






感谢DT大数据梦工厂支持提供以下内容,
DT大数据梦工厂专注于Spark发行版定制。详细信息请查看
联系邮箱18610086859@126.com
电话:18610086859
QQ:1740415547
微信号:18610086859
IMF晚8点大数据实战YY直播频道号:68917580
1. 构建StreamingContext
StreamingContext根据SparkConf构建SparkContext
这进一步说明Spark Streaming就是Spark Core上的一个应用程序。
2. 定义DStream,以socketTextStream为例:


SocketInputDStream是DStream的子类,DStream将接受到的数据封装成一个RDD
* DStreams internally is characterized by a few basic properties: * - A list of other DStreams that the DStream depends on * - A time interval at which the DStream generates an RDD * - A function that is used to generate an RDD after each time interval * DStreams内部特征是一些基本性质: * - 依赖其他DStreams列表 * - 在一个时间间隔内生成一个RDD * - 在每个时间间隔有一个方法来生成一个RDD

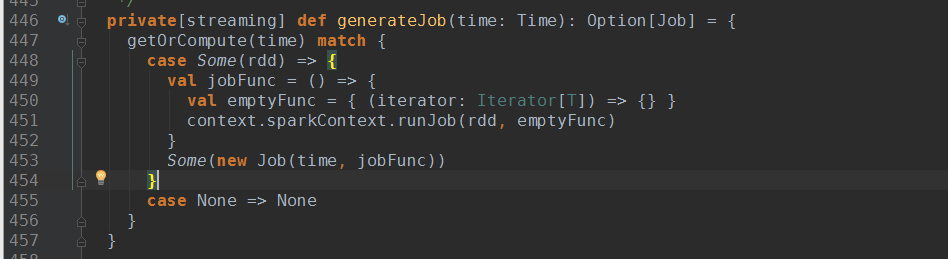
3. StreamingContext.start()方法调用scheduler.start();

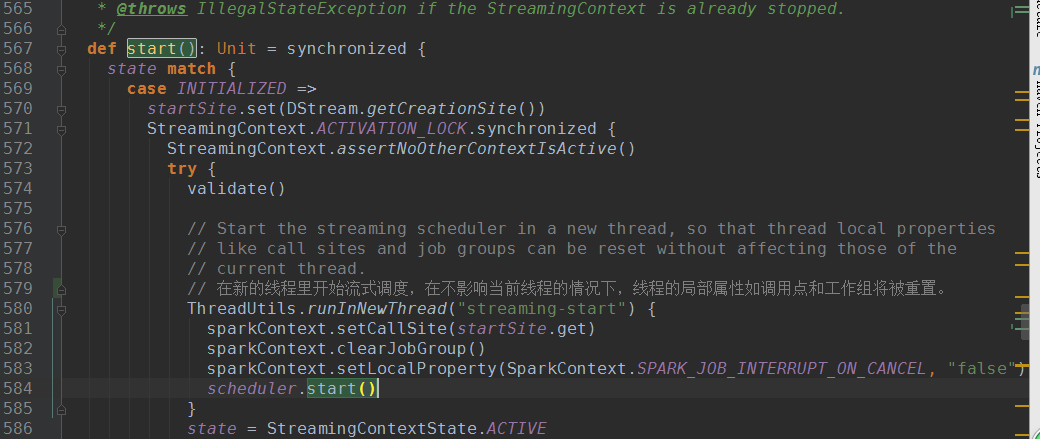
4. scheduler.start()方法中启动eventLoop、listenerBus、executorAllocationManager、receiverTracker、jobGenerator

在EventLoop中

返回JobScheduler中,eventLoop重写onReceive方法,调用proccessEvent方法


再看ReceiverTracker中的start()方法:

