






一、
冗余磁盘阵列技术总结:
RAID0:
原理:将文件数据平均的分配给每块磁盘
冗余性:无
性能:读写能力有提升
至少需要几块磁盘:1+
利用率:100%
RAID1:
原理:将文件数据多备份一份到一块磁盘里
冗余性:允许物理损坏一块磁盘,不防止人为的误操作
性能:无提升
至少需要几块磁盘:2+
利用率:N-1/N
RAID5:
原理:将文件数据平均分配给磁盘,然后利用异或算法算出一个校验值,并把校验值平均存放到每块磁盘里
冗余性:允许损坏一块磁盘
性能:读写能力有提升
至少需要几块磁盘:3+
利用率:N-1/N
RAID10:
原理:RAID1和RAID0组合,先布置RAID1阵列,然后组合成RAID0,文件数据平均分配给每组磁盘,然后每组进行备份
冗余性:每组镜像允许物理损坏一块磁盘
性能:读写能力有提升
至少需要几块磁盘:4+
利用率:1/2
RAID01:
原理:RAID0和RAID1组合,先布置RAID0阵列,然后组合成RAID1,文件数据先备份分给每组磁盘,然后每组RAID1阵列将数据平均分配给每个磁盘
冗余性:允许损坏一组镜像
性能:读写能力有提升
至少需要几块磁盘:4+
利用率:1/2
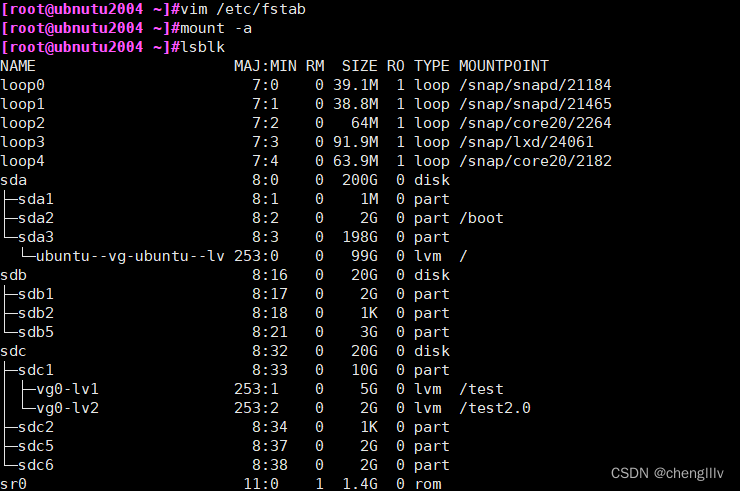
二、LVM磁盘扩容及缩容
将块设备变成物理卷

建立卷组

在卷组vg0上建立逻辑卷

设置文件系统
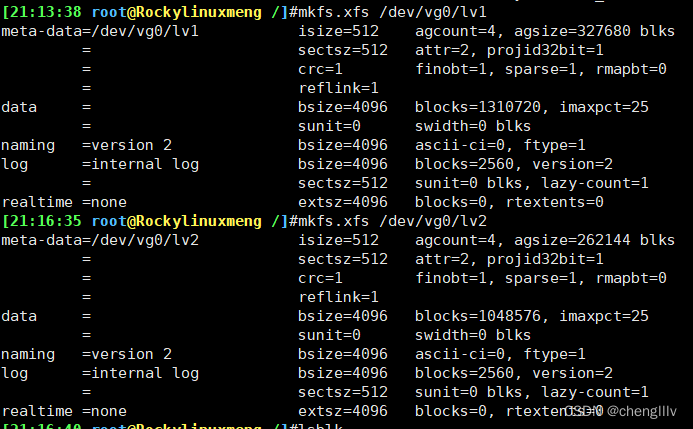
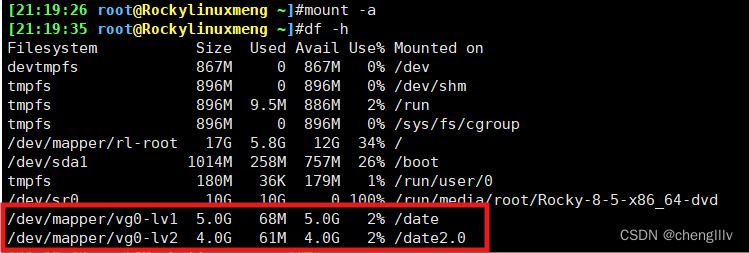
挂载
![]()

