







一、预训练语言模型体系初印象
1.预训练模型体系
随着预训练模型被提出,自然语言处理领域有了突飞猛进的发展,通过在大规模文本中训练通用的语言表示,并用微调的方式进行下游任务的领域适应,绝大多数的自然语言处理任务都可以使用这种范式取得良好的效果。根据不同的分类方法可以将目前的预训练模型发展和体系如下图所示:


2.Huggingface Transformers
HuggingFace 是一家专注于自然语言处理(NLP)、人工智能和分布式系统的创业公司,创立于2016年。最早是主营业务是做闲聊机器人,2018年 Bert (google tensorflow版本)发布之后,他们贡献了基于pytorch版本的BERT预训练模型,即 pytorch-pretrained-bert。随着影响力的不断拓展,他们逐渐开源了Huggingface Transformers库,并在社区内大受欢迎!Huggingface社区
2.1 Huggingface Transformers生态
Transformers 是Huggingface基于Transformer模型结构提供的预训练语言开源库:
- 它包含自然语言理解(NLU)和自然语言生成(NLG)两大任务,提供了最先进的通用框架,其中有超过32个预训练模型(细分为100多种语言的版本)
- 它支持 Pytorch,Tensorflow2.0,并且支持两个框架的相互转换。框架支持了最新的各种NLP预训练语言模型,使用者可以很快速的进行模型的调用,并且支持模型further pretraining 和下游任务fine-tuning。
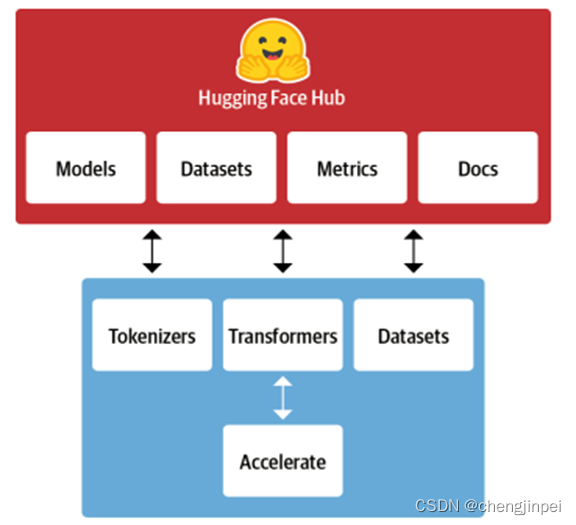
Huggingface Transformers生态主要包含两个部分: - Library:主要包含代码部分、包括分词、模型框架、加载数据、加速文档的一些源码(上图蓝色部分所示)
- Hub:主要包含预训练模型的权重(model)、数据集(data)、评估脚本(metrics)以及一些使用文档(上图红色部分所示)
Models:56000多个预训练模型,BERT、GPT等,甚至还有图像预训练模型。
Datasets:6900多个数据集,文本分类、问答语料等都有,遗憾的是中文的数据集很少
2.2 Transformers快速入门
1.快速安装
