







1 flink 简介
1.1 flink是什么
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行状态计算
flink目前在国内企业的应用如下:

1.2 为什么要用flink
我们之所以要使用flink,因为:
- 流数据更真实地反映了我们的生活方式
- 传统的数据架构是基于有限数据集的
- 我们的目标:低延迟、高吞吐、结果的准确性和良好的容错性
flink的应用场景有:
- 电商和市场营销,如数据报表、广告投放、业务流程需要
- 物联网(IOT),传感器实时数据采集和显示、实时报警,交通运输业
- 电信业,基站流量调配
- 银行和金融业,实时结算和通知推送,实时检测异常行为
1.3 flink特点
- 事件驱动(Event-driven)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KDial1iC-1659267999905)(F:/note/image/envent-driver.png)]](https://img-blog.csdnimg.cn/b6b542cb20b1413ca95dc48a4cf6175f.png)
-
基于流的世界观
在 Flink 的世界观中,一切都是由流组成的,离线数据是有界的流;实时数据是一个没有界限的流: 这就是所谓的有界流和无界流
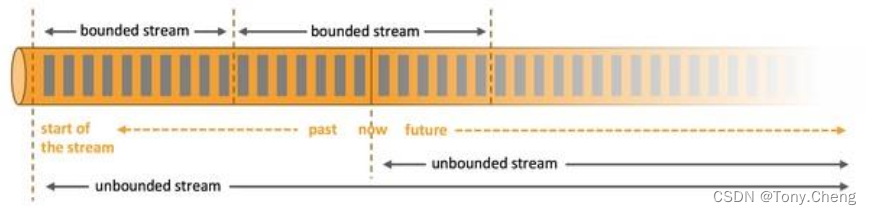
-
分层API
越顶层越抽象,表达含义越简明,使用越方便;越底层越具体,表达能力越丰富,使用越灵活
-
支持事件时间(event-time)和处理时间(processing-time)语义
-
精确一次(exactly-once)的状态一致性保证
-
低延迟,每秒处理数百万个事件,毫秒级延迟
-
与众多常用存储系统的连接
-
高可用,动态扩展,实现7*24小时全天候运行
1.4 flink架构
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ziXbfhez-1659267999906)(F:/note/image/flink-arch.png)]](https://img-blog.csdnimg.cn/42f4c25875f647768df05a5bb0551b4c.png)
从下至上:
- 部署层:Flink 支持本地运行、能在独立集群或者在被YARN、kubernetes管理的集群上运行, 也能部署在云上。
- 运行时:Runtime层提供了支持Flink计算的全部核心实现,为上层API层提供基础服务。
- API:DataStream、DataSet、Table、SQL API。
- 扩展库:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
2. flink部署
2.1 Standalone模式
./bin/start-cluster.sh
./flink run -c com.atguigu.wc.StreamWordCount –p 2
2.2 Yarn模式
以 Yarn 模式部署 Flink 任务时,要求Flink 是有Hadoop支持的版本, Hadoop环境需要保证版本在2.2 以上,并且集群中安装有HDFS服务。
Flink 提供了两种在 yarn 上运行的模式,分别为Session-Cluster和Per-Job-Cluster模式
- Session-Cluster
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aWhrEc6X-1659267999906)(F:/note/image/Session-Cluster.png)]](https://img-blog.csdnimg.cn/335dfe8ba6c746d39e34421b646698fe.png)
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向yarn申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager,共享资源;适合规模小执行时间短的作业。
在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
- Per-Job-Cluster
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-my1xNrey-1659267999907)(F:/note/image/Per-Job-Cluster.png)]](https://img-blog.csdnimg.cn/f6aabd3b00364c17805c1aabb585cc65.png)
一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。
每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
2.3 Kubernetes模式
容器化部署时目前业界很流行的一项技术,基于 Docker 镜像运行能够让用户更加方便地对应用进行管理和运维。 容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。
flink k8s方式部署参考 flink-on-k8s-operator
3. flink运行架构
3.1 Flink 运行时的组件
Flink 运行时架构主要包括四个不同的组件,分别是作业管理器(JobManager)、资源管理器(ResourceManager)、任务管理器(TaskManager)以及分发器(Dispatcher),它们会在运行流处理应用程序时协同工作:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OqRL7HUR-1659267999907)(F:/note/image/runtime-component.png)]](https://img-blog.csdnimg.cn/63901b86719a4865a3cc2ac412e9f871.png)
3.1.1 作业管理器(JobManager)
控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个不同的JobManager 所控制执行。
JobManager 会先接收到要执行的应用程序, 这个应用程序会包括:
- 作业图(JobGraph)
- 逻辑数据流图(logical dataflow graph)
- 打包了所有的类、库和其它资源的JAR包
JobManager会把JobGraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(ExecutionGraph),包含了所有可以并发执行的任务。
JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源,也就是任务管理器(TaskManager)上的插槽(slot)。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。而在运行过程中, JobManager会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
