










HashMap源码分析(Android&Java)
转载请注明出处chendong_
写在前面
基本的数据结构有,数组,链表,树,图。
数组的特点是长度固定,空间连续,占用内存很大,空间复杂度是O(n),但是寻址容易,时间复杂度O(1).
总结:寻址容易,插入删除困难。
链表的特点是长度可变,存储空间离散,占用内存小,空间复杂度是O(1),但是寻址困难,时间复杂度为O(n).
总结:寻址困难,插入删除容易。
哈希表基于数组结构,采用键值的方式存储数据,插入删除容易,寻址是根据键值直接查找数据,时间复杂度是O(1),但是使用哈希值存储数据总会出现哈希冲突,解决哈希冲突的方法主要有,开放定址法(再散列),再哈希法,链地址法(拉链法),建立公共溢出区。
缺点:存储空间填满时需要将其复制到另一个更大的数组结构中,并进行再哈希计算,这是哈希表内存占用的暴涨点,这是基于数组结构的一个缺点。
哈希表不能以一种特定的顺序遍历数据结构中的所有数据,如果需要按序存储,使用哈希表并不合适
贴一张图,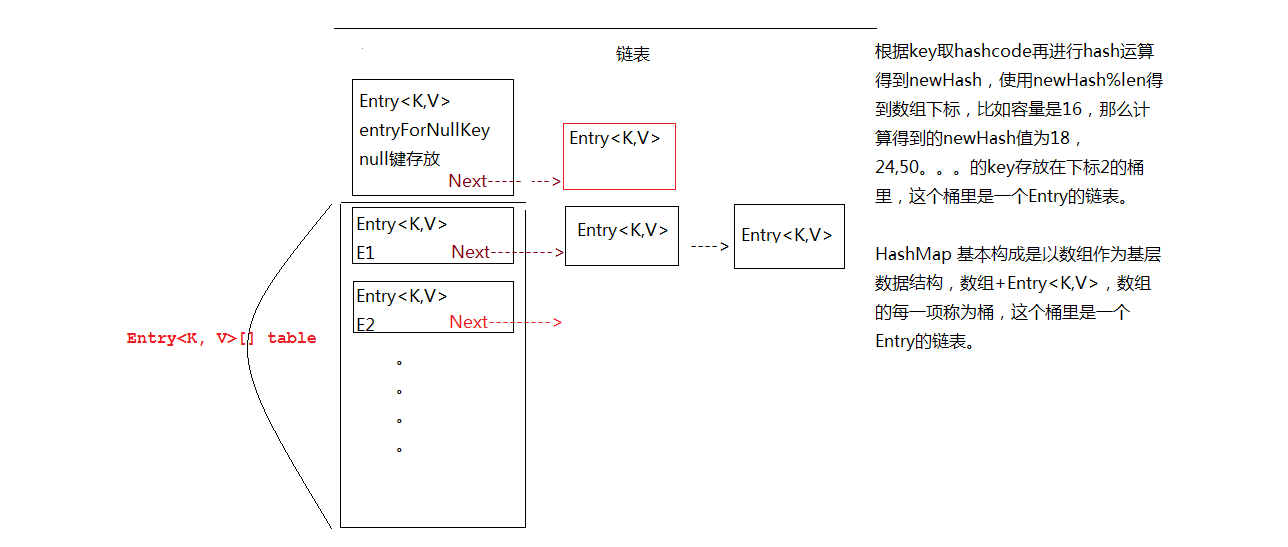
开始
1.HashMap是线程不安全的HashTable是线程安全的。
2.HashMap就是基于链地址法实现的数据存储。也就是链表的数组。
3.HashMap允许键 值 为null。HashTable是不允许的。
4.在Android和Java里面对HashMap的实现,稍有不同,开始我还以为是我的jdk有问题。
5.在HashMap的基础数组中,每一个数组项称之为一个桶,HashMap就是基于这种桶+链表的结构。
6.存储方式,使用key值取哈希,一般的算法是hash(key)/len获得他存放位置的下标,这样就将key与下标对应起来。
了解
源码:
private transient Set<Entry<K, V>> entrySet;
transient HashMapEntry<K, V>[] table;
总结来说,HashMap就是数组+内部类(Entry)实现,Entry中具有下一个Entry的引用,由此构成了链表的结构。之前看过有人介绍说是Set+静态内部类,其实并不是。第一行的代码是用来对HashMap进行操作时使用的变量,比如迭代HashMap所有的子项,添加一个EntrySet到HashMap中,删除,修改。。。。
1.HashMapEntry
HashMap中有一个很重要的存储结构HashMapEntry,用来保存键值对,和下一个Entry的引用,这就形成了一个链表结构。
在Java中,这个静态内部类叫Entry
static class HashMapEntry<K, V> implements Entry<K, V> {
final K key;
V value;
final int hash;
HashMapEntry<K, V> next;
HashMapEntry(K key, V value, int hash, HashMapEntry<K, V> next) {
this.key = key;
this.value = value;
this.hash = hash;
this.next = next;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V value) {
V oldValue = this.value;
this.value = value;
return oldValue;
}
@Override public final boolean equals(Object o) {
if (!(o instanceof Entry)) {
return false;
}
Entry<?, ?> e = (Entry<?, ?>) o;
return Objects.equal(e.getKey(), key)
&& Objects.equal(e.getValue(), value);
}
@Override public final int hashCode() {
return (key == null ? 0 : key.hashCode()) ^
(value == null ? 0 : value.hashCode());
}
@Override public final String toString() {
return key + "=" + value;
}
}2.哈希值的计算
