







一、官方文档翻译
Streaming从Kafka中接收数据,有两种方式:1). 使用Receivers和Kafka高层次的API;2). 基于Direct API(Spark 1.3开始引入的。这两种方式有不同的编程模型,性能特点和语义担保。
1. 基于Receiver方式:
这种方法通过Receiver来接收数据。Receiver是通过使用kafka的high-level Consumer API来实现的。对于所有的Receivers,从Kafka中获取的数据存储在Spark Executor的内存中,然后由park Streaming启动的job来处理这些数据。
然而,在默认的配置下,这种方式可能会在失败的情况下丢失数据,为了保证数据零丢失,你必须在Spark Streaming中启用预写日志机制(Write Ahead Log,WAL),Spark 1.2开始引入的,该机制会同步地将接收到的Kafka数据写入分布式文件系统(例如HDFS)的WAL中,所以失败的时候可以从WAL中恢复。
2. 基于Direct方式:
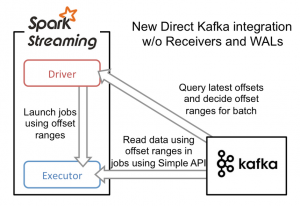
和基于Receiver方法接收数据不一样,这种方式定期地从Kafka获取每个topic+partition的最新偏移量,从而定义出在每个batch里面要处理的数据的偏移量范围。当启动job去处理数据时,就会根据偏移量范围使用kafka的simple consumer API从kafka中读取数据(类似于从一个文件系统中读文件)。
与基于Receiver方式相比,有如下优点:
1). 简单并行。不需要创建多个input Kafka streams然后再对它们进行union操作。通过使用directStream,Spark Streaming会创建和Kafka partition相同数目的RDD partition,并且是并行地从Kafka中读取数据。所以在Kafka partition和RDD partition之间有一一对应的关系,这样更易于理解和调优。
2). 高效。为了保证数据零丢失,基于receiver的方式需要把数据存储在WAL中,这样就需要进一步复制数据。这种方式其实效率不高,因为数据实际上被复制了两份:一次被kafka复制,另一次被复制到WAL中。每二种方式因为没有receiver,没有必要WAL,从而不存在这样的问题。
3). 恰好一次语义(Exactly-once semantics)。每一种方式使用Kafka的high-level Consumer API将偏移量保存在zookeeper中,这是从kafka中消费数据的传统方法。虽然这种方法(结合WAL)可以保证数据零丢失,但是还会存在在失败的情况下数据被消费两次的可能。这种情况发生是因为SparkStreaming可靠地接收到的数据和zookeeper中存储的偏移量之间的不一致。因此,在第二种方式中,我们使用simple Kafka API,不需要使用zookeeper。偏移量仅仅被Spark Streaming保存在Checkpoint中,这就消除了Spark Streaming和zookeeper/kafka的不同步,保证了即使在失败情况下,每条记录也能被消费一次且仅一次。
需要注意的是,这种方法不会将消费的偏移量更新到Zookeeper中,导致那些基于zookeeer偏移量的Kafka监控工具(比如:Apache Kafka监控之Kafka Web Console、Apache Kafka监控之KafkaOffsetMonitor等)失效。但是,你可以获取到每个batch的偏移量然后自己手动更新zookeeper。
二、系统构建角度
从高层次的角度看,第一种方式和Kafka集成方案使用WAL工作方式如下:
1、运行在Spark workers/executors上的Kafka Receivers连续不断地从Kafka中读取数据,其中用到了Kafka中高层次的消费者API。
2、接收到的数据被存储在Spark workers/executors中的内存,同时也被写入到WAL中。只有接收到的数据被持久化到log中,Kafka Receivers才会去更新Zookeeper中Kafka的偏移量。
3、接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
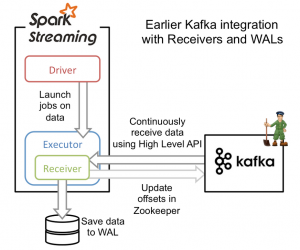
第一种方法可以保证从Kafka接收的数据不被丢失。但是在失败的情况下,有些数据很有可能会被处理不止一次!这种情况在一些接收到的数据被可靠地保存到WAL中,但是还没有来得及更新Zookeeper中Kafka偏移量,系统出现故障的情况下发生。这导致数据出现不一致性:Spark Streaming知道数据被接收,但是Kafka那边认为数据还没有被接收,这样在系统恢复正常时,Kafka会再一次发送这些数据。
这种不一致产生的原因是因为两个系统无法对那些已经接收到的数据信息保存进行原子操作。为了解决这个问题,只需要一个系统来维护那些已经发送或接收的一致性视图,而且,这个系统需要拥有从失败中恢复的一切控制权利。基于这些考虑,社区决定将所有的消费偏移量信息只存储在Spark Streaming中,并且使用Kafka的低层次消费者API来从任意位置恢复数据。
