









pom文件中添加
<!-- Ansj中文分词-->
<dependency>
<groupId>org.ansj</groupId>
<artifactId>ansj_seg</artifactId>
<version>5.1.6</version>
</dependency>我定义的dict文件内容
推特 n 57969
中华 n 57969
周杰伦 n 57969
时光机 n 57969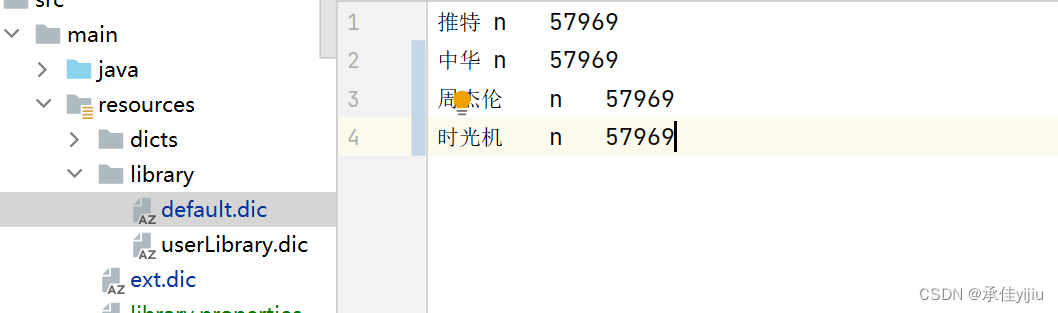
实现
方式1
通过Library加载自定义字典文件,分词的时候将forset对象传入
@Test
public void contextLoadsAnalysis() throws Exception {
Forest forest = null;
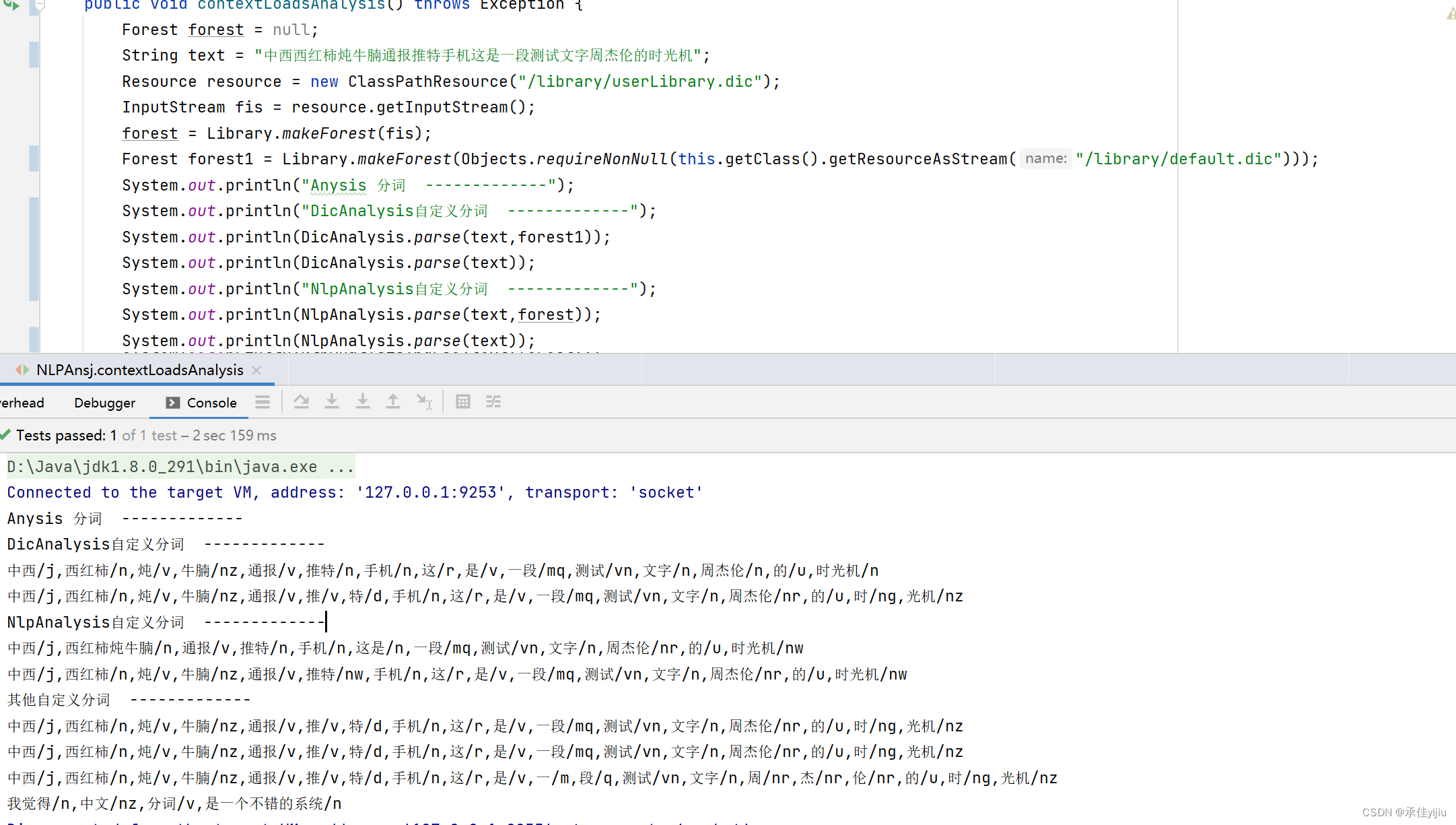
String text = "中西西红柿炖牛腩通报推特手机这是一段测试文字周杰伦的时光机";
Resource resource = new ClassPathResource("/library/userLibrary.dic");
InputStream fis = resource.getInputStream();
forest = Library.makeForest(fis);
Forest forest1 = Library.makeForest(Objects.requireNonNull(this.getClass().getResourceAsStream("/library/default.dic")));
System.out.println("Anysis 分词 -------------");
System.out.println("DicAnalysis自定义分词 -------------");
System.out.println(DicAnalysis.parse(text,forest1));
System.out.println(DicAnalysis.parse(text));
System.out.println("NlpAnalysis自定义分词 -------------");
System.out.println(NlpAnalysis.parse(text,forest));
System.out.println(NlpAnalysis.parse(text));
System.out.println("其他自定义分词 -------------");
System.out.println(ToAnalysis.parse(text));
System.out.println(IndexAnalysis.parse(text));
System.out.println(BaseAnalysis.parse(text));
}结果如下:
可能出现的问题:
词典添加的词不生效:编辑的tab其实不是\t,我试了半天就是因为在idea中手动tab结果不是真正的\t,后面直接复制了作者文档里的数据(PS:用户自定义词典这里面有例子数据)改了改数据就成功了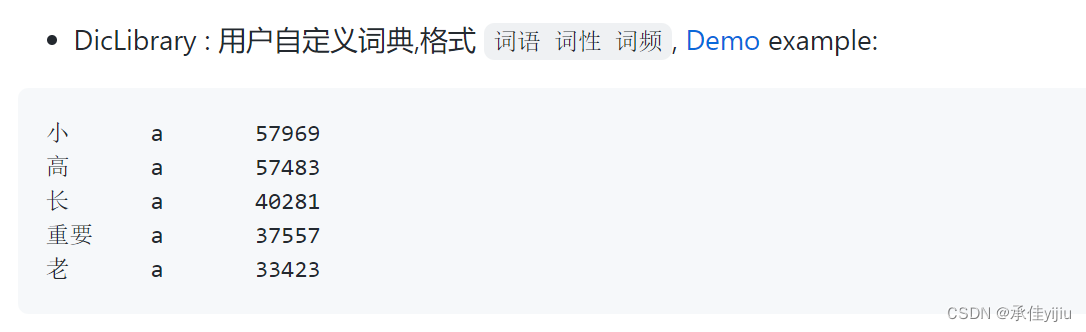
方式2
使用作者说的动态添加词典直接加载词。但是如果数据量大一个个加,肯定很麻烦。
//动态添加
String str ="我觉得中文分词是一个不错的系统";
DicLibrary.insert(DicLibrary.DEFAULT, "我觉得", "n", 1000);
