







机器学习–监督学习部分算法总结
KNN算法:
KNN即最近邻算法,其主要过程为:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
2. 对上面所有的距离值进行排序;
3. 选前k个最小距离的样本;
4. 根据这k个样本的标签进行投票,得到最后的分类类别;
如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。
近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。
决策树:
决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。
信息熵的计算公式如下:
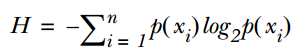
其中的n代表有n个分类类别(比如假设是2类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率p1和p2,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性xi用来进行分枝,此时分枝规则是:如果xi=vx的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵H1和H2,计算出分枝后的总信息熵H’=p1*H1+p2*H2.,则此时的信息增益ΔH=H-H’。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。
决策树的优点:
计算量简单,可解释性强,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
缺点:
容易过拟合(后续出现了随机森林,减小了过拟合现象);
朴素贝叶斯:
有以下几个地方需要注意:
1. 如果给出的特征向量长度可能不同,这是需要归一化为通长度的向量(这里以文本分类为例),比如说是句子单词的话,则长度为整个词汇量的长度,对应位置是该单词出现的次数。
2. 计算公式如下:
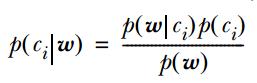
其中一项条件概率可以通过朴素贝叶斯条件独立展开。要注意一点就是 的计算方法,而由朴素贝叶斯的前提假设可知,
的计算方法,而由朴素贝叶斯的前提假设可知,  =
=  ,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。
,因此一般有两种,一种是在类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本的总和;第二种方法是类别为ci的那些样本集中,找到wj出现次数的总和,然后除以该样本中所有特征出现次数的总和。
3. 如果 中的某一项为0,则其联合概率的乘积也可能为0,即2中公式的分子为0,为了避免这种现象出现,一般情况下会将这一项初始化为1,当然为了保证概率相等,分母应对应初始化为2(这里因为是2类,所以加2,如果是k类就需要加k,术语上叫做laplace光滑, 分母加k的原因是使之满足全概率公式)。
朴素贝叶斯的优点:
对小规模的数据表现很好,适合多分类任务,适合增量式训练。
缺点:
对输入数据的表达形式很敏感。
Logistic回归:
Logistic是用来分类的,是一种线性分类器,需要注意的地方有:
1. logistic函数表达式为:

其导数形式为:
2. logsitc回归方法主要是用最大似然估计来学习的,所以单个样本的后验概率为:

到整个样本的后验概率:

其中:

通过对数进一步化简为:

3. 其实它的loss function为-l(θ),因此我们需使loss function最小,可采用梯度下降法得到。梯度下降法公式为:


Logistic回归优点:
1、实现简单;
2、分类时计算量非常小,速度很快,存储资源低;
缺点:
1、容易欠拟合,一般准确度不太高
2、只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









