中,可能是目标或主中止。
Host Bus Data Error Status (HBDS[28]):表示当HBA读写系统内存时遇到数据错误,如不可校正的ECC/奇偶校验。
Interface Fatal Error Status (IFS[27]):表示HBA在Serial ATA接口上遇到错误,导致传输停止。
Interface Non-fatal Error Status (INFS[26]):表示HBA在Serial ATA接口上遇到错误,但还能继续操作。
Overflow Status (OFS[24]):表示HBA从设备接收到的字节比命令的PRD表中指定的字节多。
Incorrect Port Multiplier Status (IPMS[23]):表示HBA从一个没有执行命令的设备接收到一个FIS
PhyRdy Change Status (PRCS[22]):置1表示PhyRdy信号发送变化,此位反应了PxSERR.DIAG.N。通过清除PxSERR.DIAG.N位来清除该位。
Device Mechanical Presence Status (DMPS[7]):指示与此端口关联的“机械存在”是否已打开或关闭。
Port Connect Change Status (PCS[6]) :知识当前连接状态,与PxSERR.DIAG.X对应。
Descriptor Processed (DPS[5]) :包含“I”位的PRD已经完成了所有数据的传输。
Unknown FIS Interrupt (UFS[4]) :未知的FIS被接收且已存到系统内存中
Set Device Bits Interrupt (SDBS[3]) :包含了“I”位的Set Device Bits FIS被接收且已存到系统内存中
DMA Setup FIS Interrupt (DSS[2]) :包含了“I”位的DMA Setup FIS被接收且已存到系统内存中。
PIO Setup FIS Interrupt (PSS[1]) :包含了“I”位的PIO Setup FIS被接收且已存到系统内存中。
Device to Host Register FIS Interrupt (DHRS[0]) :包含了“I”位的Device to Host Register FIS被接收且已存到系统。内存中。
Linux中断对应宏/* PORT_IRQ_{STAT,MASK} bits */ PORT_IRQ_COLD_PRES = (1 << 31), /* cold presence detect, 冷态检测到,一般为热插拔时触发*/ PORT_IRQ_TF_ERR = (1 << 30), /* task file error, task file错误*/ PORT_IRQ_HBUS_ERR = (1 << 29), /* host bus fatal error, host致命错误*/ PORT_IRQ_HBUS_DATA_ERR = (1 << 28), /* host bus data error, host总线数据错误*/ PORT_IRQ_IF_ERR = (1 << 27), /* interface fatal error, 内部致命错误*/ PORT_IRQ_IF_NONFATAL = (1 << 26), /* interface non-fatal error, 内部一般错误,还能继续使用*/ PORT_IRQ_OVERFLOW = (1 << 24), /* xfer exhausted available S/G, 内存越界,设备真实收到的数据量比PRD表中描述的数据量大*/ PORT_IRQ_BAD_PMP = (1 << 23), /* incorrect port multiplier, 无效的端口扩展器*/ PORT_IRQ_PHYRDY = (1 << 22), /* PhyRdy changed, PhyRdy状态改变*/ PORT_IRQ_DEV_ILCK = (1 << 7), /* device interlock, */ PORT_IRQ_CONNECT = (1 << 6), /* port connect change status, 端口连接状态改变*/ PORT_IRQ_SG_DONE = (1 << 5), /* descriptor processed,所有数据传输完成 */ PORT_IRQ_UNK_FIS = (1 << 4), /* unknown FIS rx'd, 收到未知的FIS*/ PORT_IRQ_SDB_FIS = (1 << 3), /* Set Device Bits FIS rx'd,收到Set Device Bits FIS */ PORT_IRQ_DMAS_FIS = (1 << 2), /* DMA Setup FIS rx'd,收到 DMA Setup FIS */ PORT_IRQ_PIOS_FIS = (1 << 1), /* PIO Setup FIS rx'd,收到 PIO Setup FIS */ PORT_IRQ_D2H_REG_FIS = (1 << 0), /* D2H Register FIS rx'd,收到 D2H Register FIS */ PORT_IRQ_FREEZE = PORT_IRQ_HBUS_ERR |//host致命错误 PORT_IRQ_IF_ERR |//内部致命错误 PORT_IRQ_CONNECT |//端口连接状态改变 PORT_IRQ_PHYRDY |//PhyRdy状态改变 PORT_IRQ_UNK_FIS |//收到未知的FIS PORT_IRQ_BAD_PMP,//无效的端口扩展器 PORT_IRQ_ERROR = PORT_IRQ_FREEZE | PORT_IRQ_TF_ERR |//task file错误 PORT_IRQ_HBUS_DATA_ERR,//host总线数据错误 DEF_PORT_IRQ = PORT_IRQ_ERROR | PORT_IRQ_SG_DONE | PORT_IRQ_SDB_FIS | PORT_IRQ_DMAS_FIS | PORT_IRQ_PIOS_FIS | PORT_IRQ_D2H_REG_FIS,
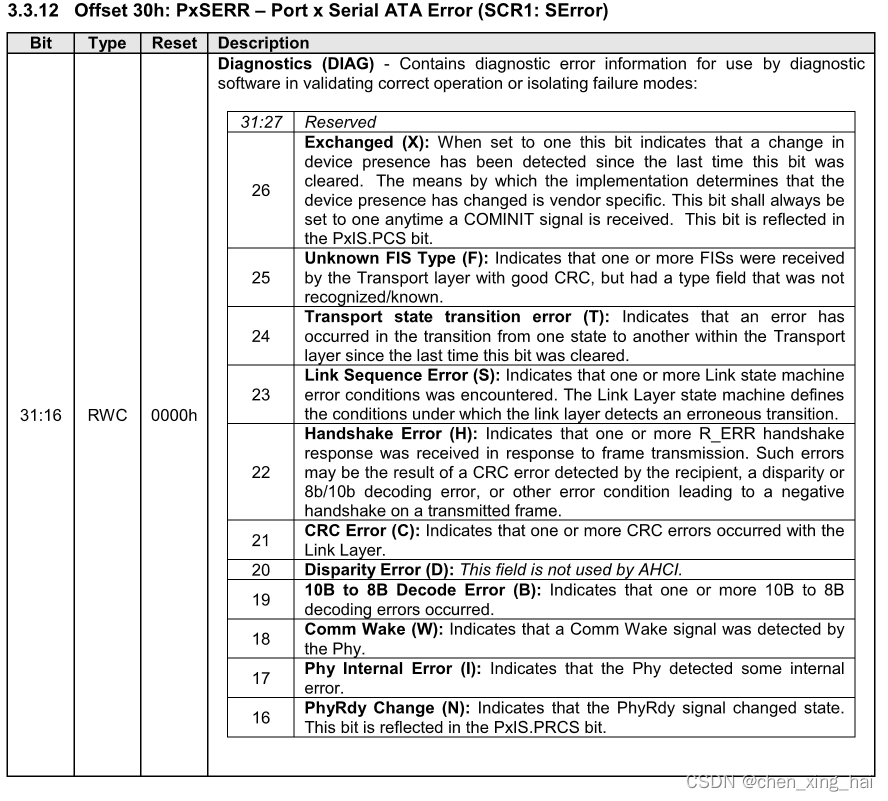
SATA寄存器PxSERR(SCR1)
文档位置SerialATA_Revision_3_1_Gold (kdocs.cn)14.1.2或serial-ata-ahci-spec-rev1-3-1 (kdocs.cn)3.3.12,见文章SATA-AHCI规范学习_chen_xing_hai的博客-CSDN博客
R 保留位
DIAG 诊断
A 检测到端口选择器存在
X 设备的存在发生改变
F 无法识别的FIS类型
T 传输状态转换错误
S 链路序列错误
H 握手错误
C CRC错误
D Disparity错误
B 10b到8b解码错误
W 检测到COMWAKE信号
I Phy内部错误
N PHYRDY信号变化
ERR 错误
E 内部错误
P 协议错误
C 不可恢复的通信或数据完整性错误
T 不可恢复的瞬态数据完整性错误
M 可恢复的通信错误
I 可恢复的数据完整性错误


Linux中相关宏定义:
SERR_DATA_RECOVERED = (1 << 0), /* recovered data error */
