







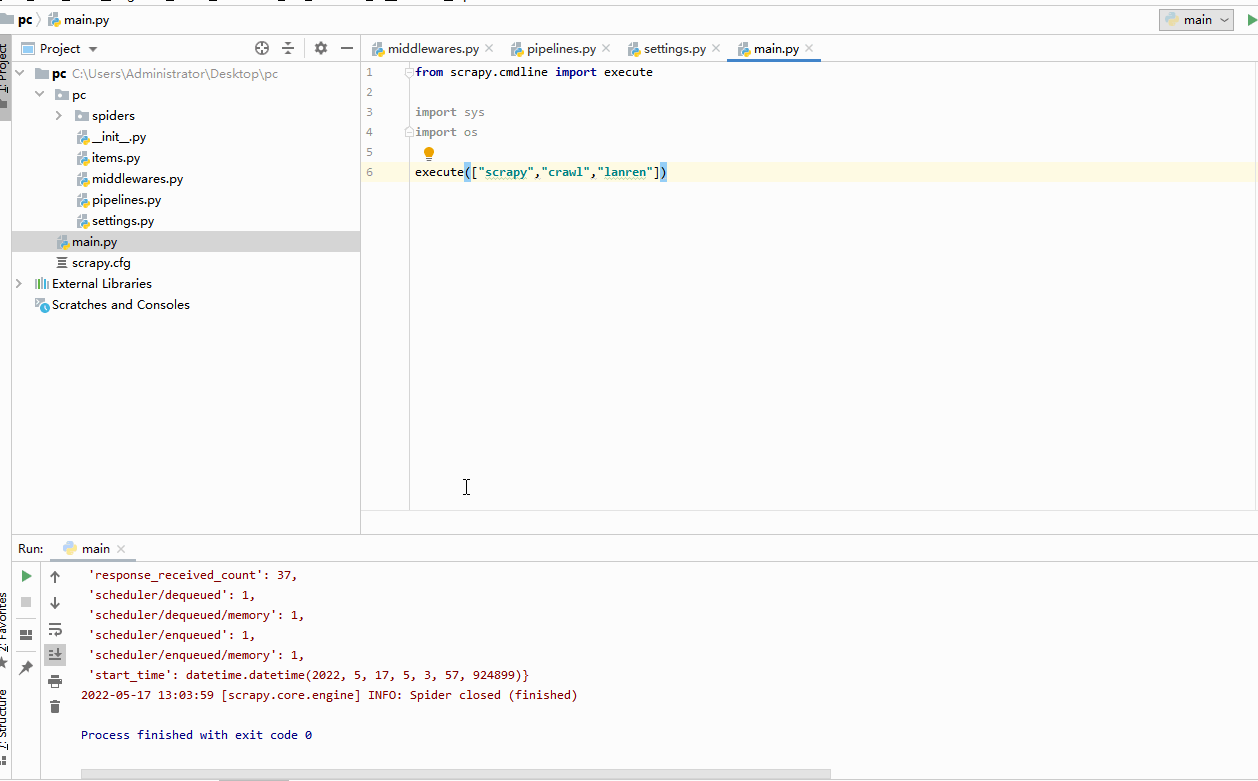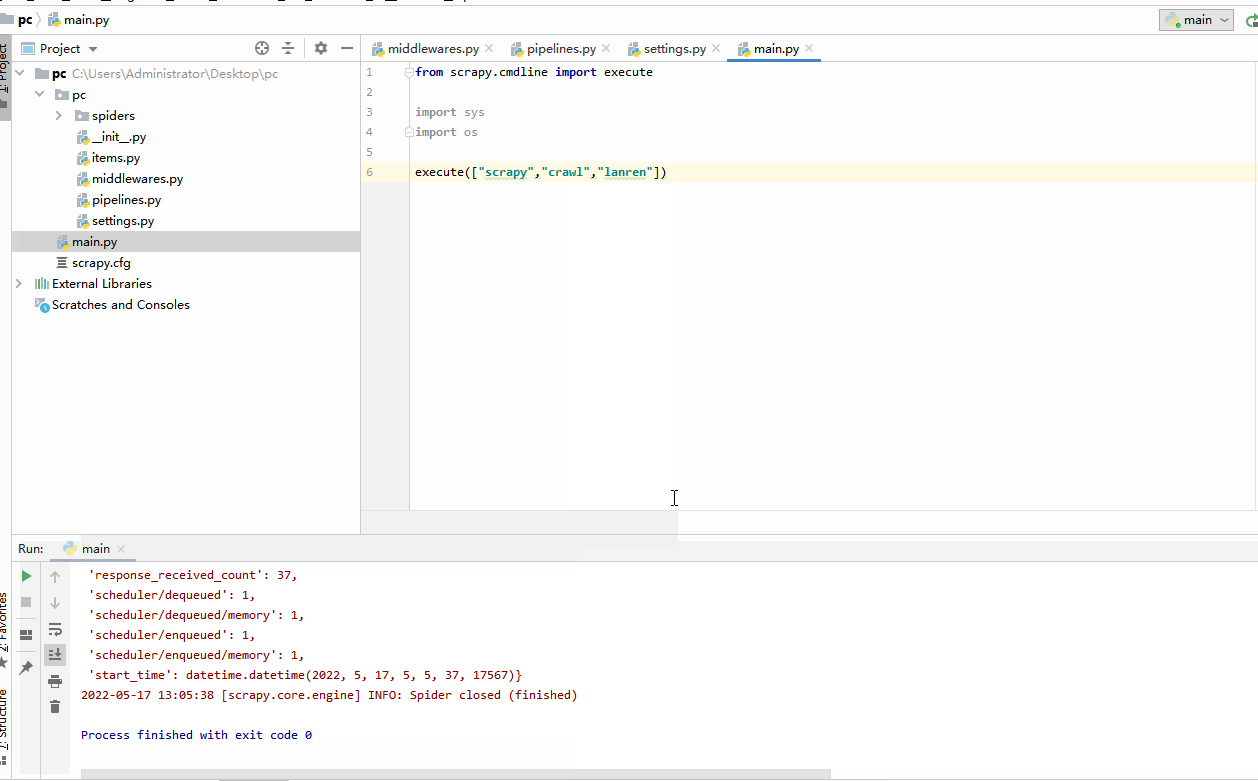