为了构建这个系统,新引入的Direct API采用完全不同于Receivers和WALs的处理方式。它不是启动一个Receivers来连续不断地从Kafka中接收数据并写入到WAL中,而且简单地给出每个batch区间需要读取的偏移量位置,最后,每个batch的Job被运行,那些对应偏移量的数据在Kafka中已经准备好了。这些偏移量信息也被可靠地存储(checkpoint),在从失败中恢复可以直接读取这些偏移量信息。
需要注意的是,Spark Streaming可以在失败以后重新从Kafka中读取并处理那些数据段。然而,由于仅处理一次的语义,最后重新处理的结果和没有失败处理的结果是一致的。
因此,Direct API消除了需要使用WAL和Receivers的情况,而且确保每个Kafka记录仅被接收一次并被高效地接收。这就使得我们可以将Spark Streaming和Kafka很好地整合在一起。总体来说,这些特性使得流处理管道拥有高容错性,高效性,而且很容易地被使用。
三、基于Direct方式源码解析
本文主要解读基于Direct方式的源码,基于Receiver方式以后会再详细分析。
实质上讲Direct方式直接操作数据来源,更符合我们操作数据的思路,操作数据就要有个封装器,这个封装器是RDD类型,SparkStreaming为了封装数据推出了自定义的RDD–KafkaRDD。SparkStreaming直接操作Kafka集群,brokers指kafka集群,messageHandler指怎么操作数据。
/**
* A batch-oriented interface for consuming from Kafka.
* Starting and ending offsets are specified in advance,
* so that you can control exactly-once semantics.
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>. Requires "metadata.broker.list" or "bootstrap.servers" to be set
* with Kafka broker(s) specified in host1:port1,host2:port2 form.
* @param offsetRanges offset ranges that define the Kafka data belonging to this RDD
* @param messageHandler function for translating each message into the desired type
*/
private[kafka]
class KafkaRDD[
K: ClassTag,
V: ClassTag,
U <: Decoder[_]: ClassTag,
T <: Decoder[_]: ClassTag,
R: ClassTag] private[spark] (
sc: SparkContext,
kafkaParams: Map[String, String],
val offsetRanges: Array[OffsetRange],
leaders: Map[TopicAndPartition, (String, Int)],
messageHandler: MessageAndMetadata[K, V] => R
) extends RDD[R](sc, Nil) with Logging with HasOffsetRanges {
override def getPartitions: Array[Partition] = {
offsetRanges.zipWithIndex.map { case (o, i) =>
val (host, port) = leaders(TopicAndPartition(o.topic, o.partition))
new KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset, host, port)
}.toArray
}KafkaRDD混入了trait HasOffsetRanges, RDD是partion的list,HasOffsetRanges里面有成员offsetRanges,是Array[offsetRange]类型
foreachRDD中就可以获得当前batchDuration中RDD的partion的数据,这就是参源数据的控制
/**
* Represents any object that has a collection of [[OffsetRange]]s. This can be used to access the
* offset ranges in RDDs generated by the direct Kafka DStream (see
* [[KafkaUtils.createDirectStream()]]).
* {{{
* KafkaUtils.createDirectStream(...).foreachRDD { rdd =>
* val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
* ...
