









1. Linux Namespace和Cgroups
对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
1.1 PID Namespace
//Linux 系统正常创建线程
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
//添加CLONE_NEWPID参数,创建线程,返回一个新的PID
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
新创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
当然,我们还可以多次执行上面的 clone() 调用,这样就会创建多个 PID Namespace,而每个 Namespace 里的应用进程,都会认为自己是当前容器里的第 1 号进程,它们既看不到宿主机里真正的进程空间,也看不到其他 PID Namespace 里的具体情况。
除了我们刚刚用到的 PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
用户的应用进程实际上就是容器里 PID=1 的进程,也是其他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没办法同时运行两个不同的应用,除非你能事先找到一个公共的 PID=1 的程序来充当两个不同应用的父进程,这也是为什么很多人都会用 systemd 或者 supervisord 这样的软件来代替应用本身作为容器的启动进程。
1.2 Cgroups
Linux Cgroups(Linux Control Group),它最主要的作用,就是限制一个进程能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
$ ls /sys/fs/cgroup/cpu
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares
notify_on_releasecgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us
cpu.stat tasks
比如cfs_period 和 cfs_quota 两个参数组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
Linux Cgroups 就是一个子系统目录加上一组资源限制文件的组合。而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
2. docker image
2.1 rootfs解决的问题
对于通过 clone() 系统调用创建了一个新的子进程 container_main,其文件系统都继承于宿主机的文件系统,怎么才能对其文件系统进行隔离呢?
在 Linux 操作系统里,有一个名为 chroot 的命令可以帮助你在 shell 中方便地完成这个工作。顾名思义,它的作用就是帮你“change root file system”,即改变进程的根目录到你指定的位置。它的用法也非常简单。
而这个挂载在容器根目录上、用来为容器进程提供隔离后执行环境的文件系统,就是所谓的“容器镜像”。它还有一个更为专业的名字,叫作:rootfs(根文件系统)。
一个最常见的 rootfs,或者说容器镜像,会包括如下所示的一些目录和文件,比如 /bin,/etc,/proc 等等:
$ ls /bin dev etc home lib lib64 mnt opt proc root run sbin sys tmp usr var
对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
rootfs 只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。在 Linux 操作系统中,这两部分是分开存放的,操作系统只有在开机启动时才会加载指定版本的内核镜像。
