






1.文件读写
#使用with的方式可以不用f.close(),推荐本方法(文档类型必须是ASCII)
with open('c:/forpython/b.txt','r') as f:
print f.read() #一次获取b.txt文档的全部内容,记得在前面加print
#f.read(10) 获取10个字节内容
#f.readline() 获取一行内容
#f.readlines() 获取全部内容并按行返回list
# for line in f.readlines():
# print(line.strip()) #line是字符串,.strip()默认删除空白符(包括'\n','\r','t','')
#如果遇到不是ASCII编码类型的文件,下面会自动转化成unicode
import codecs
with codecs.open('c:/forpython/gbk.txt','r','gbk') as f:
f.read()
#写入数据,写入编码类型不同的文件,参考上面codecs雷同
with open('c:/forpython/c.txt','w') as f:
f.write('i am the god')像open()函数返回的这种有个read()方法的对象,在Python中统称为file-like Object
2.操作文件和目录
import os
print os.name #返回nt表示windows,windows中os没有函数uname()这个获取系统更详细信息
print os.environ #获取系统的所有环境变量
print os.getenv('PATH') #获取某个环境变量的值
print os.path.abspath('.') #查看当前目录的绝对路径
# 创建目录,首先把新目录的完整路径表示出来,因为windows的分隔符是\而不是/
print os.path.join('c:\\forpython','testdir') #返回c:\forpython\testdir
# os.mkdir('c:\\forpython\\testdir') #创建一个新目录,如果显示windows error[183],说明该目录已存在
# os.rmdir('c:\\forpython\\testdir') #删除一个空目录
print os.path.split('c:\\forpython\\b.txt') #分离文件,返回一个typle('c:\forpython','b.txt')
print os.path.splitext('c:\\forpython\\b.txt') #分离后缀,返回一个typle('c:\forpython\b','.txt'),路径文件不存在不影响本操作
print [x for x in os.listdir('.') if os.path.isfile(x)]
# os.listdir()表示列出文件和文件夹名称的列表,括号中的'.'表示当前路径。
# os.path.isfile()判断是否为文件,isdir判断是否为目录,x是那些文件名
print [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1] == '.py']
# [1]表示获取分离后的tuple的第二个元素,第一个是[0]3.序列化
pickle模块(有涉及文档读与写)
try:
import cPickle as pickle
except ImportError:
import pickle
d = dict(name='King',age=18,score=100) #创字典
with open('dump.txt','wb') as f:#字典序列化成str保存在dump.txt中
pickle.dump(d,f)
with open('dump.txt','rb') as f:#从.txt提取str并反序列化成字典赋给d
d = pickle.load(f)
print djson模块(推荐)
import json#竟是将dict等变成json格式,数据具有跨平台优势
class Student(object):#创造一个类
def __init__(self,name,age,score):
self.name=name
self.age=age
self.score=score
s = Student('King',18,88)#创建一个实例s
d1 = json.dumps(s,default=lambda obj:obj.__dict__)#将实例S序列化成json
def dict2student(d):#创建json反序列化成一个实例的对照关系
return Student(d['name'],d['age'],d['score'])
d2 = json.loads(d1,object_hook=dict2student)#注意:序列化和反序列化的方法名不同.
print d2.__dict__ #查看是否反序列成功4.进程
Process 添加单进程方法
from multiprocessing import Process
import os
def run_proc(name): #子进程要运行的函数
print 'Run child process %s (%s)...' % (name,os.getpid())
if __name__ == '__main__':
print 'Parent process %s.' %os.getpid() #先查看当前进程
p = Process(target=run_proc,args=('test',)) #产生子进程Process实例P
print 'Process will start'
p.start() #启动子进程
p.join() #允许子进程结束后继续往下执行,比如打印process end
print 'Process end.'