SERR_COMM_RECOVERED = (1 << 1), /* recovered comm failure */
SERR_DATA = (1 << 8), /* unrecovered data error */
SERR_PERSISTENT = (1 << 9), /* persistent data/comm error */
SERR_PROTOCOL = (1 << 10), /* protocol violation */
SERR_INTERNAL = (1 << 11), /* host internal error */
SERR_PHYRDY_CHG = (1 << 16), /* PHY RDY changed */
SERR_PHY_INT_ERR = (1 << 17), /* PHY internal error */
SERR_COMM_WAKE = (1 << 18), /* Comm wake */
SERR_10B_8B_ERR = (1 << 19), /* 10b to 8b decode error */
SERR_DISPARITY = (1 << 20), /* Disparity */
SERR_CRC = (1 << 21), /* CRC error */
SERR_HANDSHAKE = (1 << 22), /* Handshake error */
SERR_LINK_SEQ_ERR = (1 << 23), /* Link sequence error */
SERR_TRANS_ST_ERROR = (1 << 24), /* Transport state trans. error */
SERR_UNRECOG_FIS = (1 << 25), /* Unrecognized FIS */
SERR_DEV_XCHG = (1 << 26), /* device exchanged */中断处理函数初始化
中断处理函数初始化流程如下,最终核心中断处理函数为ahci_handle_port_interrupt,位于libahci.c。
ahci_init_one
->ahci_pci_save_initial_config
->ahci_save_initial_config
->hpriv->irq_handler = ahci_single_level_irq_intr;->ahci_host_activate
->ata_host_activate(host, irq, hpriv->irq_handler, IRQF_SHARED, sht);->devm_request_irq(host->dev, irq, irq_handler, irq_flags, irq_desc, host);
或 ->ahci_host_activate_multi_irqs
->devm_request_irq(host->dev, irq, ahci_multi_irqs_intr_hard, 0, pp->irq_desc, host->ports[i]);//为每个端口注册
ahci_single_level_irq_intr(共享中断,多个端口共享同一个中断处理函数)
->ahci_handle_port_intr
->ahci_port_intr //有中断挂起的port依次执行
->status = readl(port_mmio + PORT_IRQ_STAT); //读PxIS(0x10)中断状态寄存器
->ahci_handle_port_interrupt(ap, port_mmio, status);ahci_multi_irqs_intr_hard(单独中断,每个端口各自一个中断处理函数)
->status = readl(port_mmio + PORT_IRQ_STAT); //读PxIS(0x10)中断状态寄存器->ahci_handle_port_interrupt(ap, port_mmio, status);
中断处理函数工作流程
ahci_handle_port_interrupt
->sata_async_notification //收到Set Device Bits FIS时,异步通知ata与scsi层
->ata_scsi_media_change_notify //通知上层应用
->scsi_evt_thread
->ata_port_schedule_eh //ata_std_sched_eh
->ata_eh_set_pending->ata_eh_fastdrain_timerfn//开启命令超时定时器,出现命令的端口将被冻结并终止命令
->ata_port_freeze
->scsi_schedule_eh->scsi_eh_wakeup //shost错误数量与正在处理的命令数量相等时唤醒
->scsi_error_handler //scsi层错误处理
->ata_scsi_error
->ata_scsi_cmd_error_handler //预处理 scsi异常命令队列
->ata_scsi_port_error_handler //ata端口错误处理,包括scsi异常命令队列
->del_timer_sync(&ap->fastdrain_timer); //删除泄洪定时器
->ata_eh_handle_port_resume(ap) //调用ahci_port_resume来恢复端口
->ap->ops->error_handler(ap);//调用ahci_error_handler来处理错误
->ata_eh_handle_port_suspend(ap); //将恢复的端口挂起
->ap->ops->end_eh(ap);//ata_std_end_eh-> host->host_eh_scheduled = 0;
->scsi_eh_flush_done_q(&ap->eh_done_q);//处理scsi异常命令队列
->如果命令重传次数在允许范围内,调用scsi_queue_insert重新添加命令
->否则,调用scsi_finish_command完成命令
->schedule_delayed_work(&ap->hotplug_task, 0);//唤醒热插拔ata_scsi_hotplug
->wake_up_all(&ap->eh_wait_q);//唤醒等待异常处理完成的任务
->ata_qc_complete_multiple //命令完成,包括ata层、scsi层、blk层
->内部命令完成 ata_qc_complete_internal
->complete(waiting)
->scsi命令完成 ata_scsi_qc_complete
->mq命令 scsi_mq_done(qc->scsicmd)
->nmq命令 scsi_done(qc->scsicmd)
-> scsi_softirq_done //根据命令当前状态执行以下三个函数中的一个
->scsi_finish_command //完成scsi命令
->scsi_queue_insert //命令重传
->scsi_eh_scmd_add //唤醒异常命令处理线程,处理完ata端口后再调用scsi_finish_command或scsi_queue_insert
触发scsi_eh_wakeup时机
