




前言:
论文中直接提供了GitHub 的代码下载地址
GitHub - junyanz/pytorch-CycleGAN-and-pix2pix: Image-to-Image Translation in PyTorch
这里面简单的解读一下.
目录:
1. 模型参数配置
2: 生成器模型
3: 鉴别器模型
4: network代码
5: cycleGAN代码
6: 训练和测试代码
一 参数配置模块
文件目录:options\train_options.py
参数配置是通过argparse 实现的,这样通过google colab 调试的时候
可以动态的设置超参数进行训练

动态设置超参数命令
python my_program.py--gender male--height1.75
二 生成器模型
在network.py中实现,后面在代码示例中,我直接提供了一个入口可以Debug一下
Total params: 11,378,179
Trainable params: 11,378,179
Non-trainable params: 0
生成器主要由5个模块组成

2.1 输入层
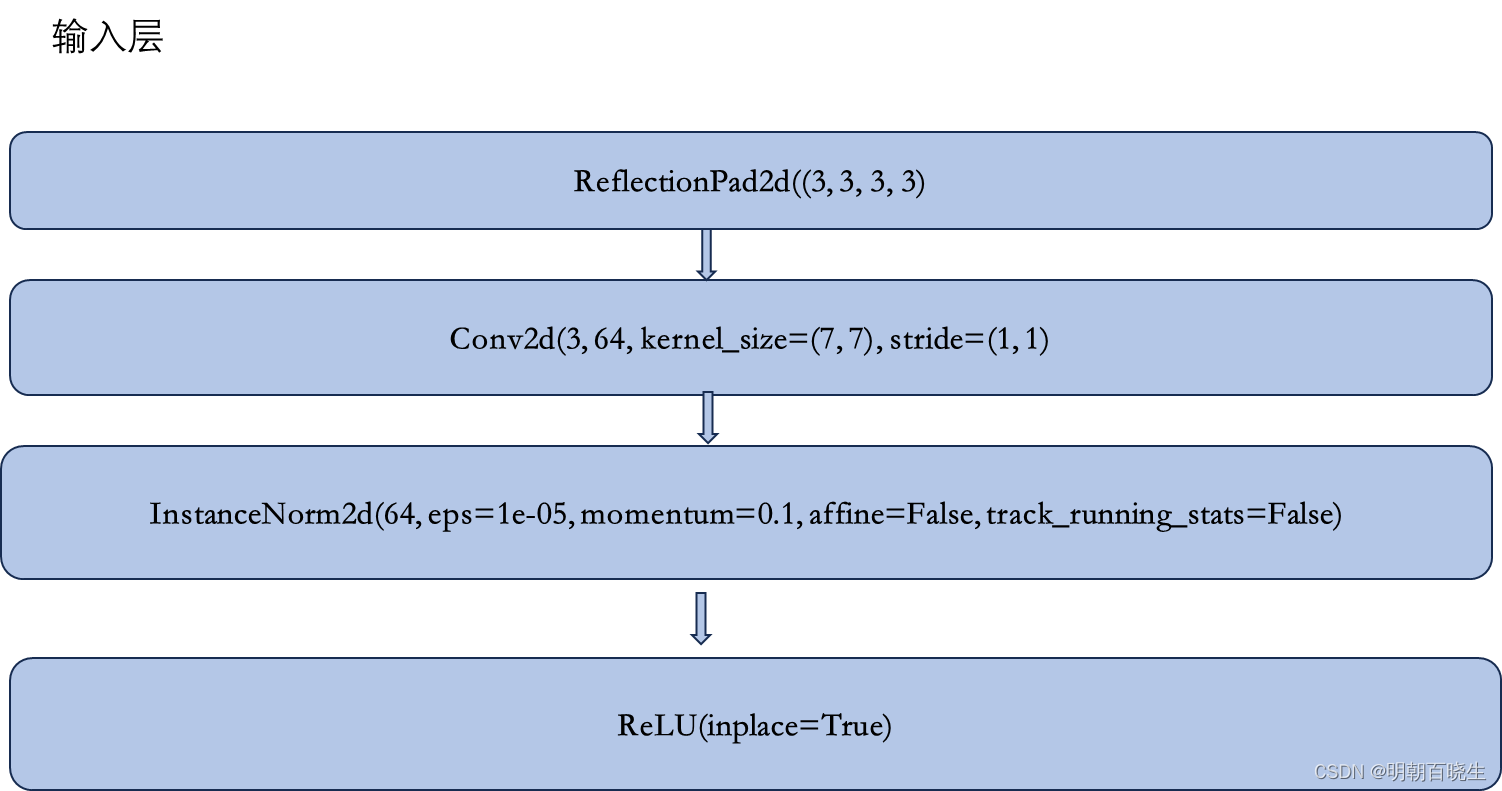
2.2 下采样层
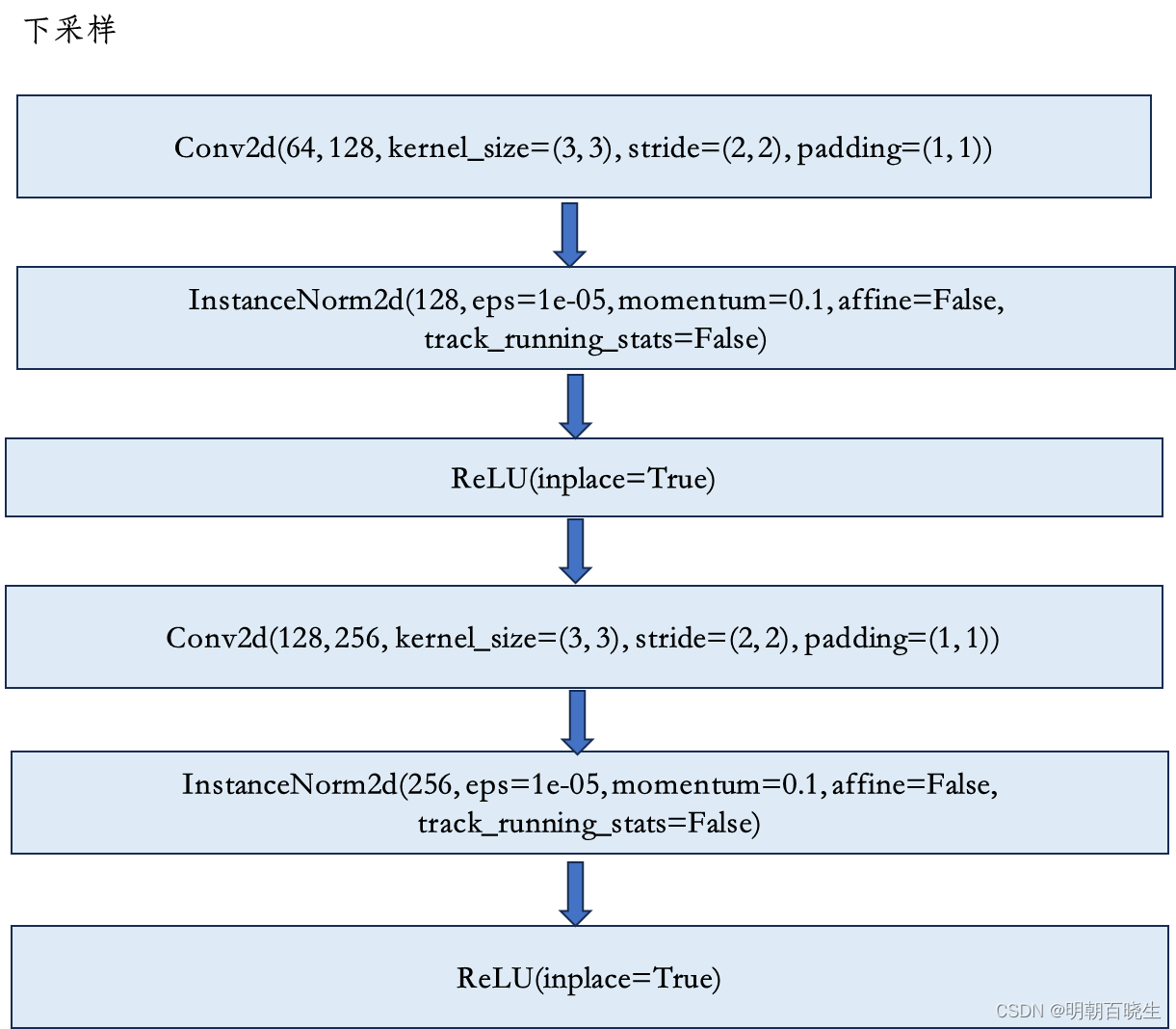
2.3 残差网络层,默认9个
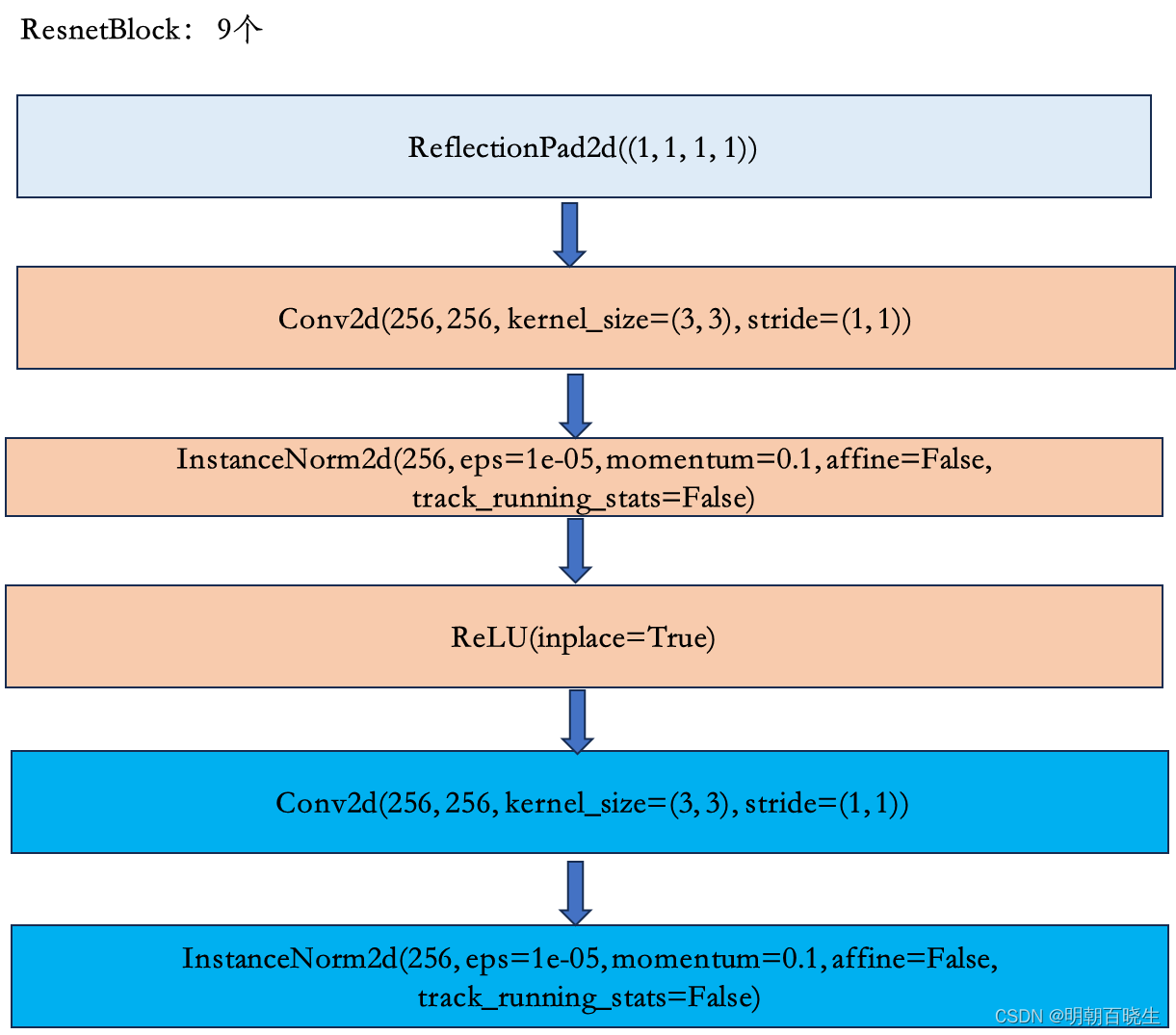
2.4 上采样层
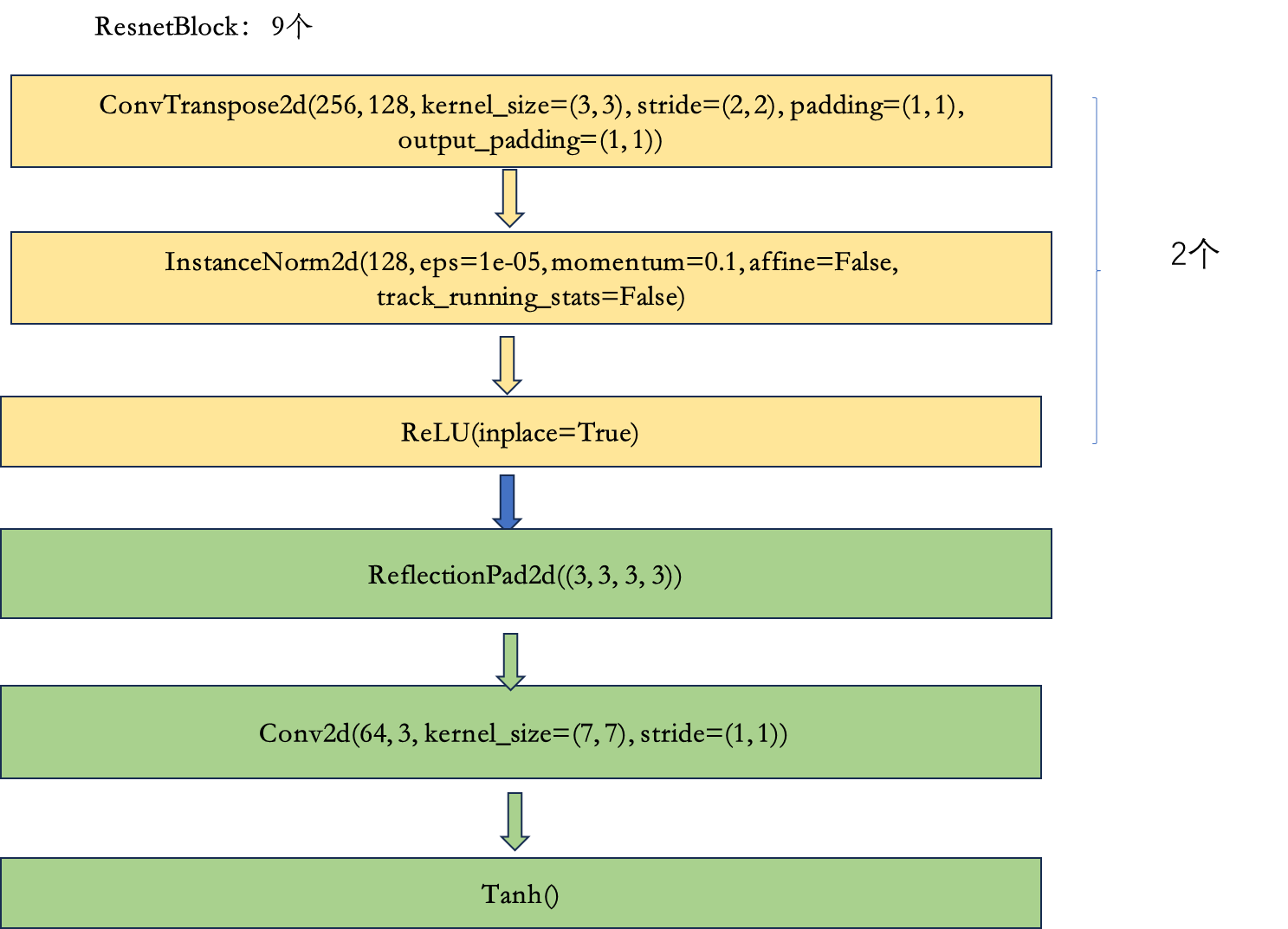
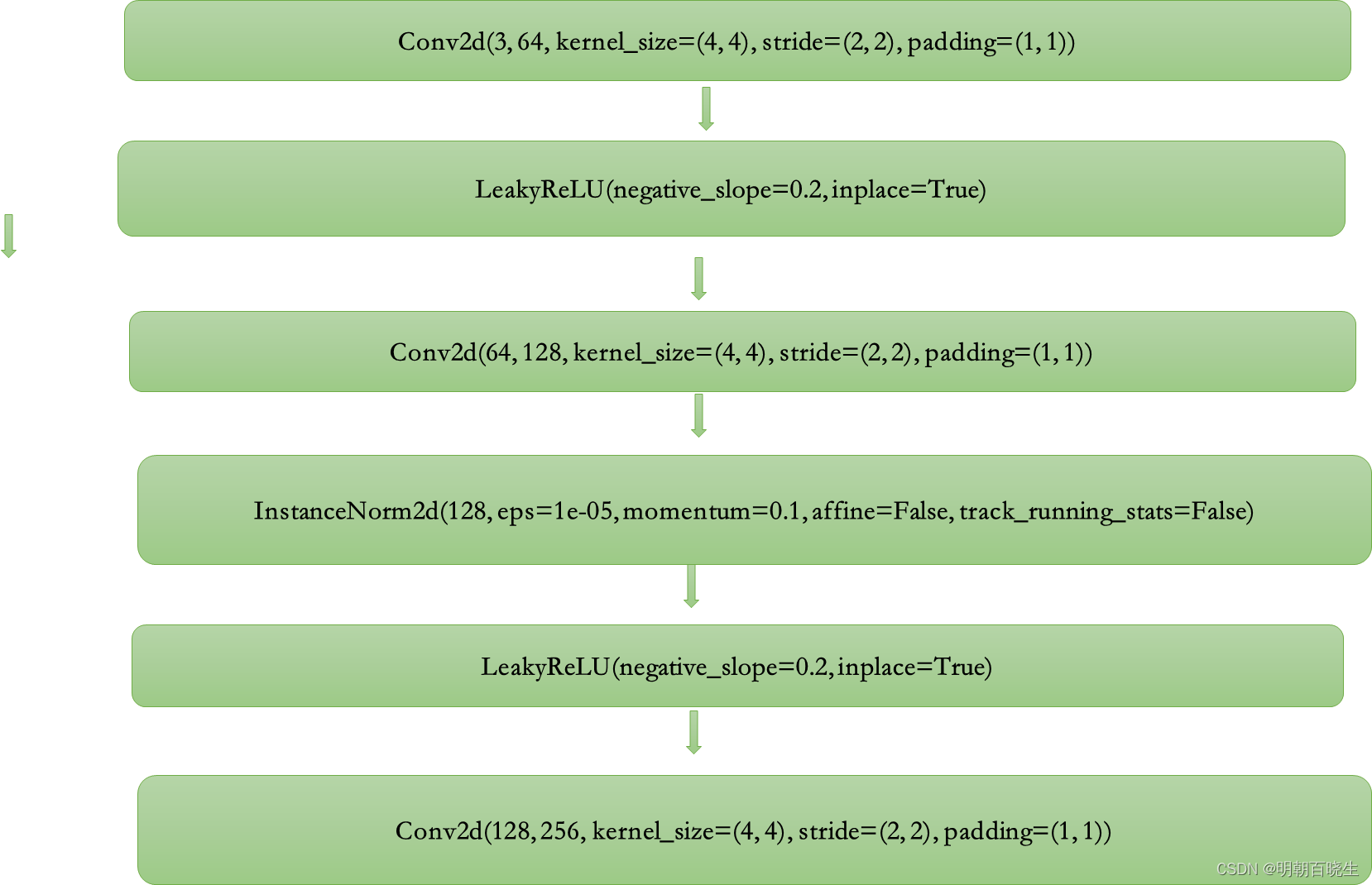