Pool 添加一堆进程方法.
from multiprocessing import Pool
import os,time,random
def long_time_task(name):
print 'Run task %s(%s)...' % (name,os.getpid())
start = time.time() #获取实时时间
time.sleep(random.random()*3) #等待时间(随机*3秒)
end = time.time() #获取实时时间
print 'Task %s runs %0.2f seconds.' % (name,(end - start))#打印子进程名及其持续时间
if __name__ == '__main__':
print 'Parent process %s.' % os.getpid()#查看当前进程,也就是父进程
p = Pool() #创建进程池实例p,Pool默认是4,表示4核.
for i in range(5):
p.apply_async(long_time_task,args=(i,))#
print 'Waitting for all subprocesses done...'
p.close() #关闭进程池,这和Process不一样,Process是p.start()
p.join()
print 'All subprocesses done.'进程间通信queue,实时写和读
from multiprocessing import Process,Queue
import os,time,random
def write(q):
for value in ['A','B','C','D','e','f','g']:
print 'Put %s to queue...' % value
q.put(value) #往queue中放入数据
time.sleep(random.random())
def read(q):
while True:
value=q.get(True)
print('Get %s from queue') % value
if __name__ == '__main__':
q = Queue() #先创建一个队列
pw = Process(target=write,args=(q,))
pr = Process(target=read,args=(q,))
pw.start()
pr.start()
pw.join()
pr.terminate()#读的进程是死循环,智能强制停止5.线程
import time,threading
def loop():
print 'thread %s is running...' % threading.current_thread().name
n = 0
while n <5:
n = n +1
print 'thread %s >>> %s' % (threading.current_thread().name,n)
time.sleep(1)
print 'thread %s is end...' % threading.current_thread().name
if __name__ == '__main__':
print 'thread %s is running' % threading.current_thread().name
t=threading.Thread(target=loop,name='LoopThread') #创建线程实例
t.start()#线程开始
t.join()#线程结束继续后续代码
print 'thread %s is ended' % threading.current_thread().name进程和线程不同点:线程使用共同变量
添加线程锁threading.Lock()
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
lock = threading.Lock() #全局变量了
def run_thread(n):
for i in range(100000):
lock.acquire()
try:
change_it(n)
finally:
lock.release()
if __name__ == '__main__':
print balance
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print balance线程之间有GIL锁,再多的线程同时只能运行1个,但每个进程都有一个GIL锁,可以通过多进程执行多任务。
# local说白了就是在本线程中保存了根据自己线程名独有的属性(args)
import threading
local_school = threading.local()
def process_student():#没有local的话,这里得传入一个变量
print 'Hello,%s(in %s)\n' % (local_school.student,threading.current_thread().name)
def process_thread(name):
local_school.student = name
process_student() #没有local的话,这里得传入一个变量
t1 = threading.Thread(target= process_thread, args=('a1',), name='Thread-1')
t2 = threading.Thread(target= process_thread, args=('a2',), name='Thread-2')
t1.start()
t2.start()
t1.join()
t2.join()
6.分布式进程
发布任务的机器
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import random,time,Queue,os
from multiprocessing.managers import BaseManager
# 创建两个gueue,一个是发送任务,一个接受结果
# 曾今在进程间通信使用过multiprocessing的queue(队列),是支持多进程使用一个queue的。这里是直接使用Queue模块中的queue,是每个进程都会创建一个queue
task_queue=Queue.Queue()