1.一些命令被取消或超时或错误时会调用scsi_eh_scmd_add将错误scsi命令添加到错误命令链表中,并调用scsi_eh_inc_host_failed接口shost->host_failed++;scsi_eh_wakeup(shost);
2.完成了一个命令或命令创建过程异常时调用scsi_dec_host_busy->scsi_eh_wakeup(shost);
3.收到Set Device Bit FIS并触发中断时。
scsi_eh_wakeup唤醒scsi_error_handler时机
如果shost错误数量与正在处理的命令数量相等时唤醒。如果此时错误数量为0,说明在空闲状态下发生事件,如热插拔。这样既保证了所有命令都触发异常或有热插拔事件产生后才唤醒异常处理机制
热插拔
使能了pmp的情况下,.error_handler = ahci_error_handler
ahci_error_handler
-> sata_pmp_error_handler(libata_pmp.c)
->sata_pmp_eh_recover(libata_pmp.c)
->ata_eh_recover(libata_eh.c)
->ata_eh_reset(libata_eh.c)
->.postreset
->..-> ata_std_postreset(libata_core.c)
-> sata_print_link_status(libata_core.c)
ahci_handle_port_interrupt (libahci.c)
static void ahci_handle_port_interrupt(struct ata_port *ap, void __iomem *port_mmio, u32 status)
{
int resetting = !!(ap->pflags & ATA_PFLAG_RESETTING);//是否正在复位
//如果正在复位,则忽略错误的PMP
/* ignore BAD_PMP while resetting */
if (unlikely(resetting))
status &= ~PORT_IRQ_BAD_PMP;
//当lpm(Link power management link电源管理)策略发生改变后,忽略第一次PHY事件,因为有可能是假事件
if (sata_lpm_ignore_phy_events(&ap->link)) {
status &= ~PORT_IRQ_PHYRDY;
ahci_scr_write(&ap->link, SCR_ERROR, SERR_PHYRDY_CHG);//清除PHYRDY状态改变标志
}
//是否包含致命错误,PORT_IRQ_ERROR宏包含了所有致命错误的bit
if (unlikely(status & PORT_IRQ_ERROR)) {
ahci_error_intr(ap, status);
return;
}
//如果收到了Set Device Bit FIS,host支持通知功能时则直接调用SATA异步通知处理程序(sata_async_notification),否则通过读取Set Device Bit FIS的N位(bit15)来查看是否需要调用SATA异步通知处理程序。
if (status & PORT_IRQ_SDB_FIS) {
if (hpriv->cap & HOST_CAP_SNTF)//如果host支持通知功能则调用
sata_async_notification(ap);
else {
//ahci 1.2中不应该缺少SNotification功能,所以当FBS启用时,不必要使用接收区来判断是否收到SDB FIS,此处给出了警告
if (pp->fbs_enabled)
WARN_ON_ONCE(1);
else {
const __le32 *f = pp->rx_fis + RX_FIS_SDB;
u32 f0 = le32_to_cpu(f[0]);
if (f0 & (1 << 15))
sata_async_notification(ap);
}
}
}
//pp->fbs_enabled使能的情况下pp->active_link变得不可靠,获取SActive(SCR3)和PxCI(Port x Command Issue)。备注:在NCQ模式下会使用SActive来表示哪些队列命令在正在执行,在开始NCQ命令时会将命令的tag对应bit写给SActive,而PxCI寄存器在NCQ即非NCQ命令都会用到,用于触发命令发送。fbs使能情况下,一个端口的这两个寄存器都要读,是因为NCQ和非NCQ命令可能同时在执行(从源码来看,一个设备要么全NCQ要么全非NCQ,但一个port会通过pmp连接多个设备,所以一个port会存在两种命令同时执行的情况。fbs都使的情况下肯定是要支持pmp的。不知有没有理解错)
if (pp->fbs_enabled) {
if (ap->qc_active) {
qc_active = readl(port_mmio + PORT_SCR_ACT);
qc_active |= readl(port_mmio + PORT_CMD_ISSUE);
}
} else {
/* pp->active_link is valid iff any command is in flight */
if (ap->qc_active && pp->active_link->sactive)
qc_active = readl(port_mmio + PORT_SCR_ACT);
else
qc_active = readl(port_mmio + PORT_CMD_ISSUE);
}
rc = ata_qc_complete_multiple(ap, qc_active);//qc_active 存放了当前正在执行队列命令
/* while resetting, invalid completions are expected */
if (unlikely(rc < 0 && !resetting)) {
ehi->err_mask |= AC_ERR_HSM;
ehi->action |= ATA_EH_RESET;
ata_port_freeze(ap);
}
}
备注:
pp->fbs_enabled在attach pmp且host支持fbs功能时置1sata_async_notification (libata-eh.c)
涉及到的寄存器有SCR4(SNotification register)
当Host收到了设置Notification位的Set Device Bits FIS时,需要将该FIS中的PM Port字段值反映到本寄存器的Notify字段中,如FIS中PM Port字段值为7,则本寄存器的Notify字段的bit7为1,且如果该FIS中的‘I’为置位了,还应该产生一个中断。此寄存器写1清零。
SNotification register
Set Device Bits FIS


->sata_async_notification
->ata_scsi_media_change_notify //通知上层应用
->scsi_evt_thread
->ata_port_schedule_eh
->ata_eh_fastdrain_timerfn//开启命令超时定时器,出现命令的端口将被冻结并终止命令