3.1.2 任务管理器(TaskManager)
taskmanager是flink中的工作进程,通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
启动之后, TaskManager会向资源管理器注册它的插槽;收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。 JobManager就可以向插槽分配任务(tasks)来执行了。
在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据。
3.1.3 资源管理器(ResourceManager)
主要负责管理TaskManager的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、 Mesos、 K8S,以及standalone部署。当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足 JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
3.1.4 分发器(Dispatcher)
可以跨作业运行,它为应用提交提供了restful接口。当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager。
Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中可能并不是必需的,这取决于应用提交运行的方式。
3.2 任务提交流程
当一个应用提交执行时, Flink 的各个组件是交互协作的过程如下所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xsBwQs9K-1659267999908)(F:/note/image/flink-commit-job.png)]](https://img-blog.csdnimg.cn/ddcebed7a64d42438197537b10ba3401.png)
上图是从一个较为高层级的视角,来看应用中各组件的交互协作。如果部署的集群环境不同(例如 YARN, Mesos, Kubernetes, standalone 等),其中一些步骤可以被省略,或是有些组件会运行在同一个JVM进程中。
具体地 Flink on K8S Session 的提交流程、安装部署如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fGM2gwaz-1659267999908)(F:/note/image/k8s-commit-job.png)]](https://img-blog.csdnimg.cn/ad041017e5414e1c92e379f5c907bbc2.png)
在 K8S 集群上使用 Session 模式提交 Flink 作业的过程会分为 3 个阶段:首先在 K8S 上启动 Flink Session 集群;其次通过 Flink Client 提交作业;最后进行作业调度。具体步骤如下:
- 启动集群
- 准备好Flink 集群的资源描述文件,包含:
flink-configuration-configmap.yaml
jobmanager-service.yaml
jobmanager-rest-service.yaml #可选
jobmanager-deployment.yaml
taskmanager-deployment.yaml
- 创建 Flink Master Deployment、TaskManager Deployment、ConfigMap、SVC 等资源,同时初始化 Dispatcher 和 KubernetesResourceManager,并通过 K8S 服务对外暴露 Flink Master 端口。
- 作业提交
-
Client 用户使用 Flink run 命令,将相应任务提交上来,用户的 Jar 和 JobGrapth 会在 Flink Client 生成,通过 SVC 传给 Dispatcher。
-
Dispatcher 收到 JobGraph后,会为每个作业启动一个JobMaster,将JobGraph 交给JobMaster进行调度。
- 作业调度
-
JobMaster 会向 KubernetesResourceManager 申请资源,请求Slot。
-
KubernetesResourceManager 从 K8S 集群分配 TaskManager,每个 TaskManager 都是一个Pod。
-
K8S 集群分配一个新的 Pod 后,在上面启动 TaskManager。
-
TaskManager 启动后注册到 SlotManager。
-
SlotManager 向 TaskManager 请求 Slot。
-
TaskManager 提供 Slot 给 JobManager,然后任务被分配到 Slot 上运行。
3.3 任务调度
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pGYoRIpD-1659267999908)(F:/note/image/task-scheduling.png)]
客户端不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph)给 Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。
当Flink集群启动后,首先会启动一个JobManger和一个或多个的TaskManager。由 Client 提交任务给 JobManager, JobManager再调度任务到各个TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给JobManager。TaskManager之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client
Client为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后, Client 可以结束进程( Streaming 的任务),也可以不结束并等待结果返回。
- JobManager
主要负责调度Job并协调Task做checkpoint。从Client处接收到Job和JAR包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager
在启动的时候就设置好了槽位数(Slot),每个slot 能启动一个Task,Task为线程。从JobManager处接收需要部署的 Task,部署启动后,与自己的上游建立连接,接收数据并处理。
3.3.1 TaskManger与Slots
Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程上执行一个或多个subtask。为了控制一个worker能接收多少个task, worker通过task slot来进行控制(一个worker至少有一个task slot)
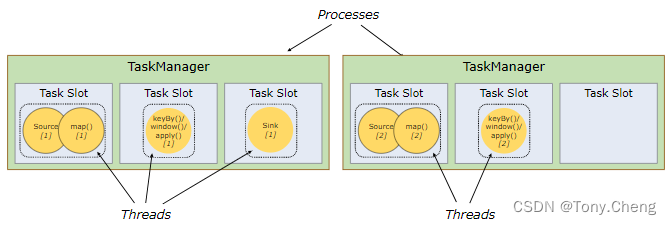