pip install transformers
2.加载预训练模型
Transfomers有三种模型的应用方式,每一个模型有唯一的短名,如果同时有配套的分词工具(Tokenizer),需要使用同名调度

- 管道(Pipline)方式:高度集成的使用方式,几行代码就可以实现一个NLP任务
- 自动模型(AutoModel)方式:自动载入并使用BERT等模型
- 具体模型方式:在使用时需要明确具体的模型,并按照特定参数进行调试
在上述三种应用方式中,管道方式使用最简单,但灵活度最差;具体模型方式使用复杂,但是灵活度最高(具体的实现细节在后续章节实现)
上述三种不论哪一种方式,有分为网络全局加载和本地指定路径加载
- 网络全局加载:指的是不需要指定路径,只根据名称下载到默认缓存路径中
# 此时使用的是自动模型模型,网络下载模型到缓存中
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('bert-base-chinese')
- 指定路径下载:将模型从网络上下载到自己路径,在加载时提前指定路径
首先使用git下载到本地指定路径,或者直接登录网站直接下载到本地
#lfs的作用是下载大文件使用的
git lfs install
git clone https://huggingface.co/bert-base-chinese
使用网页下载模型:网页链接
#此时使用的是具体模型的方式加载模型
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('./bert-base-chinese')
model = BertModel.from_pretrained('./bert-base-chinese')
#此时使用的是管道方式调用模型
from transformers import *
#nlp_sentence_classif = pipeline("sentiment-analysis") #网络下载模式
tokenizer = DistilBertTokenizer.from_pretrained(r"./distilbert-base-cased")
nlp_sentence_classif = pipeline("sentiment-analysis",model=r"./distilbert-base-cased",config=r"./distilbert-base-cased",tokenizer=tokenizer) #本地模式