->ata_port_freeze
->scsi_error_handler //scsi层错误处理
->ata_scsi_error
int sata_async_notification(struct ata_port *ap)
{
//清除SNotification寄存器(SCR4)
rc = sata_scr_read(&ap->link, SCR_NOTIFICATION, &sntf);
if (rc == 0)
sata_scr_write(&ap->link, SCR_NOTIFICATION, sntf);
if (!sata_pmp_attached(ap) || rc) {
if (!sata_pmp_attached(ap)) {
struct ata_device *dev = ap->link.device;
if ((dev->class == ATA_DEV_ATAPI) &&
(dev->flags & ATA_DFLAG_AN))//没有PMP attach的apapi设备配置了AN异步通知,则通过ata_scsi_media_change_notify发送媒体更改事件
ata_scsi_media_change_notify(dev);
return 0;
} else {//读取Notification失败了,上报PHY状态改变
/* PMP is attached but SNTF is not available.
* ATAPI async media change notification is
* not used. The PMP must be reporting PHY
* status change, schedule EH.
*/
ata_port_schedule_eh(ap);
return 1;
}
} else {
/* PMP is attached and SNTF is available */
struct ata_link *link;
/* 为每个上报notify的link上的device发送媒体更改事件 */
ata_for_each_link(link, ap, EDGE) {
if (!(sntf & (1 << link->pmp)))
continue;
if ((link->device->class == ATA_DEV_ATAPI) &&
(link->device->flags & ATA_DFLAG_AN))
ata_scsi_media_change_notify(link->device);
}
/* If PMP is reporting that PHY status of some
* downstream ports has changed, schedule EH.
*/
if (sntf & (1 << SATA_PMP_CTRL_PORT)) {
ata_port_schedule_eh(ap);
return 1;
}
return 0;
}
}ata_scsi_media_change_notify (libata-eh.c)
在sata_async_notification 中,使能了atapi_an的atapi设备,在未attach或收到了Set Device Bits FIS后此接口被调用。异步操作,会唤醒scsi_evt_thread任务,evt_type = SDEV_EVT_MEDIA_CHANGE。
ata_scsi_media_change_notify //事件类型evt_type=SDEV_EVT_MEDIA_CHANGE
-> sdev_evt_send_simple
-> sdev_evt_send
-> list_add_tail(&evt->node, &sdev->event_list);
-> schedule_work(&sdev->event_work); //scsi_alloc_sdev时初始化为scsi_evt_thread
->scsi_evt_thread
-> envp[idx++] = "SDEV_MEDIA_CHANGE=1";
-> kobject_uevent_env(&sdev->sdev_gendev.kobj, KOBJ_CHANGE, envp);-
scsi_evt_thread (scsi_lib.c)
kobject事件类型。kobject_uevent_env用于Linux下热插拔事件产生时,通知到用户空间的一种方式,uevent是sysfs向用户空间发出的消息。上报后,用户空间可通过uevent_open_socket、uevent_kernel_multicast_recv接口获取事件。
->scsi_evt_thread
-> envp[idx++] = "SDEV_MEDIA_CHANGE=1"; envp[idx++] = NULL;
-> kobject_uevent_env(&sdev->sdev_gendev.kobj, KOBJ_CHANGE, envp);-
ata_port_schedule_eh (libata-eh.c)
在sata_async_notification 中,读取Notification失败或收到了Set Device Bits FIS后此接口被调用。异步操作,会异步唤醒两个任务ata_eh_fastdrain_timerfn和scsi_error_handler。
ata_port_schedule_eh
->ata_eh_fastdrain_timerfn
->ata_port_freeze
->scsi_error_handler
->ata_scsi_error
ata_port_schedule_eh
-> ata_std_sched_eh
->ata_eh_set_pending //配置为pending阻塞状态,如果fastdrain=1,则使用命令fastdrain泄洪机制(即中断超时的命令),此处为1
->ap->fastdrain_timer //3000个jiffies,ata_port_alloc阶段注册回调函数为:ata_eh_fastdrain_timerfn
->ata_eh_fastdrain_timerfn
->scsi_schedule_eh
->scsi_eh_wakeup
->wake_up_process(shost->ehandler)//scsi_host_alloc时初始化为:scsi_error_handler
->scsi_error_handler
-> shost->transportt->eh_strategy_handler(shost); //ata_attach_transport时初始化为:ata_scsi_error。subsystem init->ata_init->ata_attach_transport(libata_core.c)->.eh_strategy_handler=ata_scsi_error(libata_eh.c);-
ata_eh_fastdrain_timerfn (libata-eh.c)
ata端口的泄洪机制,命令完成超时机制。超过3000个jiffies时此接口触发,如果定时器开启之前正在运行的命令数量和现在当前不同,则再等3000个jiffies,否则认为超时,冻结端口并打断当前所有未完成的命令。