DicLibrary.insert(DicLibrary.DEFAULT, "是一个不错的系统", "n", 1000);
Result terms2 = DicAnalysis.parse(str);
System.out.println(terms2);删除词就只要使用DicLibrary.delete(DicLibrary.DEFAULT, "我是词");
注意!!!
如果是DicLibrary.insert(DicLibrary.DEFAULT, "增加新词", "我是词性", 1000);这样添加词典,使用ToAnalysis 、DicAnalysis 、NlpAnalysis 、IndexAnalysis 都会被影响,使用添加的词分词。比如输入【名称性别电话】一般会拆开成【名称】、【性别】和【电话】,这个时候通过DicLibrary.insert(DicLibrary.DEFAULT, "名称性别", "n", 1000);加入词典,那么除了使用BaseAnalysis之外的所有分词发方式输出的结果都是【名称性别】、【电话】
这是ansj文档里面功能统计:
| 名称 | 用户自定义词典 | 数字识别 | 人名识别 | 机构名识别 | 新词发现 |
|---|---|---|---|---|---|
| BaseAnalysis | X | X | X | X | X |
| ToAnalysis | √ | √ | √ | X | X |
| DicAnalysis | √ | √ | √ | X | X |
| IndexAnalysis | √ | √ | √ | X | X |
| NlpAnalysis | √ | √ | √ | √ | √ |
方式2.2
所以为了不影响其他分词方式的使用,最好使用自定义的key,想要使用这个词典的时候直接DicAnalysis.parse("xx",DicLibrary.gets(key));、ToAnalysis.parse("xx",DicLibrary.gets(key));等等都可以,再次使用分词DicAnalysis.parse("xx")也不会这个自定义的词典被影响。
/**
* 自定义key
*/
@Test
public void keyTest(){
String key = "dic_mykey" ;
DicLibrary.put(key, key, new Forest());
DicLibrary.insert(key, "增加新词", "我是词性", 1000);
Result parse = DicAnalysis.parse("这是用户自定义词典增加新词的例子",DicLibrary.gets(key));
System.out.println(parse);
boolean flag = false;
for (Term term : parse) {
flag = flag || "增加新词".equals(term.getName());
}
Assert.assertTrue(flag);
}方式3(我试了不起作用,用方式1保险)
根据网上的方法和作者的操作文档用户自定义词典试了蛮多回,在项目根路径下创建library.properties 并添加
#path of userLibrary this is default library
dic=library/default.dic试了半天,但并未起作用,迷惑。
看了下别人出现的问题,只找到了一个已经关闭的issues里面的回答















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