print(nlp_sentence_classif("你好"))
2.3 基于Transformer的预训练语言模型
Transformer网络模型结构如下图所示,相比CNN和RNN网络,transformer网络具有更好的特征提取能力以及并行化计算的能力,Transformer包含Encode 和 Decode部分,其中Encoders负责接收源端输入语句,提取特征并输出语义特征向量;Decoders负责根据语义特征向量,逐字生成目标语言的译文
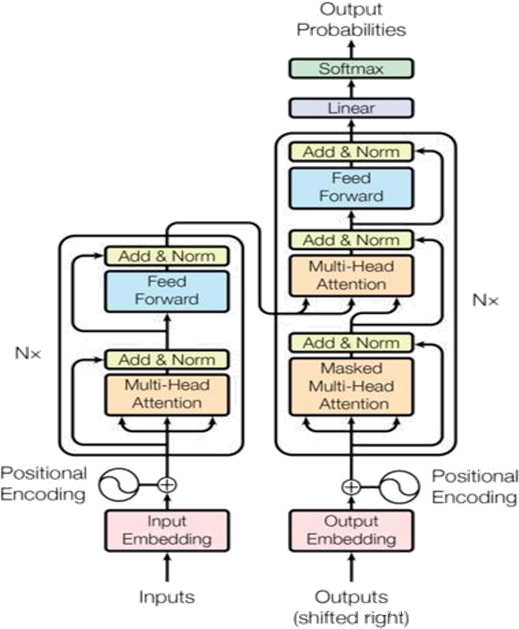
Transformer模型的每个部分都可以单独使用,主要依据不同的任务来定:
-
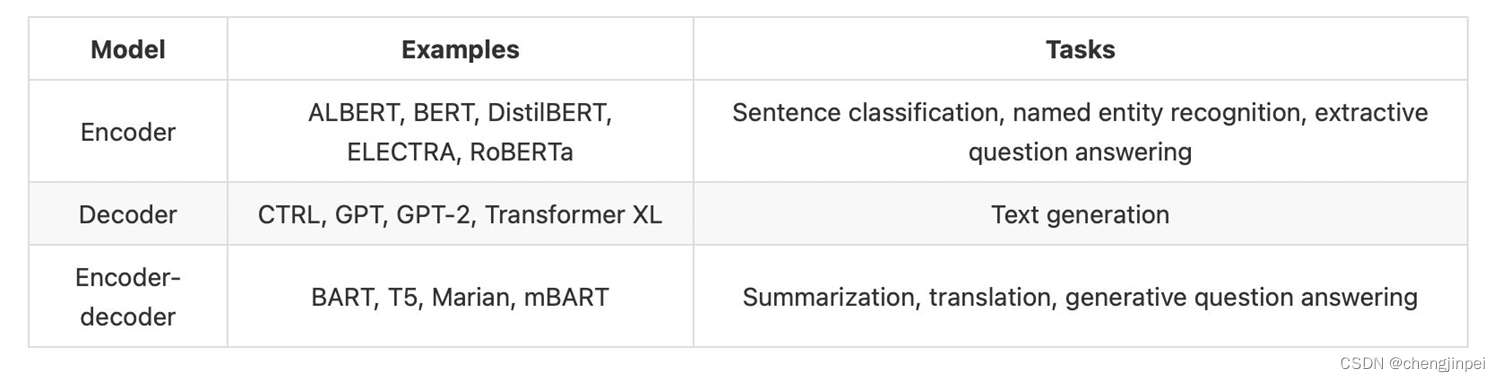
Encoder-only-model:主要用于理解输入,例如文本分类,命名实体识别,相似度任务,阅读理解任务等
-
Decoder-only-model:主要用于文本生成任务,无须输入
-
Encoder-decoder models or sequence-to-sequence models:主要用于基于特定输入条件的文本生成任务,例如翻译,或者文本摘要任务
二、基于Transformers库的预训练语言模型实战
1.Transformers库应用的基本流程

-
数据加载和预处理
-
分词操作
-
Transformer模型训练和推理
-
模型效果评估
除去Datasets以及评估部分外(部分数据为用户集体提供),Transformers库中主要包含如下三个部分:
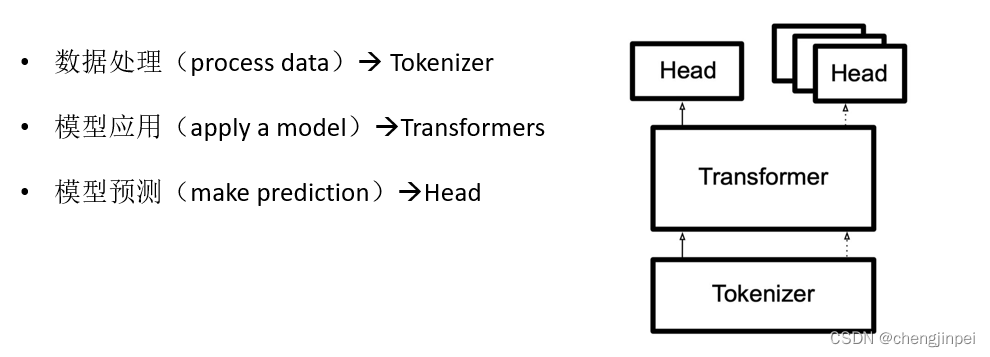
2.Transformers库应用模块
2.1 Tokenizer分词器模块
在Transformers库中,提供了一个通用的词表工具Tokenizer,该工具是用Rust编写的,可以实现NLP任务中的数据预处理环节的相关任务。
- 主要作用:将输入进行分词,并转换成Embedding的形式,Tokenizer类不仅可以对输入进行分词而且可以解码(decode)
- 获取方式:支持直接手动配置 或者从预训练模型中加载