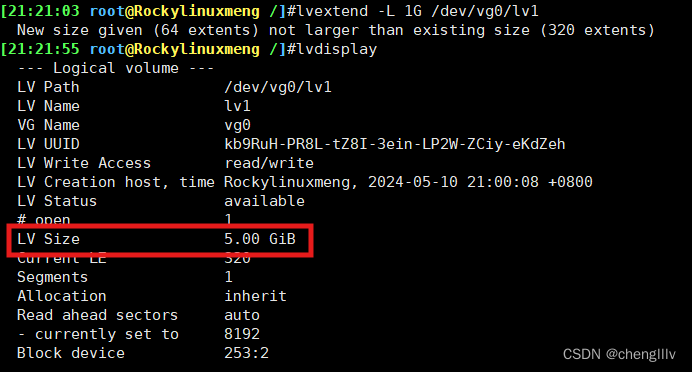
逻辑卷扩容
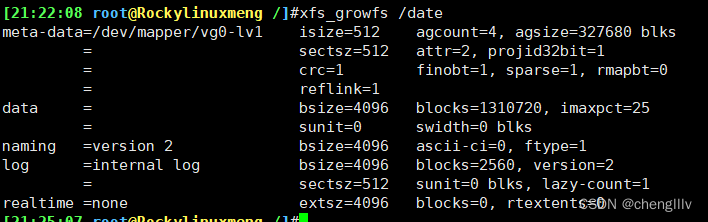
文件系统扩容
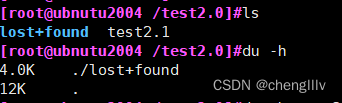
缩减逻辑卷(xfs文件系统不支持缩减)
先将要缩容的逻辑卷所挂载的目录里的文件进行备份

![]()
解除挂载
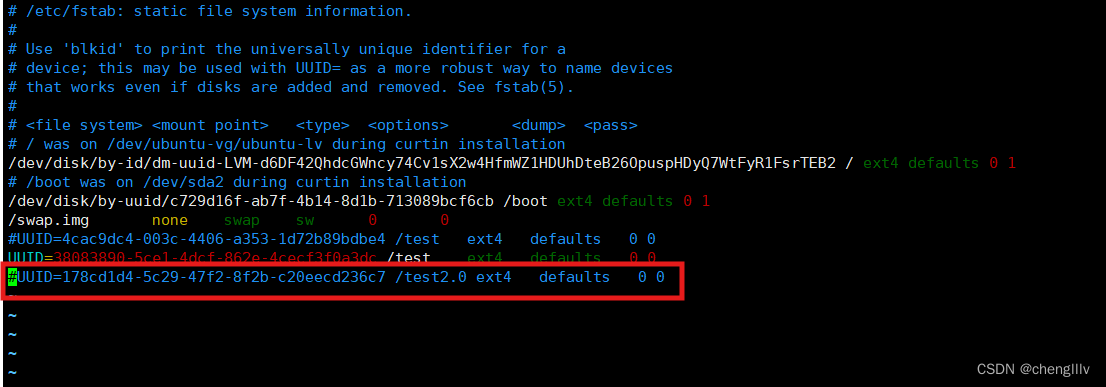
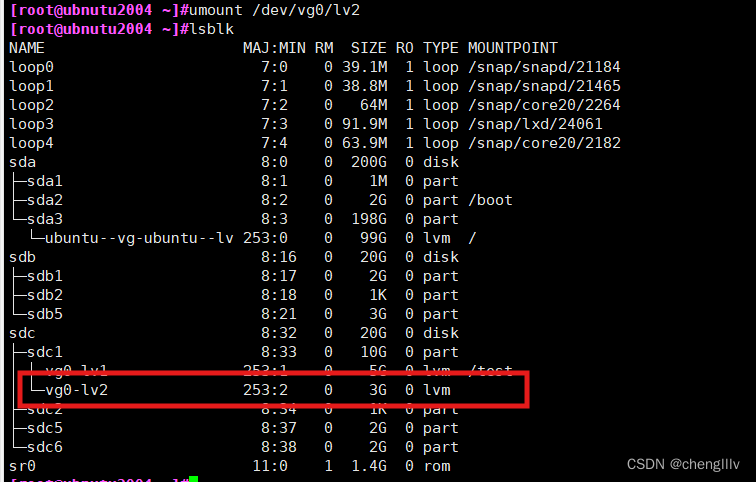
检查文件系统完整性
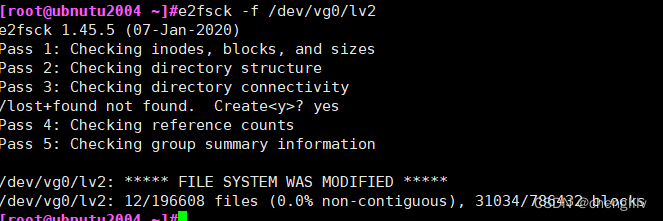
缩减文件系统