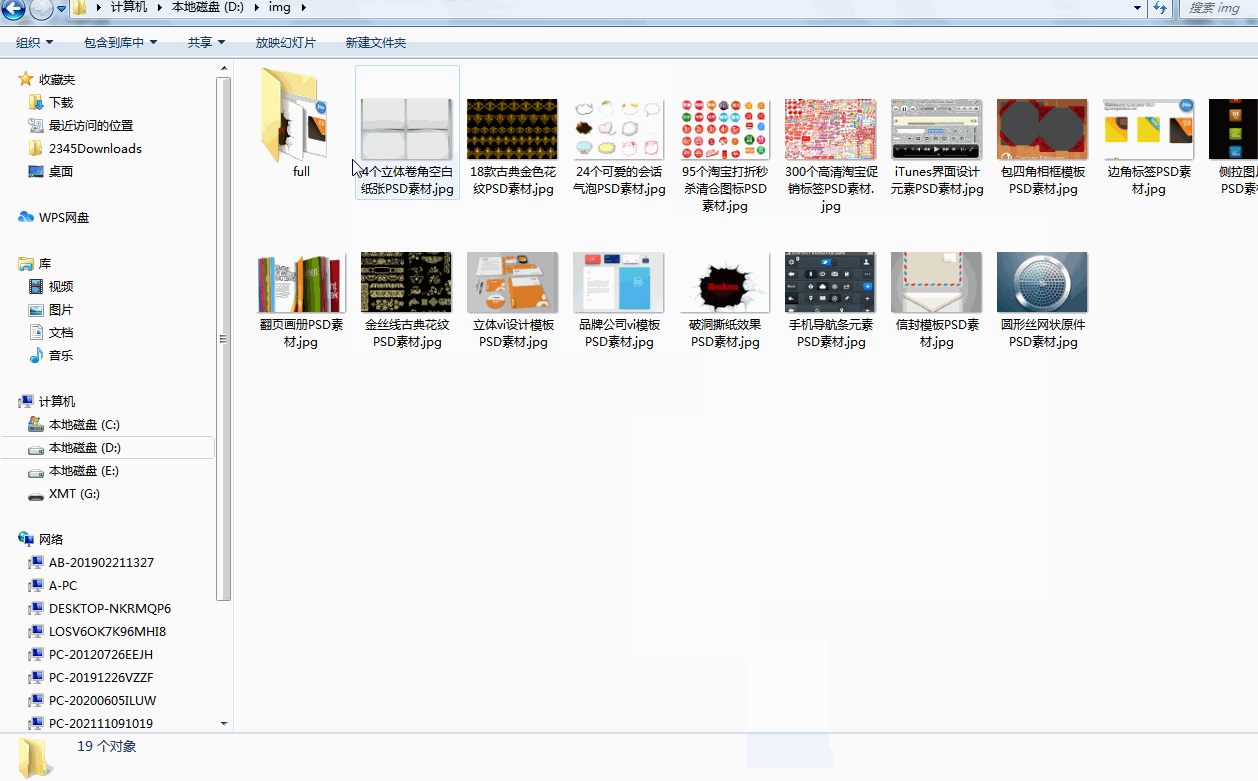