






感谢DT大数据梦工厂支持提供以下内容,DT大数据梦工厂专注于Spark发行版定制。详细信息请查看
简介: 王家林:DT大数据梦工厂创始人和首席专家. 联系邮箱18610086859@126.com 电话:18610086859 QQ:1740415547 微信号:18610086859
为什么以SparkStreaming作为切入点,进行对Spark剖析?
一. Spark最开始就是原始的Spark Core,而Spark Streaming是Spark Core上的一个子框架,通过Spark一个子框架的彻底研究,进而精通Spark。
二. Spark 有Spark SQL , Spark Streaming, Spark GraphX, Spark MLlib, Spark R等众多子框架,为什么选择Spark Streaming作为切入点呢?首先,除了Spark Core编程外,Spark SQL是使用最多的,但是Spark SQL涉及了太多SQL语法细节的解析和优化,SQL的解析和优化是重要的事情,但对于剖析Spark不是最重要的事情,由于有太多的语法解析需要研究,不适合作为一个子框架进行研究;而Spark R还不成熟,支持功能有限也排除;Spark GraphX在Spark历届版本中几乎没有改进,按照这种趋势的话,Spark官方是不是透漏出一个信号,GraphX的发展几乎到了尽头;对于Spark MLlib,涉及太多的数学知识,数学知识是重要的事情,但对于Spark的研究也不是最重要的事情,所以也不利于专注于Spark的研究;而Spark Streaming作为大数据流处理框架,几乎对Spark感兴趣的人中,超过50%的人认为Spark Streaming对他最有吸引力:
在大数据领域,一切跟流式计算无关的数据都是无效数据,流式处理是大数据实时性解决方案的具体实现。
流式数据是我们对大数据的初步印象,数据流进来立即进行反馈,而不是批处理和数据挖掘。
Spark Streaming真正强悍的地方在于Spark Streaming,Spark SQL,Spark MLlib,Spark GraphX,Spark R一体化解决方案,而Spark Streaming作为数据接入的源头,其地位显而易见。
Spark Streaming动态的接收,处理不断流入的数据,最容易出问题,最受关注的地方,也是最容易展露大数据魅力的地方。
Spark Streaming最像Spark Core之上的一个应用程序,Spark Streaming作为接收数据源的数据,本身就是一个运行在Spark上的应用程序,最利于研究Spark运行的整个流程。
如何发现数据流入Spark Streaming中?
技巧:放大SparkStreaming接收数据的interval即StreamingContext的batchDuration入参,这样通过historyServer可以完整的获取Spark Streaming接收并处理一次外接数据的所有job的具体细节。




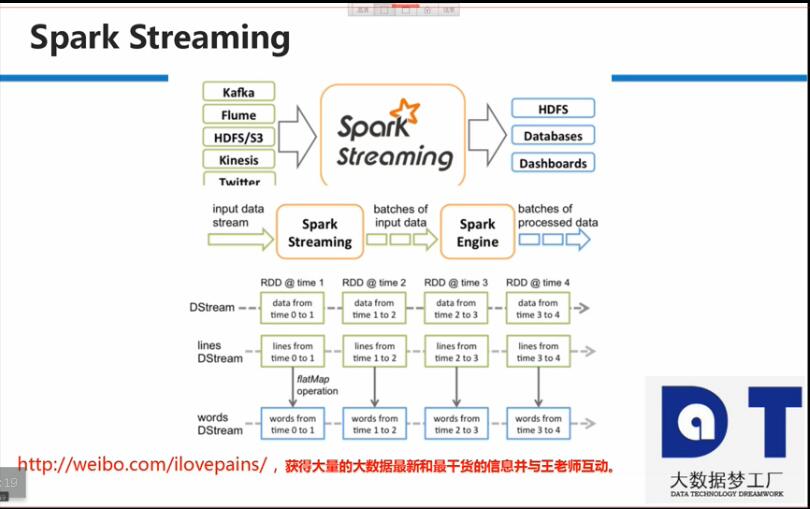
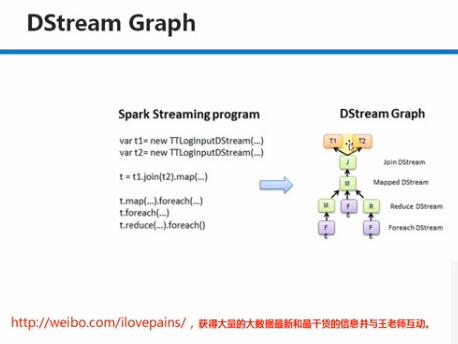
3. Spark Streaming
















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