ata_eh_fastdrain_timerfn
-> ata_port_freeze
->__ata_port_freeze(ap);
->ahci_freeze;//关闭端口中断使能寄存器(0x14)
->ata_do_link_abort(ap);//打断正在执行的命令并标记超时、错误
void ata_eh_fastdrain_timerfn(struct timer_list *t)
{
struct ata_port *ap = from_timer(ap, t, fastdrain_timer);
unsigned long flags;
int cnt;
spin_lock_irqsave(ap->lock, flags);
cnt = ata_eh_nr_in_flight(ap);
/* are we done? */
if (!cnt)
goto out_unlock;
if (cnt == ap->fastdrain_cnt) {
struct ata_queued_cmd *qc;
unsigned int tag;
/* No progress during the last interval, tag all
* in-flight qcs as timed out and freeze the port.
*/
ata_qc_for_each(ap, qc, tag) {
if (qc)
qc->err_mask |= AC_ERR_TIMEOUT;
}
ata_port_freeze(ap);
} else {
/* some qcs have finished, give it another chance */
ap->fastdrain_cnt = cnt;
ap->fastdrain_timer.expires =
ata_deadline(jiffies, ATA_EH_FASTDRAIN_INTERVAL);
add_timer(&ap->fastdrain_timer);
}
out_unlock:
spin_unlock_irqrestore(ap->lock, flags);
}
//冻结并中断端口所有命令
int ata_port_freeze(struct ata_port *ap)
{
int nr_aborted;
WARN_ON(!ap->ops->error_handler);
ap->ops->freeze(ap);__ata_port_freeze(ap);
nr_aborted = ata_port_abort(ap);//ata_do_link_abort(ap)
return nr_aborted;
}
//中断所有正在执行的命令(所有命令标记错误状态并完成)
static int ata_do_link_abort(struct ata_port *ap, struct ata_link *link)
{
struct ata_queued_cmd *qc;
int tag, nr_aborted = 0;
WARN_ON(!ap->ops->error_handler);
/* we're gonna abort all commands, no need for fast drain */
ata_eh_set_pending(ap, 0);
/* include internal tag in iteration */
ata_qc_for_each_with_internal(ap, qc, tag) {
if (qc && (!link || qc->dev->link == link)) {
qc->flags |= ATA_QCFLAG_FAILED;
ata_qc_complete(qc);//所有命令标记错误状态并完成
nr_aborted++;
}
}
if (!nr_aborted)
ata_port_schedule_eh(ap);//如果未中断到任何命令,则重新再次处理错误。
return nr_aborted;
}-
scsi_error_handler (scsi_error.c)
scsi层的错误处理接口。
scsi_error_handler
->ata_scsi_error
ata_scsi_add_hosts
-> shost->transportt = ata_scsi_transport_template; //ata_init初始化ata_scsi_transport_template.eh_strategy_handler为 ata_scsi_error
int scsi_error_handler(void *data)
{
struct Scsi_Host *shost = data;
/*
* We use TASK_INTERRUPTIBLE so that the thread is not
* counted against the load average as a running process.
* We never actually get interrupted because kthread_run
* disables signal delivery for the created thread.
*/
while (true) {
/*
* The sequence in kthread_stop() sets the stop flag first
* then wakes the process. To avoid missed wakeups, the task
* should always be in a non running state before the stop
* flag is checked
*/
set_current_state(TASK_INTERRUPTIBLE);
if (kthread_should_stop())
break;
if ((shost->host_failed == 0 && shost->host_eh_scheduled == 0) ||
shost->host_failed != scsi_host_busy(shost)) {
SCSI_LOG_ERROR_RECOVERY(1,
shost_printk(KERN_INFO, shost,
"scsi_eh_%d: sleeping\n",
shost->host_no));
schedule();
continue;
}
__set_current_state(TASK_RUNNING);
SCSI_LOG_ERROR_RECOVERY(1,
shost_printk(KERN_INFO, shost,
"scsi_eh_%d: waking up %d/%d/%d\n",
shost->host_no, shost->host_eh_scheduled,
shost->host_failed,
scsi_host_busy(shost)));
/*
* We have a host that is failing for some reason. Figure out
* what we need to do to get it up and online again (if we can).
* If we fail, we end up taking the thing offline.