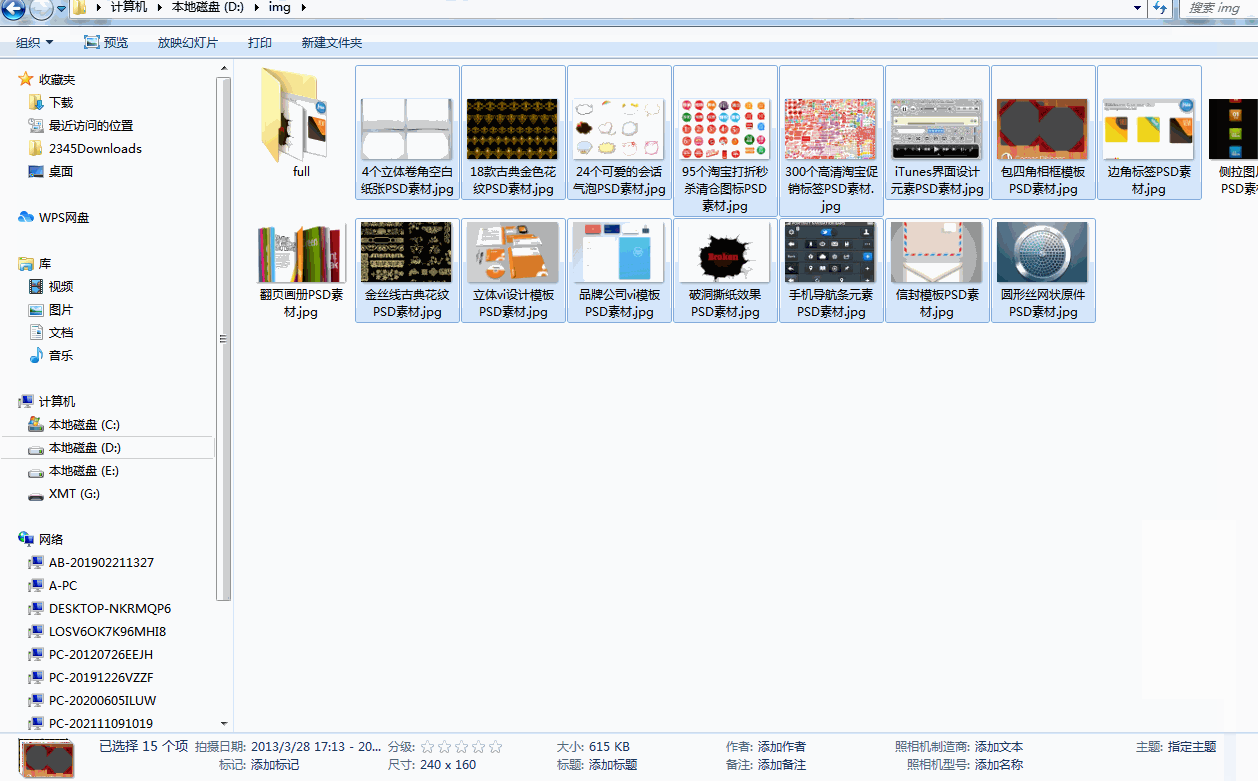
效果如下:
spider.py
1.导入用于保存文件下载信息的item类.