在词表工具Tokenizer中,主要通过PreTrainedTokenizer类实现对外接口的使用,该工具同时提供了多种不同的组件:

接下来按照分词模块的集中不同应用模式进行实战:
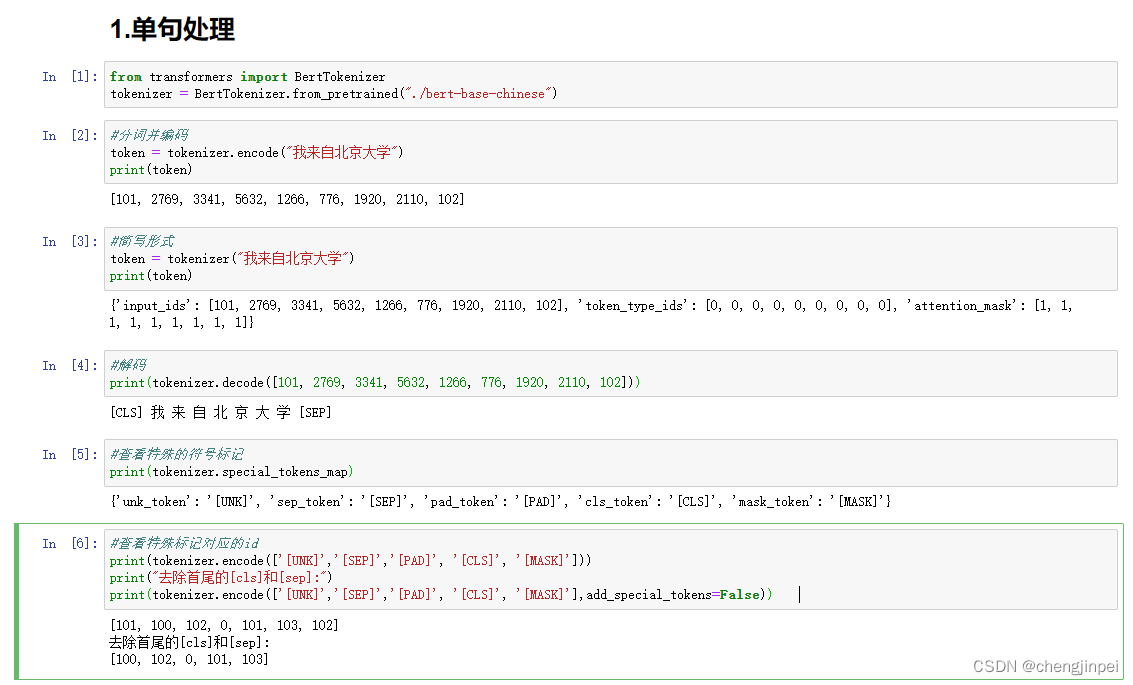
1.单句处理:对单个句子进行处理
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("./bert-base-chinese")
#分词并编码
token = tokenizer.encode("我来自北京大学")
print(token)
#简写形式
token = tokenizer("我来自北京大学")
print(token)
#解码
print(tokenizer.decode([101, 2769, 3341, 5632, 1266, 776, 1920, 2110, 102]))
#查看特殊的符号标记
print(tokenizer.special_tokens_map)
#查看特殊标记对应的id
print(tokenizer.encode(['[UNK]','[SEP]','[PAD]', '[CLS]', '[MASK]']))
print("去除首尾的[cls]和[sep]:")
print(tokenizer.encode(['[UNK]','[SEP]','[PAD]', '[CLS]', '[MASK]'],add_special_tokens=False))
结果:
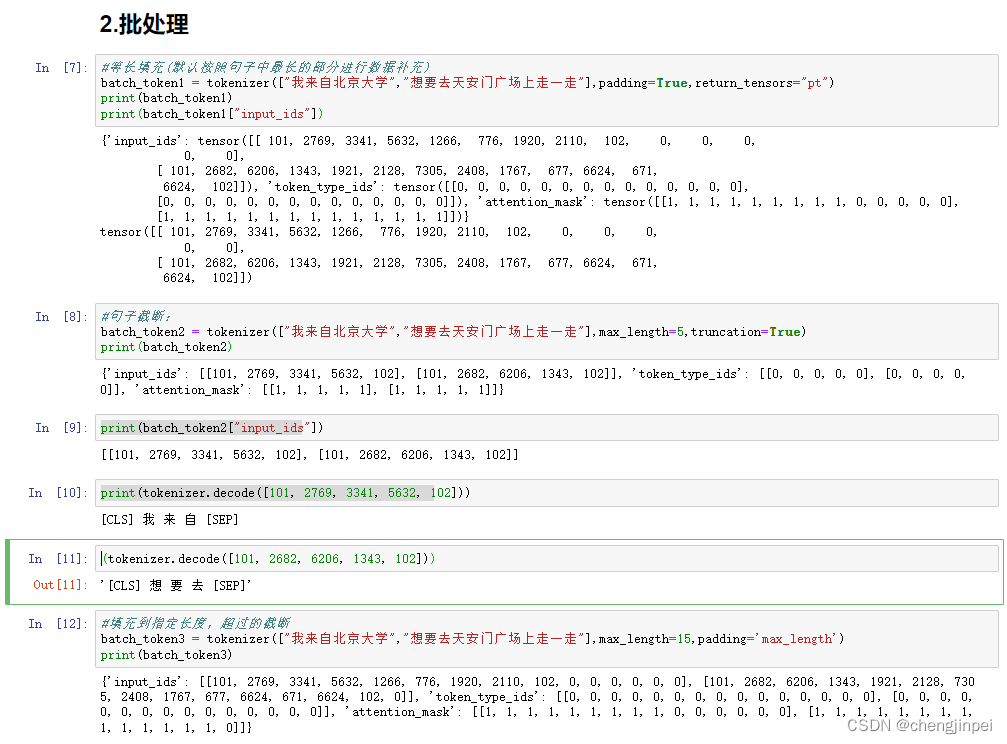
2.批处理:对多个数据进行批次处理
#等长填充(默认按照句子中最长的部分进行数据补充)
batch_token1 = tokenizer(["我来自北京大学","想要去天安门广场上走一走"],padding=True,return_tensors="pt")
print(batch_token1)
print(batch_token1["input_ids"])
#句子截断:
batch_token2 = tokenizer(["我来自北京大学","想要去天安门广场上走一走"],max_length=5,truncation=True)
print(batch_token2)
print(batch_token2["input_ids"])