*/
if (!shost->eh_noresume && scsi_autopm_get_host(shost) != 0) {
SCSI_LOG_ERROR_RECOVERY(1,
shost_printk(KERN_ERR, shost,
"scsi_eh_%d: unable to autoresume\n",
shost->host_no));
continue;
}
if (shost->transportt->eh_strategy_handler)
shost->transportt->eh_strategy_handler(shost);
else
scsi_unjam_host(shost);
/* All scmds have been handled */
shost->host_failed = 0;
/*
* Note - if the above fails completely, the action is to take
* individual devices offline and flush the queue of any
* outstanding requests that may have been pending. When we
* restart, we restart any I/O to any other devices on the bus
* which are still online.
*/
scsi_restart_operations(shost);
if (!shost->eh_noresume)
scsi_autopm_put_host(shost);
}
__set_current_state(TASK_RUNNING);
SCSI_LOG_ERROR_RECOVERY(1,
shost_printk(KERN_INFO, shost,
"Error handler scsi_eh_%d exiting\n",
shost->host_no));
shost->ehandler = NULL;
return 0;
}-
ata_scsi_error (libata-eh.c)
ata_scsi_error
->ata_scsi_cmd_error_handler //处理待错误命令链表中的命令
->scsi_eh_finish_cmd(scmd, &ap->eh_done_q); //将错误命令加入到ata端口错误完成队列中,此处并不会真正处理命令,而是放到另一个错误完成处理队列中,防止影响当前的处理流程。
->ata_scsi_port_error_handler //真正处理错误,包括上述的错误完成队列
void ata_scsi_error(struct Scsi_Host *host)
{
struct ata_port *ap = ata_shost_to_port(host);
unsigned long flags;
LIST_HEAD(eh_work_q);
DPRINTK("ENTER\n");
spin_lock_irqsave(host->host_lock, flags);
//将命令链表添加到链表头中;命令链表本身没有链表头,所有命令直接连接在一起,
//但list_for_each_entry_safe等链表操作接口的入参为链表头,所以需要给命令链表添加一个链表头
//eh_cmd_q为错误命令链表,在scsi_eh_scmd_add函数中添加,很多需要取消命令、超时、错误发生的地方都会调用到该接口来添加错误命令。
list_splice_init(&host->eh_cmd_q, &eh_work_q);
spin_unlock_irqrestore(host->host_lock, flags);
ata_scsi_cmd_error_handler(host, ap, &eh_work_q);
/* If we timed raced normal completion and there is nothing to
recover nr_timedout == 0 why exactly are we doing error recovery ? */
ata_scsi_port_error_handler(host, ap);
/* finish or retry handled scmd's and clean up */
WARN_ON(!list_empty(&eh_work_q));
DPRINTK("EXIT\n");
}ata_scsi_port_error_handler
//此接口被调用说明了有命令产生了异常或有热插拔动作
void ata_scsi_port_error_handler(struct Scsi_Host *host, struct ata_port *ap)
{
unsigned long flags;
/* invoke error handler */
if (ap->ops->error_handler) {
struct ata_link *link;
/* acquire EH ownership */
ata_eh_acquire(ap);//互斥锁保护
repeat:
/* kill fast drain timer */
del_timer_sync(&ap->fastdrain_timer);//关闭泄洪定时器,因为此时端口已经不可用,定时器已经没用了,反而会影响程序状态。
/* process port resume request */
ata_eh_handle_port_resume(ap);//调用ap->ops->port_resume=ahci_port_resume来复位端口,详细流程见ahci驱动
/* fetch & clear EH info */
spin_lock_irqsave(ap->lock, flags);
ata_for_each_link(link, ap, HOST_FIRST) {
struct ata_eh_context *ehc = &link->eh_context;
struct ata_device *dev;
memset(&link->eh_context, 0, sizeof(link->eh_context));
link->eh_context.i = link->eh_info;
memset(&link->eh_info, 0, sizeof(link->eh_info));
ata_for_each_dev(dev, link, ENABLED) {
int devno = dev->devno;
ehc->saved_xfer_mode[devno] = dev->xfer_mode;
if (ata_ncq_enabled(dev))
ehc->saved_ncq_enabled |= 1 << devno;
}
}
ap->pflags |= ATA_PFLAG_EH_IN_PROGRESS;
ap->pflags &= ~ATA_PFLAG_EH_PENDING;
ap->excl_link = NULL; /* don't maintain exclusion over EH */
spin_unlock_irqrestore(ap->lock, flags);
/* invoke EH, skip if unloading or suspended */
if (!(ap->pflags & (ATA_PFLAG_UNLOADING | ATA_PFLAG_SUSPENDED)))
ap->ops->error_handler(ap);//调用ahci_error_handler来处理异常,详细流程见ahci驱动
else {
/* if unloading, commence suicide */
if ((ap->pflags & ATA_PFLAG_UNLOADING) &&
!(ap->pflags & ATA_PFLAG_UNLOADED))
ata_eh_unload(ap);
ata_eh_finish(ap);
}
/* process port suspend request */
ata_eh_handle_port_suspend(ap);//冻结端口后调用ahci_port_suspend,详细流程见ahci驱动
/* Exception might have happened after ->error_handler
* recovered the port but before this point. Repeat
* EH in such case.
*/
spin_lock_irqsave(ap->lock, flags);
if (ap->pflags & ATA_PFLAG_EH_PENDING) {
if (--ap->eh_tries) {
spin_unlock_irqrestore(ap->lock, flags);
goto repeat;
}
ata_port_err(ap,
"EH pending after %d tries, giving up\n",
ATA_EH_MAX_TRIES);
ap->pflags &= ~ATA_PFLAG_EH_PENDING;
}
/* this run is complete, make sure EH info is clear */
ata_for_each_link(link, ap, HOST_FIRST)
memset(&link->eh_info, 0, sizeof(link->eh_info));
/* end eh (clear host_eh_scheduled) while holding
* ap->lock such that if exception occurs after this
* point but before EH completion, SCSI midlayer will
* re-initiate EH.