2.在爬虫类中解析文件url,并保存在列表中,根据需要提取标题等其它信息
3.返回赋值后的item类
import scrapy
from ..items import FileItem
class MySpider(Spider):
def parse(self,response):
file_names = response.xpath('xxxxxxxx') #list,获取文件名称列表
fileUrls = response.xpath('xxxxxxxx') #list,获取文件链接列表
#fileUrl为相对路径时,可用response.urljoin(url)进行拼接
item = FileItem(file_names = file_names, file_urls = fileUrls )
yield item #注意:此处为yield,不是return
items.py
定义一个item,必须包含file_urls和files两个字段。根据实际情况,可以增加其它字段
file_urls,list类型,用来存储需下载的url列表。
files,list类型,用于保存下载结果信息,包括:
本地路径:path
文件的校验和:Checksum
文件和URL地址:URL。
import scrapy
class FileItem(scrapy.Item):
file_urls = scrapy.Field()
files = scrapy.Field()
file_names = scrapy.Field()
settings.py
启动pipline
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#fileDownloadProject为工程名
#'fileDownloadProject.pipelines.MyFilePipeline':1, #使用自定义继承类重命名、改路径时使用,调整优先级为最高(1)
#'scrapy.pipelines.files.FilesPipeline':1 #自动保存时使用,引入FilesPipeline,优先级设为最高,此时无需编写pipline
}
设置存储路径,FILES_STORE (变量名不能错)
FILES_STORE = 'xxxxxxxxxxxxx' #新增变量,并赋值表示路径的字符串,只能指定一个路径
pipelines.py
pipeline可以不编写,通过scrapy.pipelines.files.FilesPipeline对象自动保存文件。
若需进行重命名、更改存储路径等操作,可编写继承类,并重载file_path等类方法,注意先调用父类方法,获得原路径。
下面为重新分配路径时的示例:
from scrapy.pipelines.files import FilesPipeline
import re
class MyFilePipeline(FilesPipeline):
#file_path参数中没有item对象,需重写get_media_requests获取item(FileItem)中的信息
def get_media_requests(self,item,info):
# 该方法调用在文件下载之前。它从item(示例中为FileItem的值)中提取文件url并向服务器发送下载请求。
file_requests = super(MyFilesPipeline, self).get_media_requests(item, info)
for i in range(len(file_requests)):
# 将item中file_names属性的第i个名称传至对应单个文件下载请求,使file_path可以通过request获得所需的item值
file_requests[i].meta['name'] = item['file_names'][i]
return file_requests # 必须再次返回下载请求列表file_requests,否则不下载图片
def file_path(self,request,response=None, info=None):
# 调用原方法,获得原路径(full/xxx.xxx)
originPath = super(MyFilesPipeline, self).file_path(request, response, info)
title = request.meta['name'] #取出定义好的文件名
#原方法返回的路径默认为:'full/xxxxx.xxx',利用正则表达替换路径和文件名
#本示例将文件直接保存在settings定义的文件夹根目录下,并重命名
newPath = re.sub('full/.+\.', title + '.', originPath) #注意加点
return newPath #用新定义的路径代替默认路径
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