launchReceivers()方法向ReceiverTrackerEndpoint发送StartAllReceiver消息

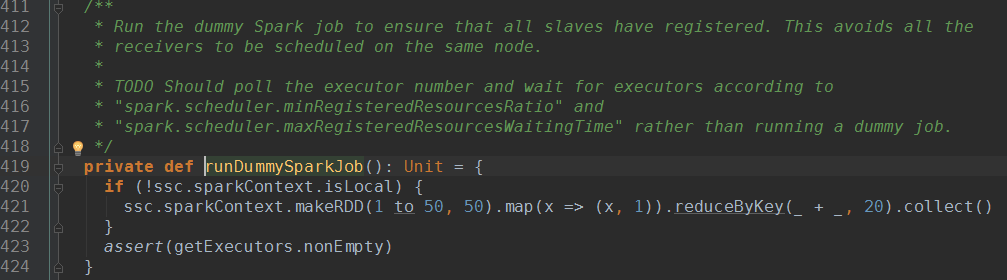
ReceiverTrackerEndpoint接收到StartAllReceiver消息后调用startReceiver方法启动receiver
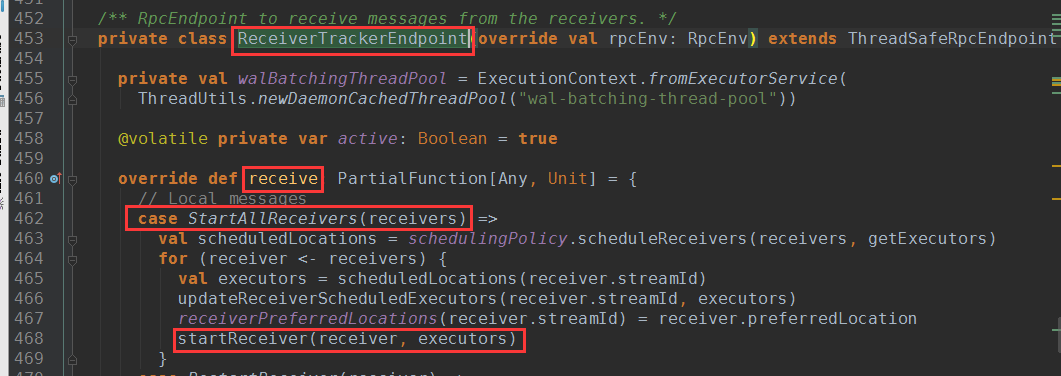
startReceiver()方法中,将receiver作为入参创建ReceiverSupervisorImpl实例,并调用该实例的start()方法

ReceiverSupervisorImpl的start()方法在其父类ReceiverSupervisor中定义
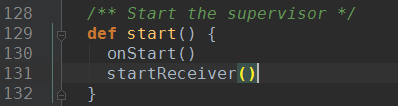
ReceiverSupervisorImpl中重写onStart()方法

startReceiver()方法在ReceiverSupervisor中定义,在这个方法中调用receiver的onStart()方法

receiver的onStart()方法中定义了Receiver启动的必要步骤
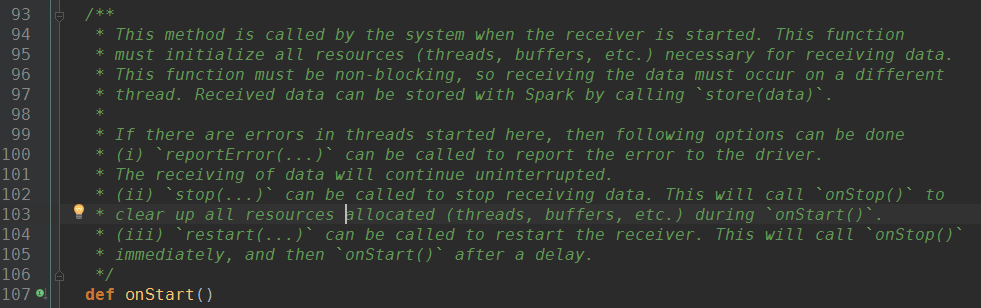
以Receiver的一个子类KafkaReceiver为例:

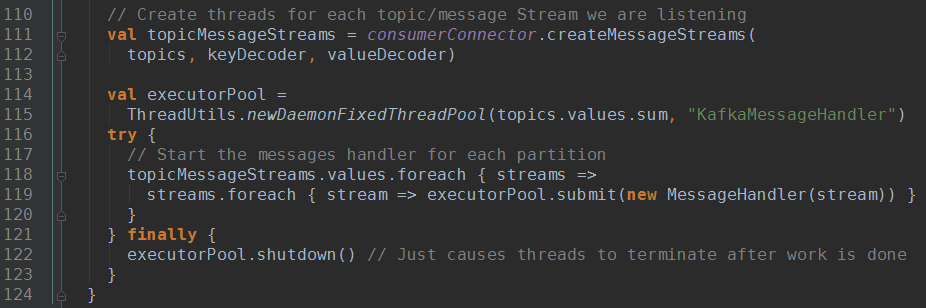
至此,Receiver启动















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