*/
ap->ops->end_eh(ap);//ata_std_end_eh-> host->host_eh_scheduled = 0;
spin_unlock_irqrestore(ap->lock, flags);
ata_eh_release(ap);
} else {
WARN_ON(ata_qc_from_tag(ap, ap->link.active_tag) == NULL);
ap->ops->eng_timeout(ap);
}
scsi_eh_flush_done_q(&ap->eh_done_q);
/* clean up */
spin_lock_irqsave(ap->lock, flags);
if (ap->pflags & ATA_PFLAG_LOADING)
ap->pflags &= ~ATA_PFLAG_LOADING;
else if ((ap->pflags & ATA_PFLAG_SCSI_HOTPLUG) &&
!(ap->flags & ATA_FLAG_SAS_HOST))
schedule_delayed_work(&ap->hotplug_task, 0);
if (ap->pflags & ATA_PFLAG_RECOVERED)
ata_port_info(ap, "EH complete\n");
ap->pflags &= ~(ATA_PFLAG_SCSI_HOTPLUG | ATA_PFLAG_RECOVERED);
/* tell wait_eh that we're done */
ap->pflags &= ~ATA_PFLAG_EH_IN_PROGRESS;
wake_up_all(&ap->eh_wait_q);
spin_unlock_irqrestore(ap->lock, flags);
}ata_qc_complete_multiple
命令完成处理函数。
命令发起过程出错后调用 ata_qc_complete
命令处理完成后的中断函数中调用 ata_qc_complete_multiple->ata_qc_complete
0-> ahci_handle_port_interrupt //读取SActive(SCR3)寄存器获取qc_active
1-> ata_qc_complete_multiple //将qc_active转换为完成命令的tag
2-> ata_qc_from_tag //通过tag获取命令qc
2-> ata_qc_complete
3-> __ata_qc_complete
4-> ata_sg_clean //清除qc中的sg指针
4-> link->sactive &= ~(1 << qc->hw_tag); //清除NCQ的对应tag
4-> qc->complete_fn 调用执行ata_qc_issue前注册的完成函数qc->complete_fn = ata_qc_complete_internal (libata-core.c)
ata内部命令时,qc->complete_fn = ata_qc_complete_internal;
ata_qc_complete_internal
-> complete(waiting);
static void ata_qc_complete_internal(struct ata_queued_cmd *qc)
{
struct completion *waiting = qc->private_data;
complete(waiting);
}qc->complete_fn = ata_scsi_qc_complete (libata-scsi.c)
scsi下发命令时,qc->complete_fn = ata_scsi_qc_complete;
ata_scsi_qc_complete
-> ata_gen_passthru_sense 或 ata_gen_ata_sense
-> ata_qc_done
-> qc->scsidone(qc->scsicmd)
ata_scsi_queuecmd //入队scsi命令时将命令完成接口赋值给了qc完成接口
qc->scsidone = cmd->scsi_done;
blk块设备层根据不同模式有两种命令发送接口:
//mq模式,新内核版本加入mq功能,在软件层面添加多个命令队列(一个core一个队列),再由调度机制将软件队列的命令分发到设备硬件队列。
scsi_queue_rq
-> cmd->scsi_done = scsi_mq_done;
-> scsi_dispatch_cmd //ata_scsi_queuecmd//非mq模式
scsi_request_fn
-> cmd->scsi_done = scsi_done;
-> scsi_dispatch_cmd //ata_scsi_queuecmd
static void ata_scsi_qc_complete(struct ata_queued_cmd *qc)
{
struct ata_port *ap = qc->ap;
struct scsi_cmnd *cmd = qc->scsicmd;
u8 *cdb = cmd->cmnd;
int need_sense = (qc->err_mask != 0);
/* For ATA pass thru (SAT) commands, generate a sense block if
* user mandated it or if there's an error. Note that if we
* generate because the user forced us to [CK_COND =1], a check
* condition is generated and the ATA register values are returned
* whether the command completed successfully or not. If there
* was no error, we use the following sense data:
* sk = RECOVERED ERROR
* asc,ascq = ATA PASS-THROUGH INFORMATION AVAILABLE
*/
if (((cdb[0] == ATA_16) || (cdb[0] == ATA_12)) &&
((cdb[2] & 0x20) || need_sense))
ata_gen_passthru_sense(qc);
else if (qc->flags & ATA_QCFLAG_SENSE_VALID)
cmd->result = SAM_STAT_CHECK_CONDITION;
else if (need_sense)
ata_gen_ata_sense(qc);
else
cmd->result = SAM_STAT_GOOD;
if (need_sense && !ap->ops->error_handler)
ata_dump_status(ap->print_id, &qc->result_tf);
ata_qc_done(qc);
}
static void ata_qc_done(struct ata_queued_cmd *qc)
{
struct scsi_cmnd *cmd = qc->scsicmd;
void (*done)(struct scsi_cmnd *) = qc->scsidone;
ata_qc_free(qc);
done(cmd);
}blk层的
-
scsi_mq_done
static void scsi_mq_done(struct scsi_cmnd *cmd)
{
trace_scsi_dispatch_cmd_done(cmd);
blk_mq_complete_request(cmd->request);//最后唤醒软中断线程调用scsi_softirq_done
}-
scsi_done
static void scsi_done(struct scsi_cmnd *cmd)
{
trace_scsi_dispatch_cmd_done(cmd);
blk_complete_request(cmd->request);//最后唤醒软中断线程调用scsi_softirq_done
}scsi_finish_command
scsi_finish_command
-> scsi_device_unbusy //减少活跃命令数量,如果此时有错误则触发scsi_eh_wakeup,如果减少后的数量刚好和错误数量相同且不为0则会调用到scsi_error_handler
-> drv->done(cmd); //如果为存储设备,即驱动为sd.c,则在sd_template中为sd_done,详细见sd驱动(待补充)
-> scsi_io_completion //内容待完善
void scsi_finish_command(struct scsi_cmnd *cmd)
{
struct scsi_device *sdev = cmd->device;
struct scsi_target *starget = scsi_target(sdev);
struct Scsi_Host *shost = sdev->host;
struct scsi_driver *drv;
unsigned int good_bytes;
scsi_device_unbusy(sdev);
/*
* Clear the flags that say that the device/target/host is no longer
* capable of accepting new commands.
