







第二章 提供推荐
推荐的方式主要分为两类,一种是基于物品的推荐,一种是基于用户的推荐。基于物品的推荐,就是计算物品之间的相似度,例如物品A和物品B相似,假如用户购买了物品A,则用户极有可能购买物品B。基于用户的推荐就是找到相似的用户,例如“用户A购买了商品A和商品B,用户B购买了商品A,假如经过计算,用户A和用户B是相似的,则用户B极有可能购买商品B。
在数据量大的情况下,基于物品的过滤能够得到更好的结论,因为物品之间的比较不会像用户间的比较那么频繁变化,且它允许我们将大量的任务预先执行,从而更快的给出推荐结果。
文中介绍了两种相似度计算方法:欧几里得距离和皮尔逊相关度
欧几里得距离:欧几里得距离是非常简单的相似度计算,他将人们都评价过的物品作为坐标轴,将参与评价的人绘制到图上,并考察他们距离的远近,他们的距离越近,表明他们越相似,如下图:
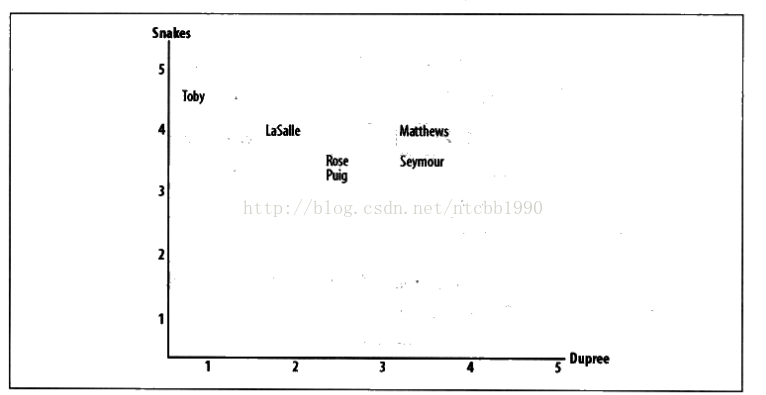
皮尔逊相关度:是一种更为复杂的计算相似度的方法,它是判断两组数据与某条直线拟合的程度的一种度量。如果某人总是倾向于比另一个人更高的分,而两者的分值之差总是保持一致,则他们仍然存在很好的相关性。而欧几里得距离的评价方法会应为一个人的评价始终比另一个人严格,得出两个人不相似的结论,即是他们的品味相似。如下图所示:

第三章 聚类
分级聚类
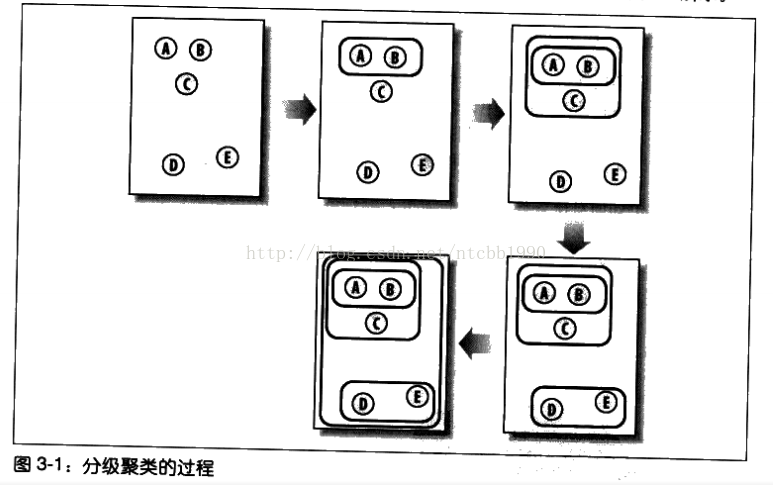
分级聚类通过不断的将最为相似的群组两两合并,构造出一个族群的层级结构。在每次迭代过程中,分级聚类算法会计算两个组群见的距离,并将距离最近的两个组群合并成一个新的组群,知道剩下一个族群。如图所示:
K-均值聚类
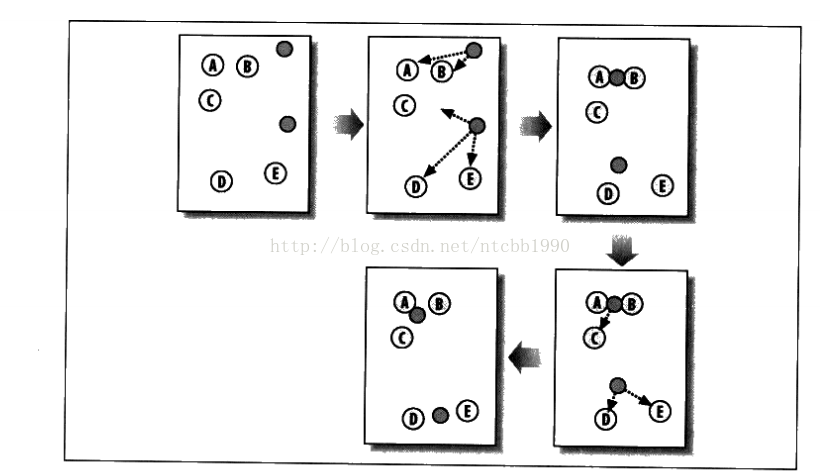
K-均值聚类算法首先会随机确定K个中心位置,然后将各个数据项分配给最邻近的中心点。待分配完成后,聚类中心就会移到分配给该聚类的所有节点的平均处,然后整个分配过程重新开始。这一过程一直重复下去,知道分配过程不再变化,下图显示了这一过程,其中涉及了五个数据项和连个聚类。















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