存储数据是根据key的哈希值来存储的,类似这样的方法hash(key.hashcode())
Java和Android中对求哈希值的操作相似但是哈希算法不同,当进行存取操作时,key都需要使用这个算法进行中转。
在Android中使用的是Collections类下的静态方法及进行哈希计算,但是这里的h是key的hashcode(),看注释使用的是Wang/Jenkins哈希算法的变体,源代码:
private static int secondaryHash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}在Java中哈希算法在本类实现,相比android简洁许多,虽然我现在还看不懂
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}3.put方法
检查键值是否为空,null时将存储到forNullEntry所在的链表中。
获取哈希值之后获得下标索引,检查key是否已经存在,是则替换,否则添加到当前链表,基本思想是这样的,几个不同的点
putForNullKey(value)方法,在Android和Java中都有实现,当键值为null时,分配一个数组的一项,这个数组指向key == null 的Entry
一个不同点,Java中是在添加Entry之后重新计算容量,而Android是在AddNewEntry之前进行。
扩容的方法都是扩大为原来的两倍。
在java中的实现代码:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
//计算hash值,使用indexFor()这个函数获得该哈希值对应数组下标,由此可以得到对应的那个链表。
int i = indexFor(hash, table.length );
for (Entry<K,V> e = table [i]; e != null; e = e.next) {
Object k;
//关注这部分代码是替换掉已经存在的key对应的value
if (e.hash == hash && ((k = e.key ) == key || key.equals(k))) {
V oldValue = e. value;
e. value = value;
e.recordAccess( this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null ;
}
//解释一下这部分代码,做的操作就是将新添加的Entry放在链表的头部,而原来的链表会接在这个新的Entry后面。
void addEntry(int hash, K key, V value, int bucketIndex) {
//注意这里的bucketIndex是上一个函数得到的数组下标。取到该数组项链接的Entry给了临时变量e
Entry<K,V> e = table [bucketIndex];
//新建了一个Entry将其链接到了数组项上,然后把e给了新的Entry的Next,也就是后面的链表重新链接到了新的Entry后面,而新的Entry作为了该链表的第一项。
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//添加之后重新计算容量。
if (size ++ >= threshold)
resize(2 * table.length );
}
在Android中的实现基本类似,使用Collections静态方法进行二次哈希计算,计算下表索引
@Override
public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
//注意这里是先进行扩容后进行添加的
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
//Android添加代码就更简单了,不过也很好理解,操作与java中是一样的。不过方法很巧//妙,简化了代码,让我想起了InputStream is = new FileInputStream("path")is = new BufferedInputStream(is)`
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}4.get方法
同样的获取hashcode,再哈希计算哈希值,获得下标索引,得到对应链表,遍历链表得到结果,在Java和Android中实现大同小异.
