







一、基本流程
决策树(decision tree)是一类常见的机器学习方法。它是基于树结构来进行决策的,这恰是人类在面临决策问题时一种很自然的处理机制。
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树,其基本流程道循简单且直观的“分而治之”(divide-and-conquer)策略。
1.1 决策树的结构
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。
根结点:包含样本全集;
内部结点:对应一个“子决策”,其包含的样本集合 根据属性测试的结果被划分到子结点中;
叶结点:对应于决策结果,其他每个结点则对应于一个属性测试;
从根结点到每个叶结点的路径对应了一个判定测试序列。
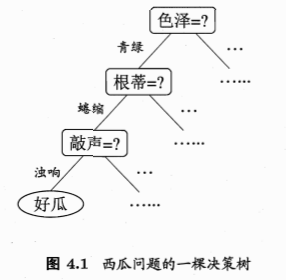
1.2 算法流程
显然,决策树的生成是一个递归过程。
它的三种递归返回情形:
1、当前结点包含的样本全属于同一类别,无需划分;
2、当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
3、当前结点包含的样本集合为空,不能划分。
在第 2 和 第 3 种情形下,我们把当前结点标记为叶结点。

二、划分选择
决策树学习的关键是 如何选择最优划分属性。
目标:随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
2.1 信息增益(ID3算法)
“信息熵”(information entropy) 是度量样本集合纯度最常用的一种指标。
假定 当前样本集合D 中第 k 类样本所占的比例(或称为概率)为 pk ( k=1,2,…,|y| ),则D的信息熵定义为:
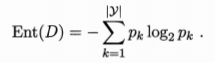
Ent(D)的值越小,则D的纯度越高。
某个离散属性 a 有 V 个可能的取值 {a1,a2,…,aV},若使用 a 来对样本集 D 进行划分,则会产生V个分支结点,其中第v个分支结点包含了D中所有在属性a上取值为av的样本,记为Dv。
我们可根据式(4.1)计算出Dv 的信息熵,再考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重|Dv|/|D|,即样本数越多的分支结点的影响越大,于是可计算出用属性a对样本集D进行划分所获得的“信息增益”(information gain):
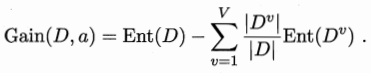
信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择,即在图4.2算法第8行选择属性a* 为Gain(D,a)最大的。著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性。
例子
以下表西瓜数据集为例,该数据集包含17个训练样例。
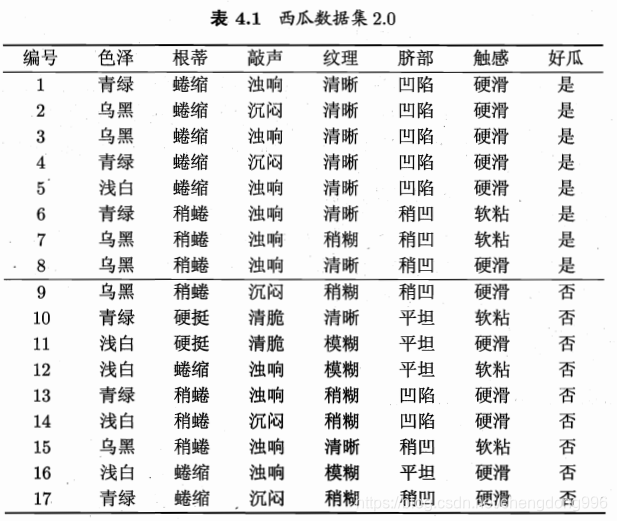
在决策树学习开始时,根结点包含D中的所有样例,其中正例占p1= 8/17,反例占p2= 9/17,根据式(4.1)可计算出根结点的信息熵为:
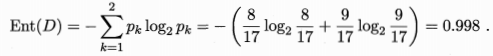
先考察 属性“色泽”,它有3个可能的取值 { 青绿,乌黑,浅白}若使用该属性对 D 进行划分,则可得到3个子集,分别记为:D1(色泽=青绿),D2(色泽=乌黑),D3(色泽=浅白)。
D1包含编号为 {1,4,6,10,13,17} 的 6个样例,其中正、反例分别占 p1= 3/6,p2= 3/6。
D2包含编号为 {2,3,7, 8, 9,15}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