缩减逻辑卷
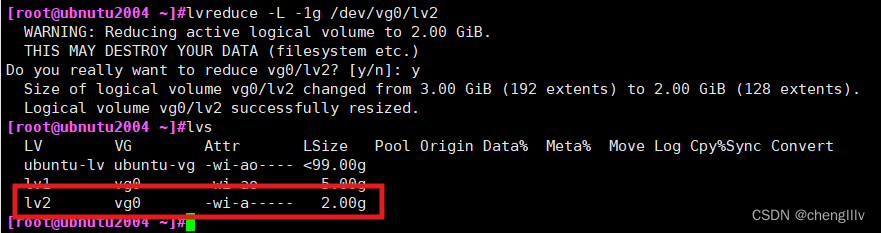
重新挂载
三、
程序包管理器:
redhat系列:rpm,yum,dnf
ubnutu:dpkg,apt
包中包含的文件:元数据,包安装或卸载时运行的脚本
程序包的获取途径:
1、系统发版的光盘或官方网站
2、第三方组织提供
3、软件项目官方站点
4、搜索引擎
5、自己制作
rpm -i :下载包
-iv :显示下载过程
-ih:显示安装进度
-e:卸载包
-q 包名:查看包是否安装
-ql:显示包文件列表
-qi:显示包文件详细信息
-qf:查看文件来自哪个包
yum install :下载包(自动解决软件包的依赖关系)
reinstall: 重新下载
-v:查看详细内容
repolist:查看仓库列表
remove:卸载
-y install --downloadonly --downloaddir=/data/httpd httpd(示例):只下载相关包到指定路径下,而不安装。
info:查看程序包
provides 文件(完整路径):查看文件来自哪个包
clean all:清理缓存的包元数据
dnf reposync --repoid=extras --download-metadata -p /var/www/html/centos:将服务器端的包和元数据下载下来
四、
yum/dnf工作原理:服务器端搭建仓库,里面包含包和元数据,在客服端搭建寻址路径仓库,使用yum/dnf命令下载时先下载元数据,然后根据元数据里的内容下载所需的包和依赖包,下载安装结束后删除包,元数据保留在缓存里
搭建私有云仓库
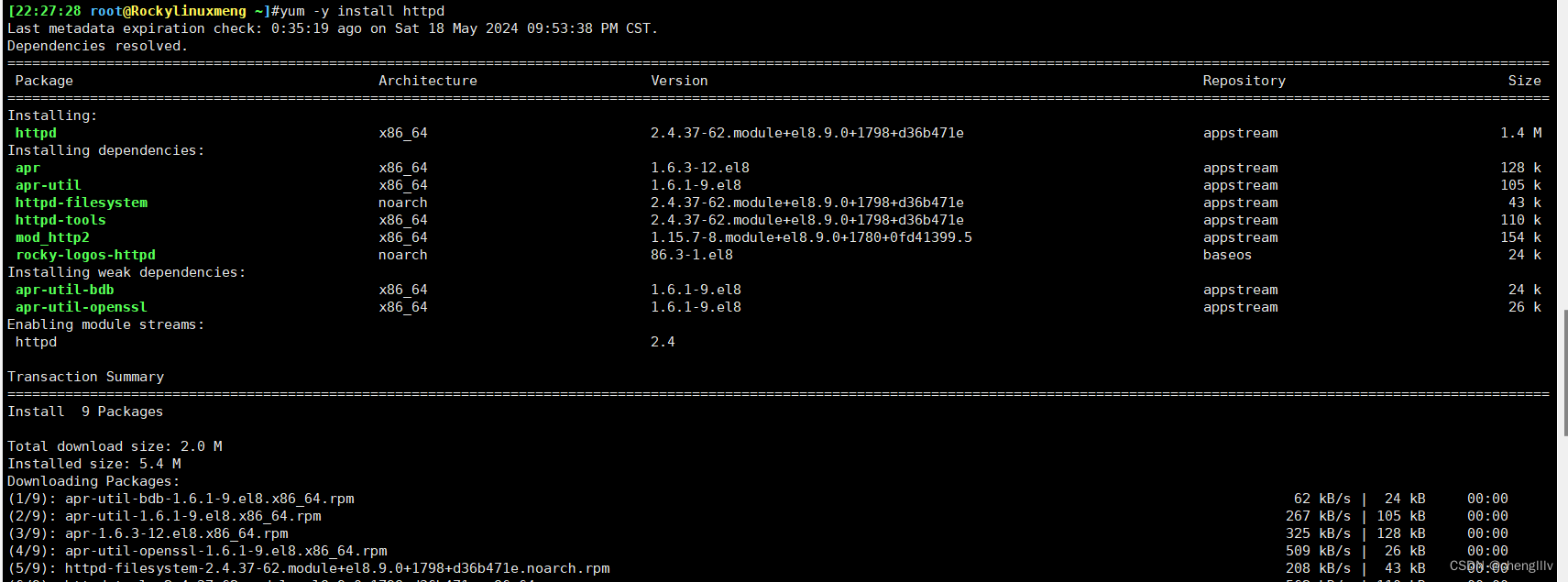
1、baseos
下载httpd
启用httpd服务