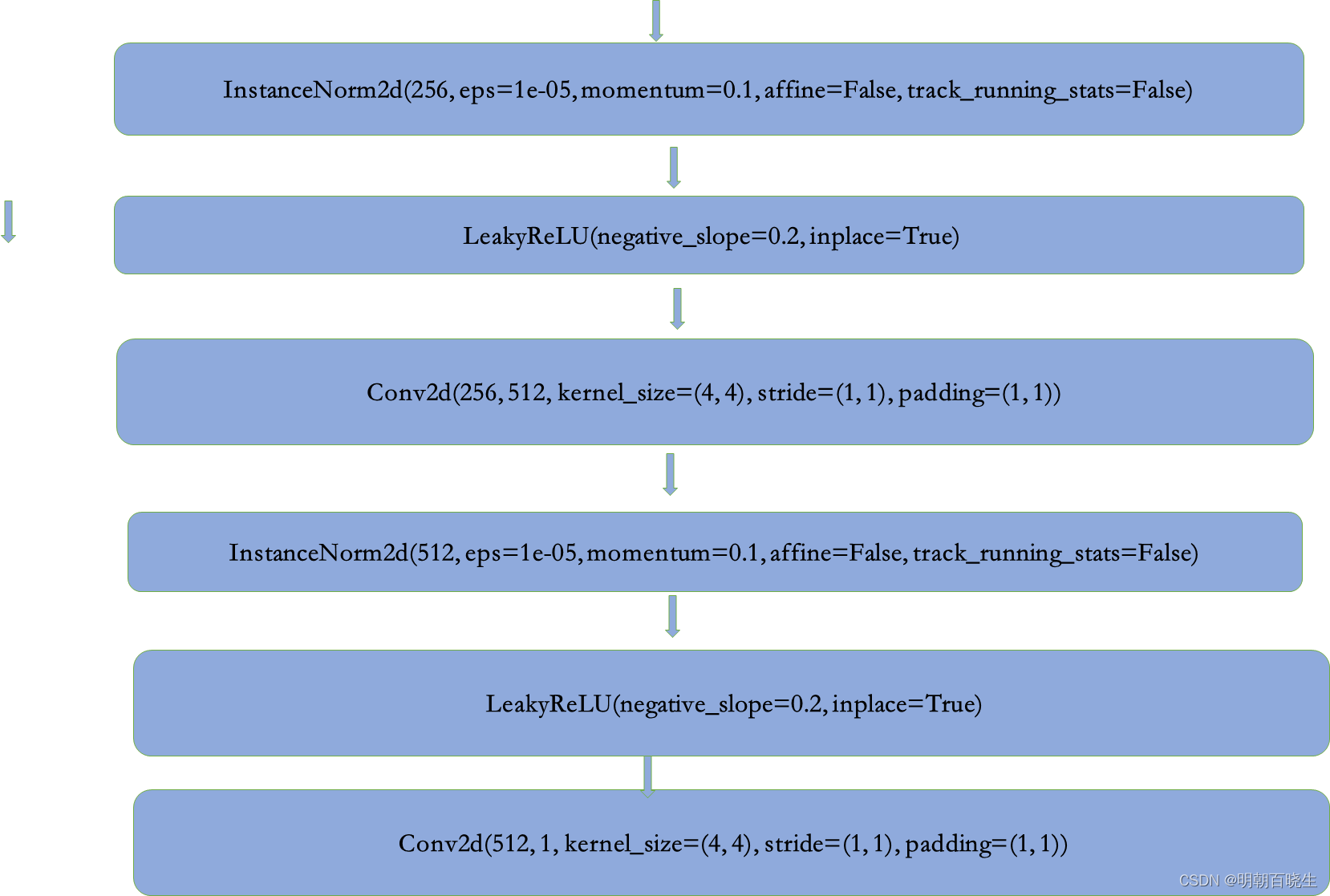
三 鉴别器模型
network.py中实现
Total params: 2,764,737
Trainable params: 2,764,737
Non-trainable params: 0
模型结构
四 networks.py
主要定义了生成器,鉴别器的网络结构
define_G 生成器
define_D 鉴别器
# -*- coding: utf-8 -*-
"""
Created on Mon Apr 1 13:48:33 2024
@author: chengxf2
"""
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.optim import lr_scheduler
from torchsummary import summary
###############################################################################
# Helper Functions
###############################################################################
class Identity(nn.Module):
def forward(self, x):
return x
def init_weights(net, init_type='normal', init_gain=0.02):
"""Initialize network weights.