print(tokenizer.decode([101, 2769, 3341, 5632, 102]))
(tokenizer.decode([101, 2682, 6206, 1343, 102]))
#填充到指定长度,超过的截断
batch_token3 = tokenizer(["我来自北京大学","想要去天安门广场上走一走"],max_length=15,padding='max_length')
print(batch_token3)
结果:
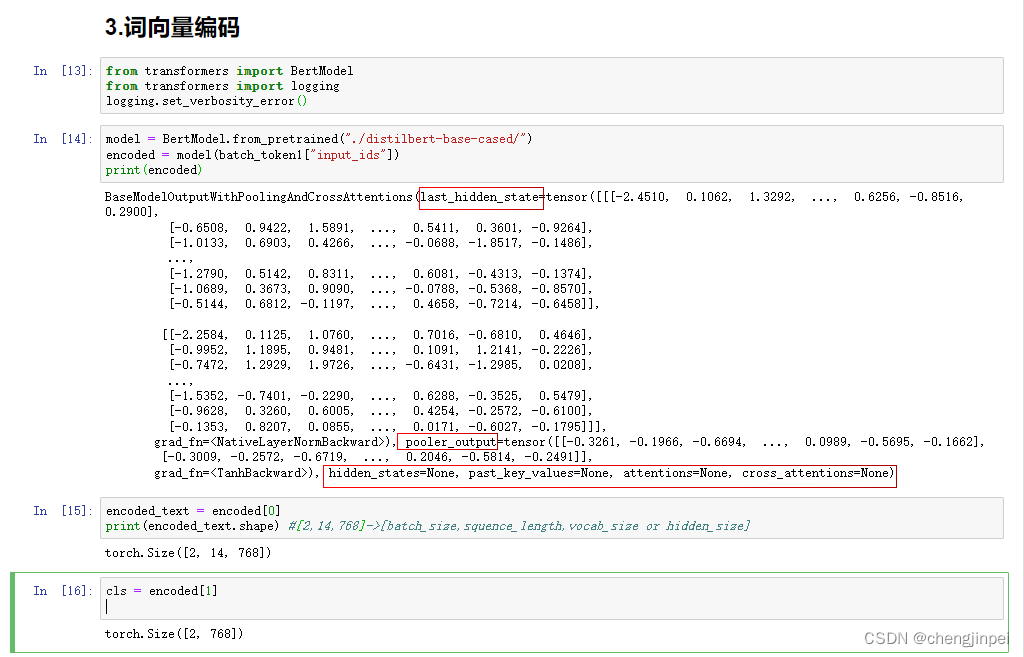
3.BERT词向量编码
from transformers import BertModel
from transformers import logging
logging.set_verbosity_error()
model = BertModel.from_pretrained("./distilbert-base-cased/")
#获取所有BERT编码词向量表示
encoded = model(batch_token1["input_ids"])
print(encoded)
#获取最后一层词向量表示last_hidden_state
encoded_text = encoded[0]
print(encoded_text.shape) #[2,14,768]->[batch_size,squence_length,vocab_size or hidden_size]
#获取最后一层[cls]词向量
cls = encoded[1]
print(cls.shape)
结果:
接下来将以BERT模型原理为基础,加深对Transformers库的了解
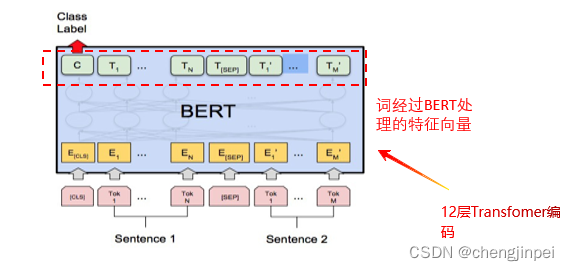
BERT的输入表示:
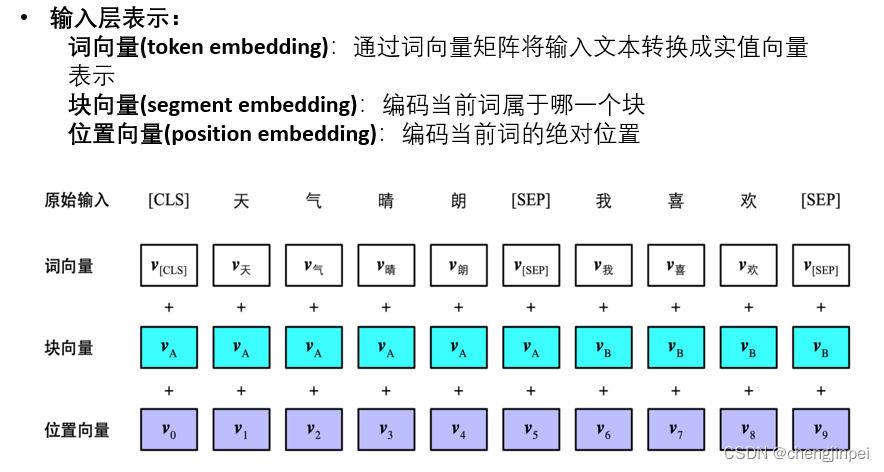
有上述两个图可知:
- BERT的输入input向量包含三个:token embedding + segment embedding + position embedding
from transformers import BertModel
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("./bert-base-chinese")