java中的实现
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table [indexFor(hash, table.length )];
e != null;
e = e. next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value ;
}
return null;
}Android中的实现
public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
return e == null ? null : e.value;
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
return e.value;
}
}
return null;
}5.初始化
在Java和Android中HashMap的初始化略有不同,太坑爹了。
Android中初始容量是2,Java中初始容量是16。
Java中的初始容量和负载因子是学习Java比较经典的内容,看一下Java中HashMap的默认构造方法
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
//默认的构造方法会初始化一个容量是16,负载因子0.75的HashMap,threshold有阈值的意思,就是当前容量可以承受的负载,当超过这个负载时就会进行扩容。
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int )(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR );
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}带有参数的构造方法实现
//指定容量和负载因子时会检查容量和负载因子的值是不是有问题,然后会进行一个位运算算法获得-》大于当前要求的容量的-》最小的2的幂(也就是如果是7--》8如果是9--》16)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +loadFactor);
// Find a power of 2 >= initialCapacity
//算法原理:capacity初始为1,当capacity小于initialCapacity时左移一位,就是*2,直到找到大于当前要求的容量最小的2的幂
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int )(capacity * loadFactor);
table = new Entry[capacity];
init();
}
//容量增加,transfer(newTable);会将原来的数据再哈希重新放入数据
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length ;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
在Android中的实现
//默认的初始最小容量是4,一个静态的初始数组的容量是最小容量无符号右移1位,也就是2,默认构造时,会将该静态数组交给table,这里有一行源码的注释( Forces first put invocation to replace EMPTY_TABLE),意思是根据第一次put方法加入的数量来扩充数组,此时负载容量是-1,添加时会立刻扩充容量,这可能也是为什么Android中添加元素是先检查扩充容量再添加的原因。。在put时第一次百分百检测到容量不够,此时进行一次doubleCapacity()将容量加倍,在这个方法中会调用
private static final int MINIMUM_CAPACITY = 4;
private static final Entry[] EMPTY_TABLE
= new HashMapEntry[MINIMUM_CAPACITY >>> 1];
public HashMap() {
table = (HashMapEntry<K, V>[]) EMPTY_TABLE;
threshold = -1; // Forces first put invocation to replace EMPTY_TABLE
}
//容量增长或初始化时会调用该方法,重置阈值,与Java稍有不同,使用固定的容量的3/4来作为阈值,Java中还要比较容量的大小,取Math.min(容量,)
private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
int newCapacity = oldCapacity * 2;
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {
return newTable;
}
for (int j = 0; j < oldCapacity; j++) {
/*
* Rehash the bucket using the minimum number of field writes.
* This is the most subtle and delicate code in the class.
*/
HashMapEntry<K, V> e = oldTable[j];
if (e == null) {
continue;
}
int highBit = e.hash & oldCapacity;
HashMapEntry<K, V> broken = null;
newTable[j | highBit] = e;
for (HashMapEntry<K, V> n = e.next; n != null; e = n, n = n.next) {
int nextHighBit = n.hash & oldCapacity;
if (nextHighBit != highBit) {
if (broken == null)
newTable[j | nextHighBit] = n;
else
broken.next = n;
broken = e;
highBit = nextHighBit;
}
}
if (broken != null)
broken.next = null;
}
return newTable;
}
private HashMapEntry<K, V>[] makeTable(int newCapacity) {
@SuppressWarnings("unchecked") HashMapEntry<K, V>[] newTable
= (HashMapEntry<K, V>[]) new HashMapEntry[newCapacity];
table = newTable;
//阈值时是容量的3/4,使用了位运算
threshold = (newCapacity >> 1) + (newCapacity >> 2); // 3/4 capacity
return newTable;
}
//同样的检查机制,然后使用了一个方法,又是Collections类中的方法Collections.roundUpToPowerOfTwo(capacity);,作用是一样的,将容量修改为大于输入容量的最小的2的幂。但是使用二进制实现,会不会更牛逼一点。
public HashMap(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("Capacity: " + capacity);
}
if (capacity == 0) {
@SuppressWarnings("unchecked")
HashMapEntry<K, V>[] tab = (HashMapEntry<K, V>[]) EMPTY_TABLE;
table = tab;
threshold = -1; // Forces first put() to replace EMPTY_TABLE
return;
}
if (capacity < MINIMUM_CAPACITY) {
capacity = MINIMUM_CAPACITY;
} else if (capacity > MAXIMUM_CAPACITY) {
capacity = MAXIMUM_CAPACITY;
} else {
capacity = Collections.roundUpToPowerOfTwo(capacity);
}
makeTable(capacity);
}
//看不懂啊,应该收藏一下关于二进制的算法,高大上的别人都看不懂
public static int roundUpToPowerOfTwo(int i) {
i--; // If input is a power of two, shift its high-order bit right.
// "Smear" the high-order bit all the way to the right.
i |= i >>> 1;
i |= i >>> 2;
i |= i >>> 4;
i |= i >>> 8;
i |= i >>> 16;
return i + 1;
}















 7173
7173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