*/
if (atomic_read(&shost->host_blocked))
atomic_set(&shost->host_blocked, 0);
if (atomic_read(&starget->target_blocked))
atomic_set(&starget->target_blocked, 0);
if (atomic_read(&sdev->device_blocked))
atomic_set(&sdev->device_blocked, 0);
/*
* If we have valid sense information, then some kind of recovery
* must have taken place. Make a note of this.
*/
if (SCSI_SENSE_VALID(cmd))
cmd->result |= (DRIVER_SENSE << 24);
SCSI_LOG_MLCOMPLETE(4, sdev_printk(KERN_INFO, sdev,
"Notifying upper driver of completion "
"(result %x)\n", cmd->result));
good_bytes = scsi_bufflen(cmd);
if (!blk_rq_is_passthrough(cmd->request)) {
int old_good_bytes = good_bytes;
drv = scsi_cmd_to_driver(cmd);
if (drv->done)
good_bytes = drv->done(cmd);
/*
* USB may not give sense identifying bad sector and
* simply return a residue instead, so subtract off the
* residue if drv->done() error processing indicates no
* change to the completion length.
*/
if (good_bytes == old_good_bytes)
good_bytes -= scsi_get_resid(cmd);
}
scsi_io_completion(cmd, good_bytes);
}scsi_io_completion
热插拔
ata_scsi_hotplug (待补充)
ata_port_alloc初始化阶段配置ap->hotplug_task为ata_scsi_hotplug
void ata_scsi_hotplug(struct work_struct *work)
{
struct ata_port *ap =
container_of(work, struct ata_port, hotplug_task.work);
int i;
if (ap->pflags & ATA_PFLAG_UNLOADING) {
DPRINTK("ENTER/EXIT - unloading\n");
return;
}
while (pm_freezing)
msleep(10);
DPRINTK("ENTER\n");
mutex_lock(&ap->scsi_scan_mutex);
ata_scsi_handle_link_detach(&ap->link);
if (ap->pmp_link)
for (i = 0; i < SATA_PMP_MAX_PORTS; i++)
ata_scsi_handle_link_detach(&ap->pmp_link[i]);
/* scan for new ones */
ata_scsi_scan_host(ap, 0);
mutex_unlock(&ap->scsi_scan_mutex);
DPRINTK("EXIT\n");
}trace机制见文章Linux TraceEvent – 我见过的史上最长宏定义 | 码农家园 (codenong.com)、Linux ftrace 2.2、trace event的使用_pwl999的博客-CSDN博客。
调用trace_scsi_dispatch_cmd_done后,linux系统中mount -t debugfs none /sys/kernel/debug/,便能在/sys/kernel/debug/tracing/events/scsi目录下看到scsi_dispatch_cmd_done
root@firefly:/sys/kernel/debug/tracing/events/scsi# ll
total 0
drwxr-xr-x 7 root root 0 Jan 29 10:42 ./
drwxr-xr-x 103 root root 0 Jan 1 1970 ../
-rw-r--r-- 1 root root 0 Jan 29 10:42 enable
-rw-r--r-- 1 root root 0 Jan 29 10:42 filter
drwxr-xr-x 2 root root 0 Jan 29 10:42 scsi_dispatch_cmd_done/
drwxr-xr-x 2 root root 0 Jan 29 10:42 scsi_dispatch_cmd_error/
drwxr-xr-x 2 root root 0 Jan 29 10:42 scsi_dispatch_cmd_start/
drwxr-xr-x 2 root root 0 Jan 29 10:42 scsi_dispatch_cmd_timeout/
drwxr-xr-x 2 root root 0 Jan 29 10:42 scsi_eh_wakeup/
root@firefly:/sys/kernel/debug/tracing/events/scsi#
root@firefly:/sys/kernel/debug/tracing/events/scsi# ll scsi_dispatch_cmd_done
total 0
drwxr-xr-x 2 root root 0 Jan 29 10:42 ./
drwxr-xr-x 7 root root 0 Jan 29 10:42 ../
-rw-r--r-- 1 root root 0 Jan 29 10:42 enable
-rw-r--r-- 1 root root 0 Jan 29 10:42 filter
-r--r--r-- 1 root root 0 Jan 29 10:42 format
-r--r--r-- 1 root root 0 Jan 29 10:42 id
-rw-r--r-- 1 root root 0 Jan 29 10:42 trigger














 1225
1225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