在/var/www/html/目录下建立rocky/8/目录(系统版本型号)
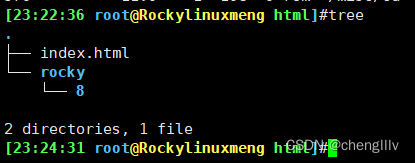
创建BaseOS仓库
方法一:将光盘里的仓库文件复制下来
挂载光盘

将光盘的baseos仓库文件复制下来
![]()
创建epel仓库
方法二:将公有云上的仓库数据下载下来
创建epel目录
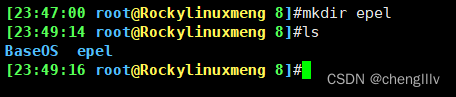
将公有云的epel仓库的包和元数据下载下来
![]()

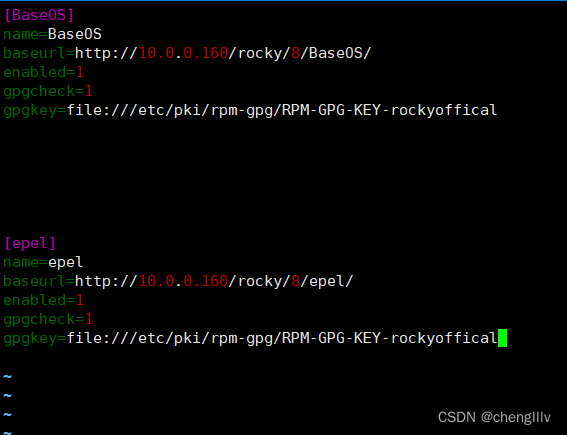
在另一个主机上创建客户端仓库
清理yum仓库元数据缓存

创建yum仓库

五、
系统安装后常用的初始化步骤
yum -y install gcc make autoconf gcc-c++ glibc glibc-devel pcre pcre-devel openssl
openssl-devel systemd-devel zlib-devel vim lrzsz tree tmux lsof tcpdump wget net-tools iotop bc bzip2 zip unzip nfs-utils man-pages
