






通常我们使用kafka direct的方式使用的是没有自定offset的构造函数
val kc = new KafkaCluster(kafkaParams) 完完全全就是kafka的操作了
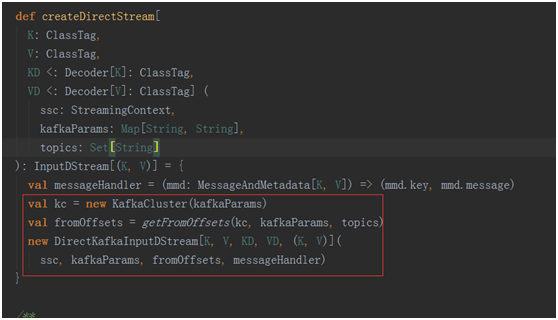
我们看看val fromOffsets = getFromOffsets(kc, kafkaParams, topics)
这是得到消费的起始位置。如果在kafkaParams==kafkaParams的时候会重头开始消费数据。而不等于的时候会从最近最新消费的位置进行消费数据。
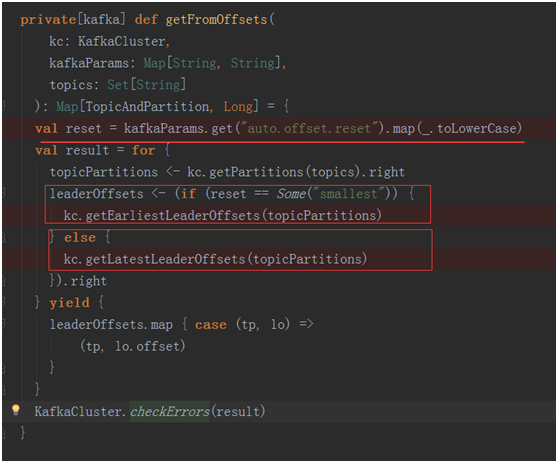
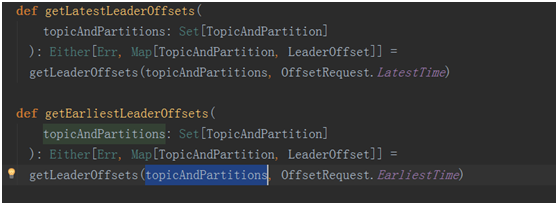
下面是两种处理方式的代码:最终返回fromOffsets
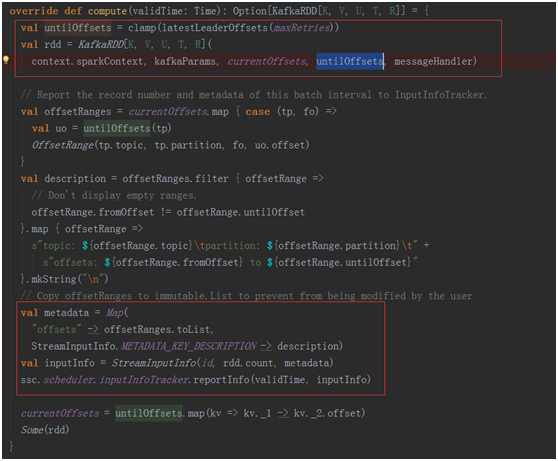
接下来实例化了DirectKafkaInputDStream

看看最重要的compute 方法: 获得了 offset的结束,然后创建了KafkaRDD。
在将相关信息汇报给Taker。最终返回Some(rdd)
Direct方式的好处:
没缓存,就没内存溢出。
Receiver方式会和Worker的Executor绑定,不方便做分布式(当然已有技巧做到分布式了)。RDD的Direct方式可以容易地做到分布式。
Receiver方式在数据来不及及时处理而持续延时下去的话,Spark Streaming就有可能崩溃。Direct方式则不会出现这种情况,因为延迟了,就不会做后面的处理。
完全的语义一致性,确保数据一定会消费,而且不会重复消费。
Direct方式比Receiver方式性能高。
根据自己的InputDStream进行配置,可以设置很多DStream。
backpressure参数很先进。可以试探流进来的速度和当前的处理能力是否一致。如果不一致可以动态调整资源。
















 680
680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