result_queue=Queue.Queue()
# 创建一个Queue管理器,继承Base管理器(就是为了获取它的属性和方法嘛)
class QueueManager(BaseManager):
pass
#为解决__main__.<lambda> ont found问题
def TaskQueue():
return task_queue
def ResultQueue():
return result_queue
# 必须使用__name__='__main__',原因不详,所以在这里声明函数
def distributed_task():
#教程解释是把两个queue注册到网络上
#我的理解就是在QueueManager对象中创建了一个名为‘get_task_queue’方法,然后改方法的内容就是返回一个task_queue
#使用lambda就是模拟一个无参数无名字的函数,因为callable后必须接函数而不是参数。
# QueueManager.register('get_task_queue',callable=lambda:task_queue)
# QueueManager.register('get_result_queue',callable=lambda:result_queue)
#但在windows下,callable=lambda:~是不可行的.所以需要直接定义函数,再callable
QueueManager.register('get_task_queue',callable=TaskQueue)
QueueManager.register('get_result_queue',callable=ResultQueue)
#我觉得这步才是把QueueManager类实例化(意思是把两个queue注册到网上【服务器】),address=('IP地址',端口号),authkey是验证码
manager= QueueManager(address=('10.9.30.46',5000),authkey='abc') #这一步开始创建了一个新进程
#启动Queue
manager.start()
# 官方解释:获取通过网络访问的Queue对象
#我的理解:创建一个变量,指向实例manager的get_task_queue()方法
task = manager.get_task_queue()
result = manager.get_result_queue()
#发送任务
for i in range(10):#循环10次
n = random.randint(0,10000) #随机从0~10000中抽一个数赋值给N
print ('Put task %d ...' % n)
task.put(n) #放入task的queue中
#接收结果
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result:%s' % r)
#关闭Queue
manager.shutdown()
if __name__ == '__main__':
distributed_task()接收工作的机器
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import Queue,time
from multiprocessing.managers import BaseManager
# 同样创建一个同名Queuemanager类
class QueueManager(BaseManager):
pass
def discributed_work():
#官方解释:由于这个QueueManager只从网络获取Queue,所以注册时只提供名字
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue')
#连接到服务器,QueueManager那台机子的地址(这部分多余的,方便查看)
server_addr='10.9.30.46'
print ('Connect to server %s ...' % server_addr)
worker = QueueManager(address=(server_addr,5000),authkey='abc') #这一步开始创建了一个新进程
worker.connect()#taskmanager那边是.start()
task = worker.get_task_queue()
result = worker.get_result_queue()
# 接收任务
for i in range(10):
try:
n = task.get(timeout=1)
print ('run task %d * %d...' % (n,n))
r = '%d * %d = %d' % (n,n,n*n)
time.sleep(1)
#发送结果
result.put(r)
except Queue.Empty:
print('task queue is empty.')
#处理结果
print ('worker exit.')
if __name__ == '__main__':
discributed_work()
7.正则表达式(字符串是否匹配)
import re
#制定匹配规则
# ^/d表示必须以数字开头
# /d{3}此处有3个数字
# \d{3,8}此处有3到8个数字
# \d$表示以数字结尾
# ()表示分组
a= re.compile(r'(^\d{3})-(\d{3,8}$)')
# 匹配的话返回一个match对象
#.groups()返回分组的部分,groups(1)表示第一部分020,proups(0)表示自己本身
print a.match('020-81382911').groups()
#不匹配返回None
print a.match('a03-78375003')
#切分字符串(去掉包括单个或连续多个的空格,逗号,分号)并生成list
print re.split(r'[\s\,\;]+','a,b;; c d')
#\s表示空格(包括tab的)
# \d+? 问号能取消贪婪匹配.比如我们要(0*)$结尾,但(\d+)会包括那个0,取组时,(0*)只能匹配到''了.作业:匹配邮箱
import re
a = re.compile(r'(^\w+)(\.*)(\w*)@(\w+)\.\w{3}$')
#返回一个types