实际上,同一台机器上的所有容器,都共享宿主机操作系统的内核。由于 rootfs 里打包的不只是应用,而是整个操作系统的文件和目录,也就意味着,应用以及它运行所需要的所有依赖,都被封装在了一起。
2.2 image 的layer
docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。这种分层是通过联合文件系统(Union File System)来实现的。
Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下,比如有A、B两个文件
//原结构
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
//联合挂载
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
//联合挂载后
$ tree ./C
./C
├── a
├── b
└── x
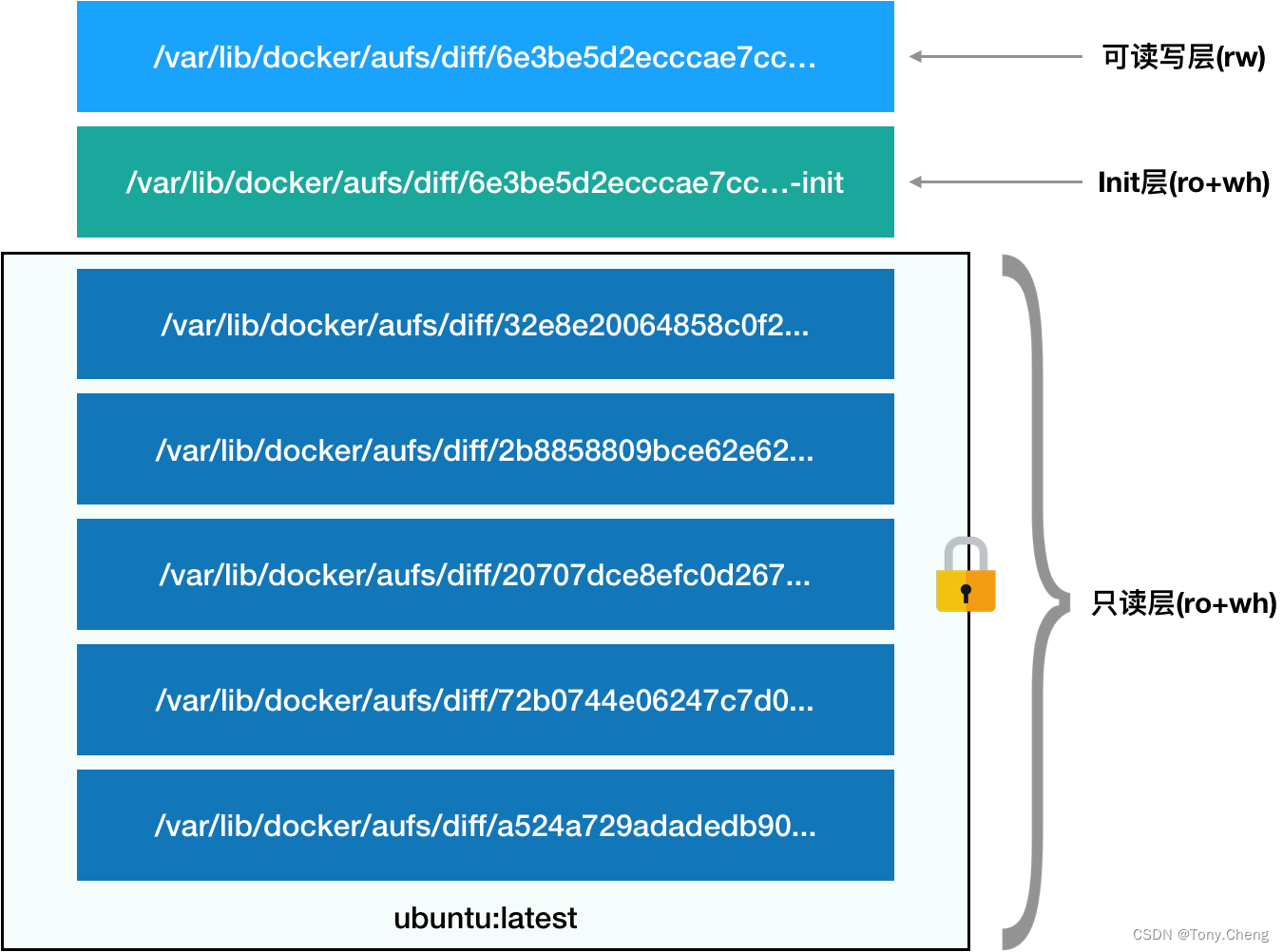
从这个结构可以看出来,这个容器的 rootfs 由如下图所示的三部分组成:
-
只读层
它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout),这些层都是 操 作系统的一部分。
如果删除只读层的文件,AuFS 会在可读写层创建一个 whiteout 文件,在联合挂载时,把只读层里的文件“遮挡”起来。如果要是修改只读层的文件,使用copy-on-write来操作,将该文件复制到可读写层进行修改,修改的结果会作用到下层文件。 -
可读写层
它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。 -
Init 层
一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
需要这样一层的原因是,这些文件本来属于只读的镜像的一部分,但是用户往往需要在启动容器时写入一些指定的值比如 hostname,所以就需要在可读写层对它们进行修改。
可是,这些修改往往只对当前的容器有效,我们并不希望执行 docker commit 时,把这些信息连同可读写层一起提交掉。
所以,Docker 做法是,在修改了这些文件之后,以一个单独的层挂载了出来。而用户执行 docker commit 只会提交可读写层,所以是不包含这些内容的。
2.3 graph driver
Docker的graph driver主要用于管理和维护镜像,包括把镜像从仓库下载下来,到运行时把镜像挂载起来可以被容器访问等,都是graph driver做的。
目前docker支持的graph driver有:
- Overlay2
- Aufs
- Devicemapper
- Btrfs
- Zfs
- Vfs
以上2.2 描述的是aufs的实现,目前我们使用的是overlay2,也是一种ufs技术
3. docker log
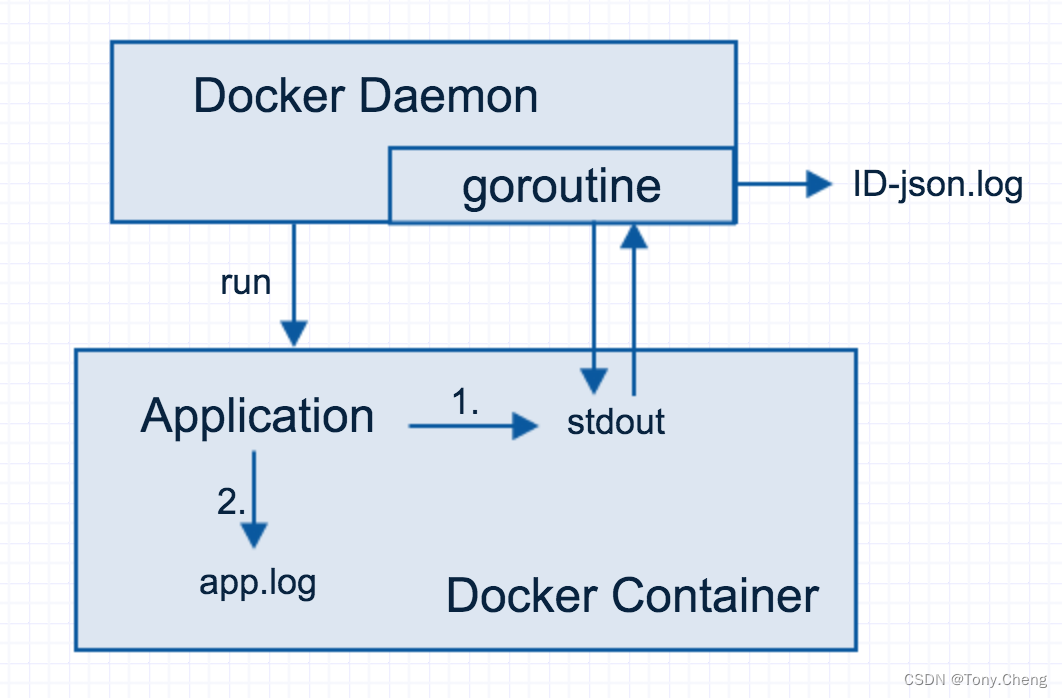
假设 application 是 Docker 容器内部运行的应用,那么对于应用的第一部分标准输出(stdout)日志,Docker Daemon 在运行这个容器时就会创建一个协程(goroutine),负责标准输出日志。
由于此 goroutine 绑定了整个容器内所有进程的标准输出文件描述符,因此容器内应用的所有标准输出日志,都会被 goroutine 接收。goroutine 接收到容器的标准输出内容时,立即将这部分内容,写入与此容器一一对应的日志文件中,日志文件位于 /var/lib/docker/containers/<container_id> ,文件名为 <container_id>-json.log 。
至此,关于容器内应用的所有标准输出日志信息,已经全部被 Docker Daemon 接管,并重定向到与容器一一对应的日志文件中。

















 141
141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