关闭防火墙
systemctl disable --now firewalld
关闭SELinux
vim /etc/selinux/config
SELINUX=disabled
实现邮件通信
yum -y install postfix mailx
systemctl enable --now postfix
六、
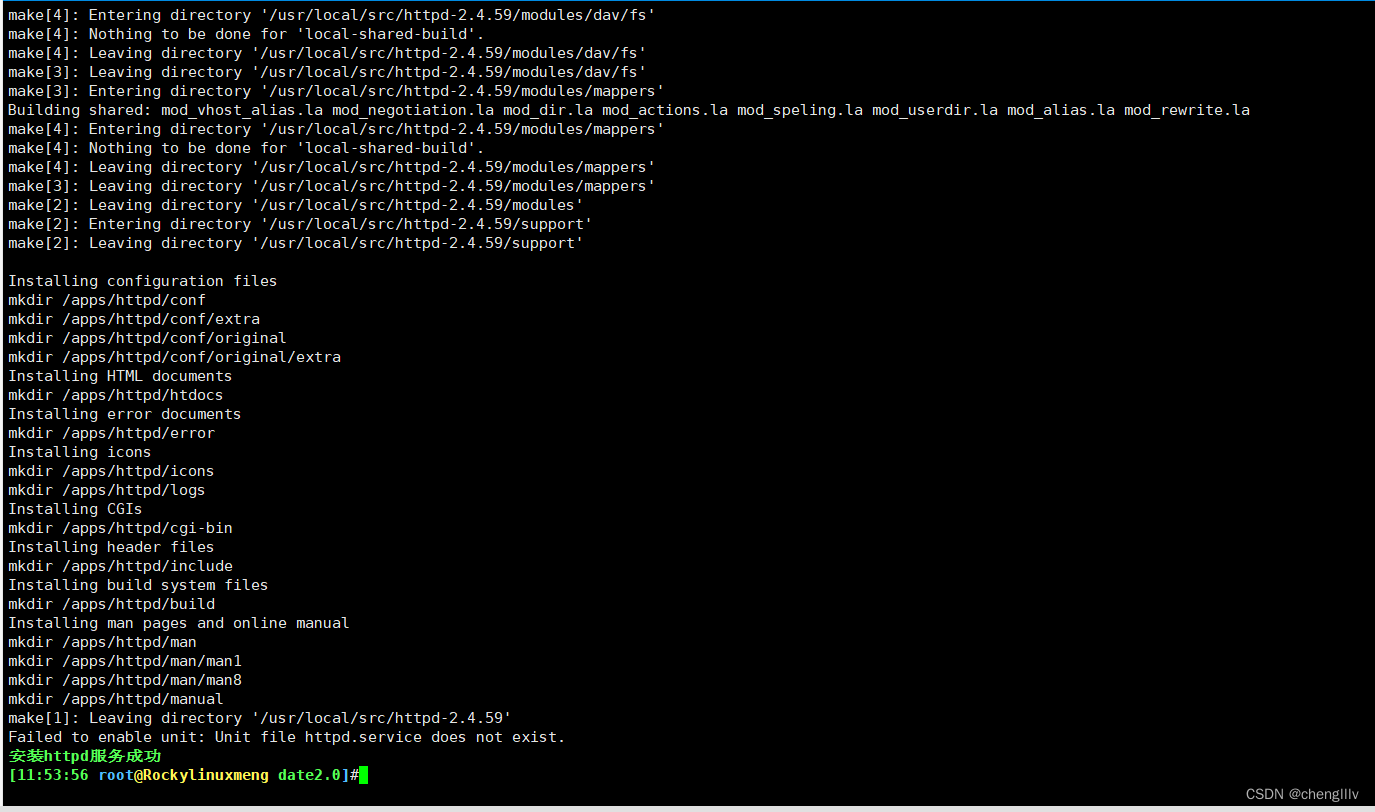
一键安装httpd脚本
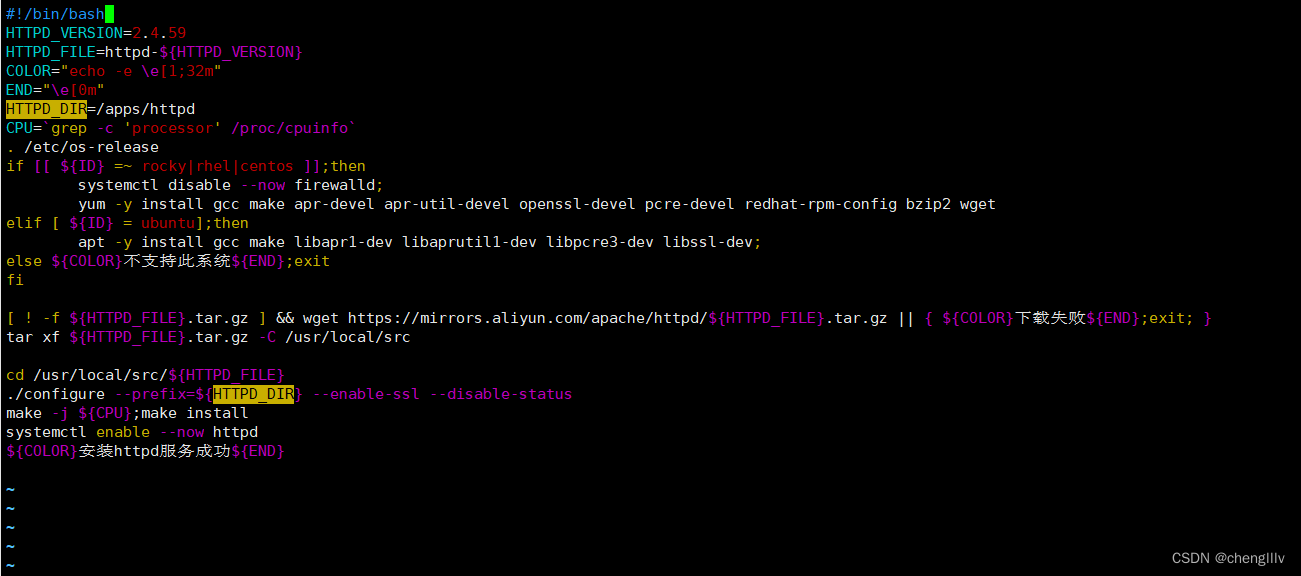
![]()
七、
总结开放系统互联OSI模型,每层作用及对应的协议
应用层:提供为应用软件而设的接口,以设置与另一应用软件之间的通信
表示层:把数据转换为能与接受者和系统格式兼容并适合传输的格式
会话层:负责在数据传输中设置和维护电脑网络中两台电脑之间的通信连接
传输层:把传输表头加至数据以形成数据包
网络层:跨网段通讯
链路层:局域网内部通讯,有源地址和目标地址
物理层:约定了网络通讯的物理特性
八、
调整动态端口范围