#BERT输入表示
batch_token1 = tokenizer(["我来自北京大学"],return_tensors="pt")
print(batch_token1)
print(batch_token1["input_ids"])
#获取BERT的隐层编码,假设输入层为H0,则BERT一共包含12个隐层编码器,第一个为h1,第二个为h2
model = BertModel.from_pretrained("./bert-base-chinese/",output_hidden_states = True)
last_hidden_state, pooler_output, hidden_states = model(batch_token1["input_ids"],attention_mask = batch_token1["attention_mask"], return_dict = False)
print(last_hidden_state.shape) #打印最后一层编码(encode 12)
print(pooler_output.shape) #代表最后编码层[cls]的词向量
print(len(hidden_states)) #代表所有隐藏层编码器的表示
结果:
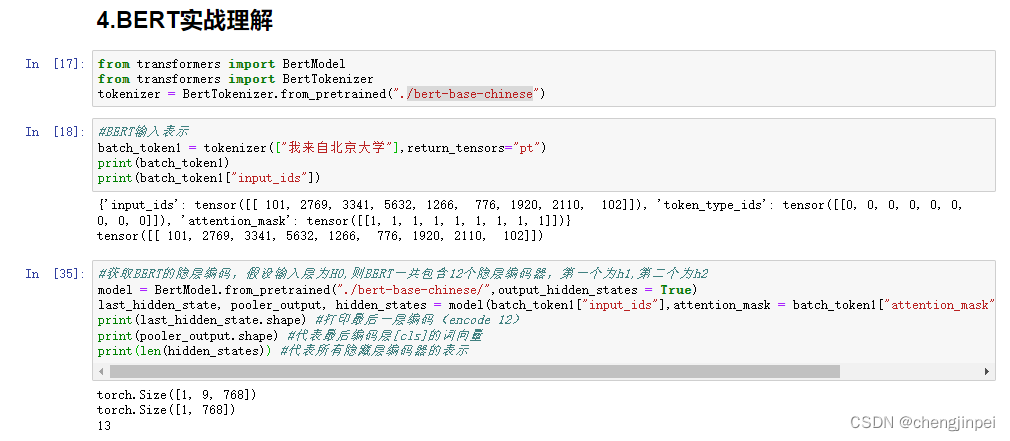
- last_hidden_state包含所有标记的嵌入表示,但是仅来自最后一个编码器层(encoder 12)
- pooler_output代表从最后的编码器层得到的[CLS]标记对应的嵌入表示,可以根据词向量进一步做分类
- hidden_states包含从所有编码器层得到的所有标记的嵌入表示,加上原始输入共13层
参考文献
[1] https://blog.csdn.net/yjw123456/article/details/120232707
[2] http://www.ichenhua.cn/read/433
[3] natural language processing with transformers















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