Parameters:
net (network) -- network to be initialized
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
We use 'normal' in the original pix2pix and CycleGAN paper. But xavier and kaiming might
work better for some applications. Feel free to try yourself.
"""
def init_func(m): # define the initialization function
classname = m.__class__.__name__
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
if init_type == 'normal':
init.normal_(m.weight.data, 0.0, init_gain)
elif init_type == 'xavier':
init.xavier_normal_(m.weight.data, gain=init_gain)
elif init_type == 'kaiming':
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
init.orthogonal_(m.weight.data, gain=init_gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif classname.find('BatchNorm2d') != -1: # BatchNorm Layer's weight is not a matrix; only normal distribution applies.
init.normal_(m.weight.data, 1.0, init_gain)
init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func) # apply the initialization function <init_func>
def get_norm_layer(norm_type='instance'):
"""Return a normalization layer
Parameters:
affine:
代表gamma,beta是否可学。如果设为True,代表两个参数是通过学习得到的;
如果设为False,代表两个参数是固定值,默认情况下,gamma是1,beta是0。
track_running_stats:
BatchNorm2d中存储的的均值和方差是否需要更新,若为True,表示需要更新;
反之不需要更新。更新公式参考momentum参数介绍 。
"""
if norm_type == 'batch':
norm_layer = functools.partial(nn.BatchNorm2d, affine=True, track_running_stats=True)
elif norm_type == 'instance':
norm_layer = functools.partial(nn.InstanceNorm2d, affine=False, track_running_stats=False)
elif norm_type == 'none':
def norm_layer(x):
return Identity()
else:
raise NotImplementedError('normalization layer [%s] is not found' % norm_type)
return norm_layer
def init_net(net, init_type='normal', init_gain=0.02, gpu_ids=[]):
"""Initialize a network: 1. register CPU/GPU device (with multi-GPU support); 2. initialize the network weights
Parameters:
net (network) -- the network to be initialized
init_type (str) -- the name of an initialization method: normal | xavier | kaiming | orthogonal
gain (float) -- scaling factor for normal, xavier and orthogonal.
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
Return an initialized network.
"""
if len(gpu_ids) > 0:
assert(torch.cuda.is_available())
net.to(gpu_ids[0])
net = torch.nn.DataParallel(net, gpu_ids) # multi-GPUs
init_weights(net, init_type, init_gain=init_gain)
return net
class NLayerDiscriminator(nn.Module):
"""Defines a PatchGAN discriminator"""
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
"""Construct a PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the last conv layer
n_layers (int) -- the number of conv layers in the discriminator
norm_layer -- normalization layer
"""
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4
padw = 1
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
self.model = nn.Sequential(*sequence)
def forward(self, input):
"""Standard forward."""
return self.model(input)
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[]):
"""鉴别器
Parameters:
input_nc (3) -- the number of channels in input images
ndf (64) -- the number of filters in the first conv layer
netD ('basic') -- the architecture's name: basic | n_layers | pixel
n_layers_D (3) -- the number of conv layers in the discriminator; effective when netD=='n_layers'
norm ('instance') -- the type of normalization layers used in the network.
i 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