九、
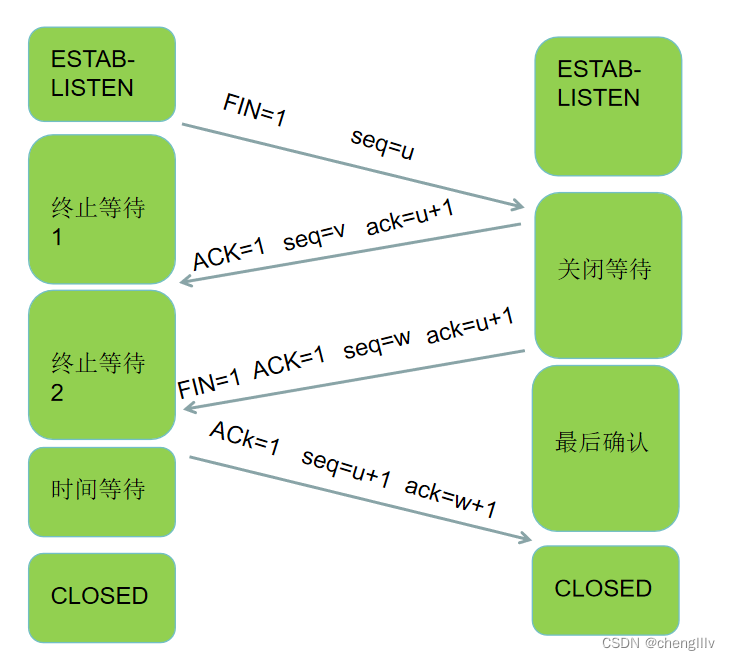
TCP包头结构:由源端口,目标端口,序号,确认号,数据偏移,URG,ACK,PSH,RST,SYN,FIN,窗口大小,校验和,紧急指针,选项部分组成
源端口和目标端口:计算机进程之间相互通信的身份识别标志
序列号:数据传输时会把数据分成多个包传输,每个包进行编号,表述本报文段发送数据的第一个字节的编号
确认号:表示期待收到发送方下一个报文段的第一个字节数据的编号
数据偏移:TCP报文段的首部长度
URG:表示本报文段中发送的数据是否包含紧急数据
ACK:表示是否前面的确认好字段有效
PSH:提示接收端应用程序应该立即从TCP接收缓冲区中读走数据,为接收后续数据腾出空间
RST:如果收到一个RST=1的报文,说明与主机的连接出现了严重错误,必须释放连接,然后重新建立连接
SYN:请求建立连接
FIN:表示通知对方本端要关闭连接
窗口大小:表示允许对方发送的数据量
校验和:提供额外的可靠性
紧急指针:标记紧急数据在数据字段中的位置
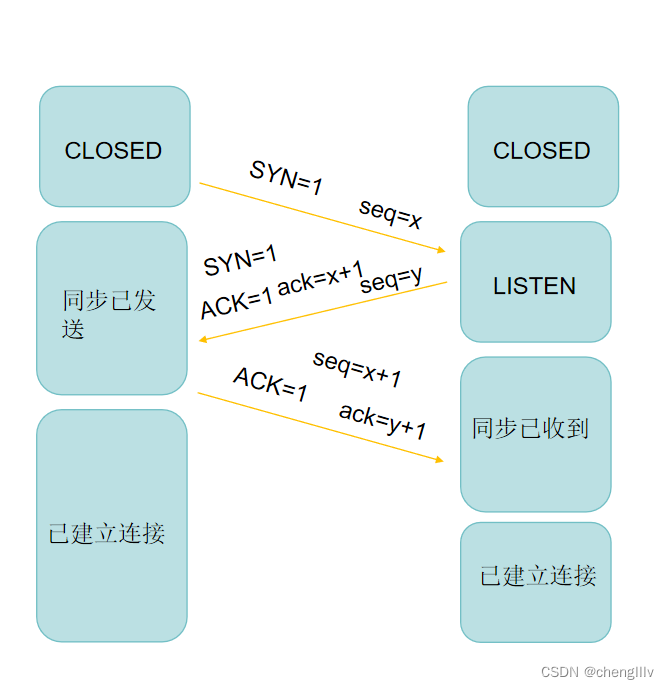
TCP三次握手:
主机1向主机2第一次握手表示主机1可以正常发送数据
主机2向主机1第二次握手表示主机2知道主机1可以正常发送数据,并且主机2能够正常发送数据,此时主机1也知道主机2可以正常发送和接收数据
主机1向主机2第三次握手表示主机2知道主机1可以正常接受数据
经过三次握手,两个要进行通讯的主机都确认了彼此可以正常的进行数据的发送和接收,可以建立连接