print a.match('someone@gmail.com').groups()
# 返回gates
print a.match('bill.gates@microsoft.com').group(3)8.python内置模块:collections
namedtuple
[tuple的元素赋名]
#对tuple的元素位进行标识,比如让tuple第一位标为x,可直接p.x获取值,以前只能是tuple[0]
from collections import namedtuple
Point = namedtuple('Point',['x','y'])
p = Point(1,2)
print p.x #返回1
print p.y #返回2
print isinstance(p,tuple) #返回True
deque
[双头列表]
#支持.append(),appendleft(),pop(),popleft()
from collections import deque
q = deque(['a','b','c'])
q.append('x')
q.appendleft('y')
print q
#返回 deque(['y','a','b','c','x'])
defaultdict
[默认值字典]
from collections import defaultdict
dd = defaultdict(lambda:'N/A') #如果没有该KEY,返回N/A
dd['key1'] = 'abc'
print dd['key1'] #key1存在
print dd['key2'] #key2不存在
#除了在Key不存在时返回默认值,defaultdict的其他行为跟dict是完全一样的。OrderedDict
[FIFO先进先出案例]
from collections import OrderedDict
class LastUpdatedOrderedDict(OrderedDict):
def __init__(self, capacity):
super(LastUpdatedOrderedDict, self).__init__()
self._capacity = capacity #设置容量
def __setitem__(self, key, value):
containsKey = 1 if key in self else 0
# print len(self)
if len(self) - containsKey >= self._capacity: #key重复,就不执行.不重复,就删除最早那个
last = self.popitem(last=False) #last=False表示先进先出,如果等于True表示先进后后后后出
print 'remove:', last
if containsKey:
del self[key]
print 'set:', (key, value)
else:
print 'add:', (key, value)
OrderedDict.__setitem__(self, key, value) #每次放进去的key永远在最后一位
if __name__ == '__main__':
d = LastUpdatedOrderedDict(5)
d['a'] =1
d['b'] = 2
d['c'] = 3
d['d'] = 4
d['e'] = 5
d['f'] =6 #此步骤会remove(‘a’,1),add(‘f’,7)
d['c'] = 7#此步骤会删除('c',3),set(‘c’,7)
print d #返回LastUpdatedOrderedDict([('b',2),('d',4),('e',5),('f',6),('c',7)])
Counter
[计算字符串中每字符出现的个数案例]
from collections import Counter
c = Counter()
for ch in 'programming':
# print '%s:%d'% (ch,c[ch]) #自己写的辅助学习代码
c[ch] = c[ch] + 1
print c9.base64
作用:压缩代码
import base64
#编码
# base64.b64encode()
# 解决:由于=字符也可能出现在Base64编码中,但=用在URL、Cookie里面会造成歧义,
# 所以,很多Base64编码后会把=去掉:去掉后怎么解码?
def b64_my(str):
return base64.urlsafe_b64decode(str+'='*(4-len(str)%4))
print b64_my('YWJjZA')10.struct
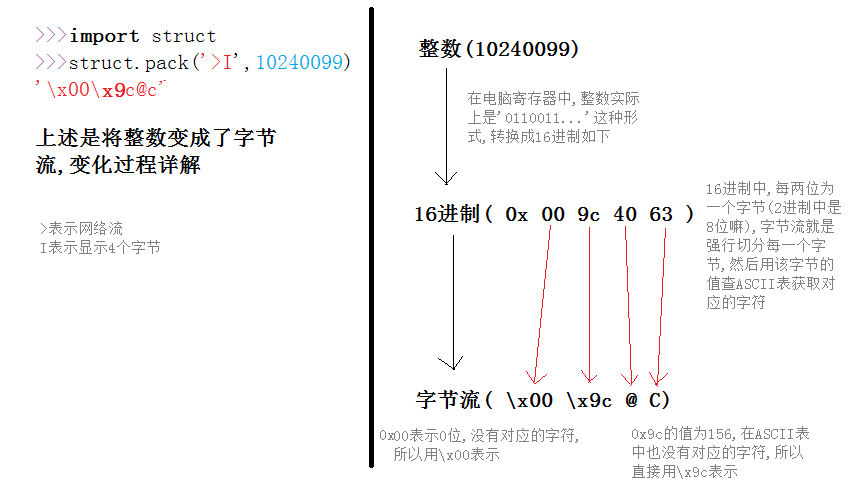
解码(字节流变整数):struct.unpack('>I','\x00\x9c@c')
'>IH':先取4字节的字节流为一组转化,然后再去2字节的字节流为一组转化.
11.摘要算法hashlib(模拟账号注册和登陆)
import hashlib,time
db = {} #创建一个字典
#密码算法转化
def get_md5(username,password):
md5 = hashlib.md5() #创建摘要算法实例进程
md5.update(password+username+'abc') #实现算法转化
return md5.hexdigest() #返回转化的密码
#保存账号和密码
def register(username,password):
db[username] =get_md5(username,password)
print '\n恭喜你注册成功!'
print '你的账号是%s,你的密码是%s,请记住哦!\n\n\n\n' % (username,password)
if __name__ == '__main__':
while True:
choice = int(raw_input('请选择:1.登陆。2.注册。3.退出\n'))
if choice ==1:
username = raw_input('请输入你的账号:')
password = raw_input('请输入你的密码:')
while username not in db or get_md5(username,password) != db[username]:
print '你输入的账号密码有误,请重新输入!'