每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个subtask 将不需要跟来自其他job的subtask 竞争内存,因为同一个slot中只能是同一个job不同阶段的subtask。需要注意的是,这里不会涉及到 CPU 的隔离, slot 目前仅仅用来隔离 task 的受管理的内存。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OfKXs1Xa-1659267999909)(F:/note/image/task-share-slot.png)]](https://img-blog.csdnimg.cn/3904c85449f34196915c5dad7c7c8896.png)
默认情况下, Flink 允许子任务共享 slot,即使它们是不同任务的子任务(前提是它们来自同一个 job)。这样的结果是,一个 slot 可以保存作业的整个管道。
3.3.2 Slots与parallelism
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,一个 stream的并行度,可以认为就是其所有算子中最大的并行度
Task Slot 是静态的概念,是指 TaskManager 具有的并发执行能力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置;而并行度 parallelism 是动态概念,即 TaskManager 运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
假设一共有 3 个 TaskManager,每一个 TaskManager 中的分配 3 个TaskSlot,也就是每个 TaskManager 可以接收 3 个 task,一共 9 个 TaskSlot,如果我们设置parallelism.default=1,即运行程序默认的并行度为 1, 9 个 TaskSlot 只用了 1个,有 8 个空闲,因此,设置合适的并行度才能提高效率。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xy54kus1-1659267999909)(F:/note/image/task-slot-parallelism1.png)]](https://img-blog.csdnimg.cn/f5349e14100a428bbf8d21d39f8e1324.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rx8tEXSd-1659267999909)(F:/note/image/task-slot-parallelism2.png)]](https://img-blog.csdnimg.cn/bdd4462cb4894aef8d747d584a15c572.png)
3.3.3 程序与数据流
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k4MyQXvg-1659267999910)(F:/note/image/dataflow.png)]](https://img-blog.csdnimg.cn/0fb30bc370ac4ca4ae556a2b03c4fcec.png)
所有的 Flink 程序都是由三部分组成的:Source 、Transformation和Sink。Source负责读取数据源,Transformation利用各种算子进行处理加工,Sink 负责输出。
在运行时,Flink上运行的程序会被映射成“逻辑数据流”( dataflows),它包含了这三部分。 每一个 dataflow 以一个或多个 sources 开始以一个或多个 sinks 结束。 dataflow 类似于任意的有向无环图(DAG)。在大部分情况下,程序中的转换运算(transformations)跟 dataflow 中的算子(operator) 是一一对应的关系,但有时候,一个 transformation 可能对应多个 operator。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-npfA3Uz7-1659267999910)(F:/note/image/flink-datastream.png)]](https://img-blog.csdnimg.cn/ccb109a876274e75823596a8cbf0b55a.png)
3.3.4 执行图
由 Flink 程序直接映射成的数据流图是 StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink 需要将逻辑流图转换为物理数据流图,详细说明程序的执行方式。
Flink 转换过程中的图可以分成四层: StreamGraph -> JobGraph -> ExecutionGraph ->物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph 。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图: JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I6QugA5y-1659267999911)(F:/note/image/execution-graph.png)]](https://img-blog.csdnimg.cn/41f3e7083f834f74805bdbae562042d0.png)
3.3.5 数据传输形式
在执行过程中,一个流(stream)包含一个或多个分区(stream partition),而每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。
Stream 在算子之间传输数据的形式可以是 one-to-one(forwarding)的模式也可以是redistributing的模式,具体是哪一种形式,取决于算子的种类。
- One-to-one
stream维护着分区以及元素的顺序(比如source和map之间)。这意味着 map 算子的子任务看到的元素的个数以及顺序跟source算子的子任务生产的元素的个数、顺序相同, map、 fliter、 flatMap等算子都是one-to-one的对应关系。
- Redistributing
stream的分区会发生改变。每一个算子的子任务依据所选择的 transformation 发送数据到不同的目标任务。例如, keyBy基于hashCode 重分区,而 broadcast和rebalance会随机重新分区,这些算子都会引起 redistribute 过程。
3.3.5 任务链
Flink采用了一种称为任务链的优化技术,它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
形成任务链的条件有如下两个:
- 相同并行度
- one-to-one操作














 1746
1746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