十一、
A类:0开头,网络地址范围1-126
B类:10开头,网络地址范围128-191
C类:110开头,网络地址范围192-223
D类:1110开头,网络地址范围224-239(多播)
ip地址由网络ID和主机ID还有子网掩码组成,子网掩码规定了网络ID的位数。列如10.0.0.100/24,10.0.0是网络ID,100是主机ID。
十三、
当A(10.0.1.1/16)与B(10.0.2.2/24)通信,A如何判断是否在同一个网段?A和B能否通信?
用A的ip地址和A的子网掩码进行与运算,得出A的网络id是10.0.0.0,用A的子网掩码与B的ip地址进行与运算,得出B网络id是10.0.0.0,所以当A向B进行通讯时,A与B在同一网段内,可以进行通讯。
十四、
如何将10.0.0.0/8划分32个子网?
求每个子网的掩码,主机数
2^5=32 网络id向主机id借5位,子网掩码:8+5=13,主机数:2^(32-13)-2=524286个
十五、
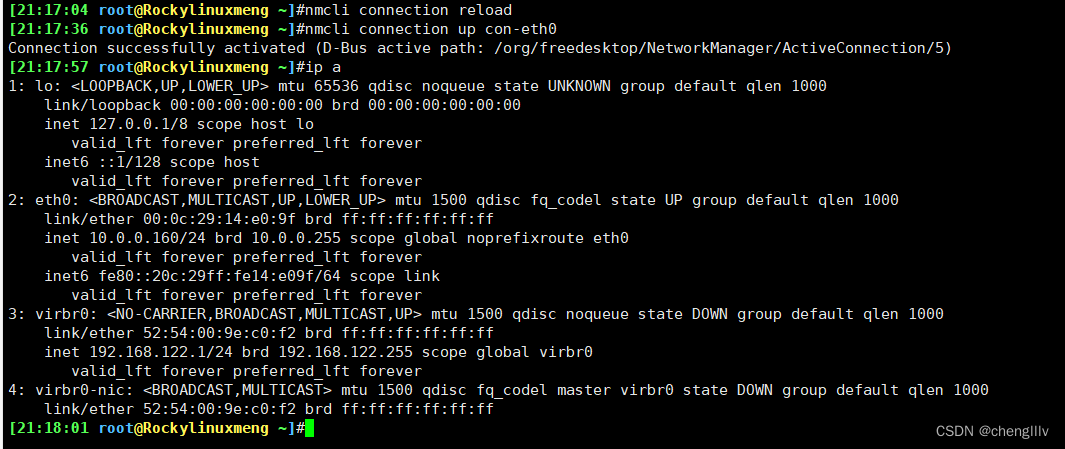
通过网络配置命令,让主机可以上网。 ip, netmask, gateway, dns,主机名。相关命令总结,最终可以通过这些配置让你的主机上网
十六、
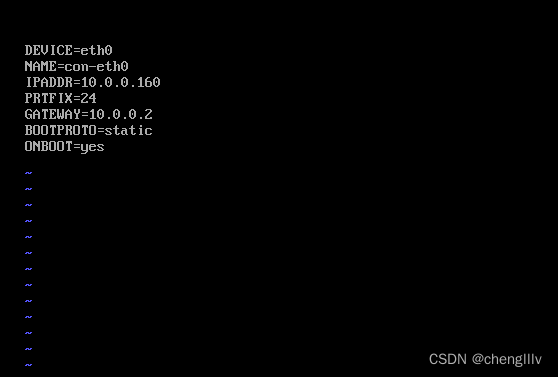
解析/etc/sysconfig/network-scripts/ifcfg-eth0配置格式
十七、
基于配置文件或命令完成bond0配置