username = raw_input('请输入你的账号:')
password = raw_input('请输入你的密码:')
time.sleep(1)
print '\n成功登陆!\n\n\n\n'
elif choice == 2:
username = raw_input('请输入你要注册的账号:')
while username in db:
username = raw_input('用户名已经存在,请重新输入:')
password = raw_input('请输入你要注册的密码:')
register(username,password) #记录账号密码并算法转化密码
time.sleep(1)
else:
break12.itertools(无限迭代对象)
import itertools
#itertools都需要for循环调用,因为都是迭代对象
# itertools.count(1) #无限加1
# itertools.cycle('ABC') #无限循环'A' 'B' 'C' 'A' 'B' ...
# itertools.repeat('A',10) #重复打印10个A
#把迭代对象串联起来
for c in itertools.chain('AB','BC'):
print c
#返回'A' 'B' 'B' 'C'
#key是函数返回值,group是代入值(就是那些字母)
for key,group in itertools.groupby('AaaBBbcAAa',lambda c: c.upper()):
print key,list(group)
#itertools.count(1)是让代入值自动加1,而不是函数返回值.
r = itertools.imap(lambda x:x*x,itertools.count(1))
for n in itertools.takewhile(lambda x:x<100,r):
print n
#返回1 4 9 16 ...81
#还有个ifilter(),没练习13.XML解析网页数据
import urllib #用来抓去网站信息的模块
from xml.parsers.expat import ParserCreate #解析器
import re #正则表达式
try:
#创建链接实例,获取百度天气API
page = urllib.urlopen('http://api.map.baidu.com/telematics/v2/weather?location=%E4%BD%9B%E5%B1%B1&ak=B8aced94da0b345579f481a1294c9094')
#读取实例内容,赋值给XML
XML = page.read()
finally:
page.close() #不能使用with as,貌似实例没有__exit__
a = re.compile(r'^\s+$') #空格,正则表达式
class BaiduWeatherSaxHandler(object):
def __init__(self):
self.L = [] #创建一个list装XML中的关键数据
self.R = False #当start_element获得的name与
self.d = ['currentCity','date','weather','wind','temperature']
def start_element(self,name,attrs):#获取开始符的信息
# print ('sax:start_element:%s,attrs:%s' % (name,str(attrs)))
if name in self.d:
self.R = True
def end_element(self, name):#获取结束符的信息
# print ('sax:end_element: %s' % name)
if name == 'result': #只让程序显示当天的天气(API中还有未来几天的)
for x in self.L:
print x
raise SystemExit #关闭程序
def char_data(self, text):#获取符号之间的内容
if a.match(text): #去掉空格的(没内容的)
pass
elif self.R:
self.L.append(text)
self.R = False
# else:
# print ('sax:char_data: %s' % text)
handler =BaiduWeatherSaxHandler() #设置解析方法
parser =ParserCreate() #创建解析器
# 设置解析器参数
parser.returns_unicode = True #返回unicode编码
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(XML) #解析文本14.HTMLParser(没详细练习过)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from HTMLParser import HTMLParser
from htmlentitydefs import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs): #开始符,比如<html><head>
print('<%s>' % tag)
# def handle_endtag(self, tag): #结束符,比如</html>
# print('</%s>' % tag)
# def handle_startendtag(self, tag, attrs): #不详
# print('<%s/>' % tag)
def handle_data(self, data): #页面中的文字,比如Some,没有<>裹着的
print('data %s' % data)
# def handle_comment(self, data): #不详
# print('<!-- -->')
# def handle_entityref(self, name): #不详
# print('&%s;' % name)
# def handle_charref(self, name): #不想
# print('&#%s;' % name)
parser = MyHTMLParser()
parser.feed('<html><head></head><body><p>Some <a href=\"#\">html</a> tutorial...<br>END</p></body></html>')















 1701
1701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