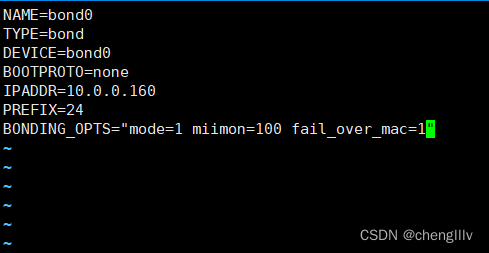
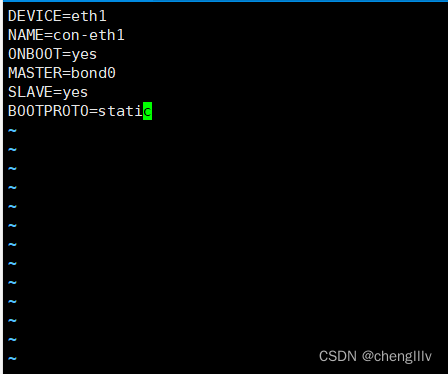
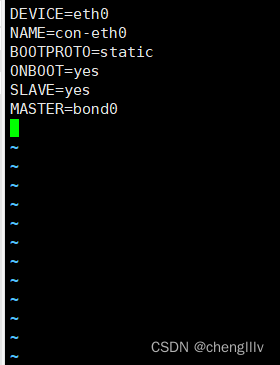
![]()
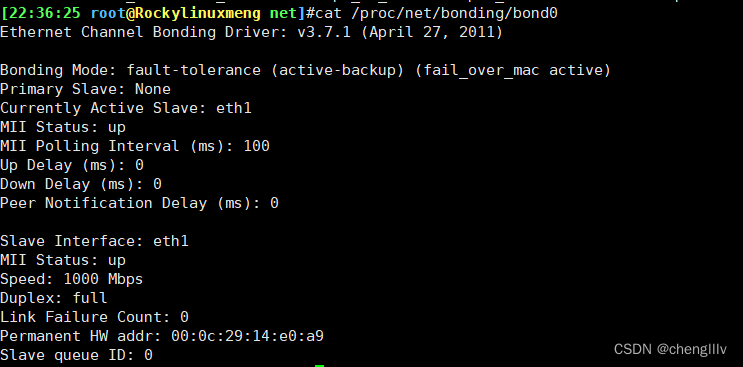
十八、
通过ifconfig命令结果找到ip地址
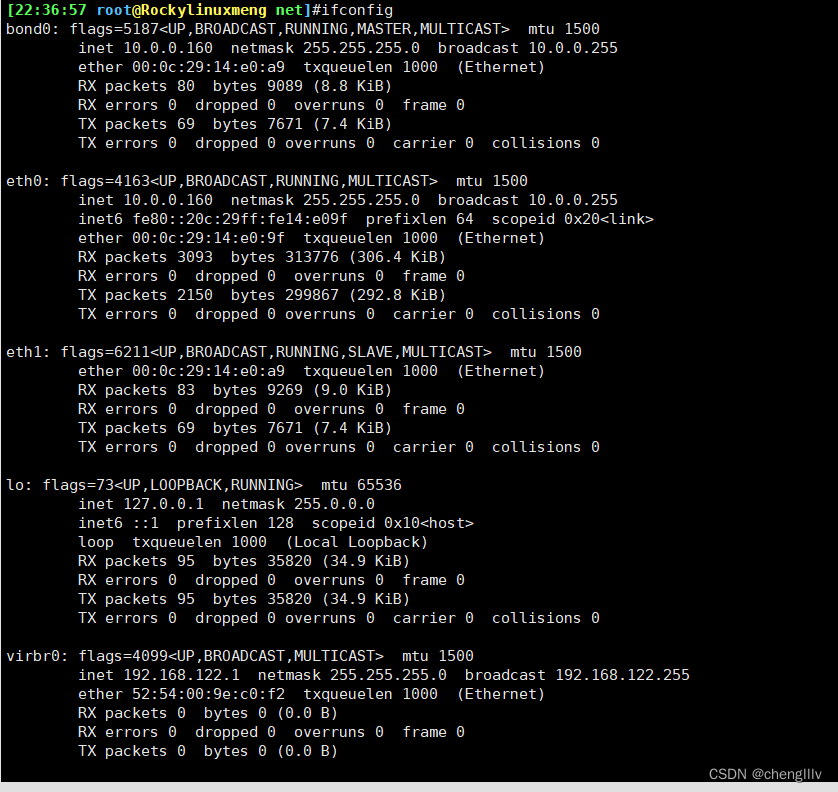















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