* }
* }}}
*/
trait HasOffsetRanges {
def offsetRanges: Array[OffsetRange]
}offsetRange代表数据,所以一定可以被虚拟化,TopicAndPartition是一个case class
/**
* Represents a range of offsets from a single Kafka TopicAndPartition. Instances of this class
* can be created with `OffsetRange.create()`.
* @param topic Kafka topic name
* @param partition Kafka partition id
* @param fromOffset Inclusive starting offset
* @param untilOffset Exclusive ending offset
*/
final class OffsetRange private(
val topic: String,
val partition: Int,
val fromOffset: Long,
val untilOffset: Long) extends Serializable {
import OffsetRange.OffsetRangeTuple
/** Kafka TopicAndPartition object, for convenience */
def topicAndPartition(): TopicAndPartition = TopicAndPartition(topic, partition)
/** Number of messages this OffsetRange refers to */
def count(): Long = untilOffset - fromOffset
override def equals(obj: Any): Boolean = obj match {
case that: OffsetRange =>
this.topic == that.topic &&
this.partition == that.partition &&
this.fromOffset == that.fromOffset &&
this.untilOffset == that.untilOffset
case _ => false
}伴生对象创建OffsetRange对象
/**
* Companion object the provides methods to create instances of [[OffsetRange]].
*/
object OffsetRange {
def create(topic: String, partition: Int, fromOffset: Long, untilOffset: Long): OffsetRange =
new OffsetRange(topic, partition, fromOffset, untilOffset)KafkaRDD中关键方法getPartitions,通过offsetRanges返回partitions, case (o, i)匹配
override def getPartitions: Array[Partition] = {
offsetRanges.zipWithIndex.map { case (o, i) =>
val (host, port) = leaders(TopicAndPartition(o.topic, o.partition))
new KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset, host, port)
}.toArrayKafkaRDD中compute计算分片
override def compute(thePart: Partition, context: TaskContext): Iterator[R] = {
val part = thePart.asInstanceOf[KafkaRDDPartition]
assert(part.fromOffset <= part.untilOffset, errBeginAfterEnd(part))
if (part.fromOffset == part.untilOffset) {
log.info(s"Beginning offset ${part.fromOffset} is the same as ending offset " +
s"skipping ${part.topic} ${part.partition}")
Iterator.empty
} else {
new KafkaRDDIterator(part, context)
}
}KafkaRDDIterator中根据kafkaParams构建出kafkaCluster
private class KafkaRDDIterator(
part: KafkaRDDPartition,
context: TaskContext) extends NextIterator[R] {
context.addTaskCompletionListener{ context => closeIfNeeded() }
log.info(s"Computing topic ${part.topic}, partition ${part.partition} " +
s"offsets ${part.fromOffset} -> ${part.untilOffset}")
val kc = new KafkaCluster(kafkaParams)
val keyDecoder = classTag[U].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(kc.config.props)
.asInstanceOf[Decoder[K]]
val valueDecoder = classTag[T].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(kc.config.props)
.asInstanceOf[Decoder[V]]
val consumer = connectLeader
var requestOffset = part.fromOffset
var iter: Iterator[MessageAndOffset] = nullkafkaCluster封装了与kafka集群的交互,connect的时候用SimpleConsumer
private[spark]
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
import KafkaCluster.{Err, LeaderOffset, SimpleConsumerConfig}
...
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)下面,从我们自己的程序调用KafkaUtils.createDirectStream入口,在创建DirectDstream的时候会和kafka cluster交互,getFromOffsets获取具体的偏移量,无论DirectKafkaInputDStream怎么重载,最终返回的都是DirectKafkaInputDStream
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]: ClassTag,
VD <: Decoder[V]: ClassTag] (
ssc: StreamingContext,
kafkaParams: Map[String, String],
topics: Set[String]
): InputDStream[(K, V)] = {
val messageHandler = (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message)
val kc = new KafkaCluster(kafkaParams)
val fromOffsets = getFromOffsets(kc, kafkaParams, topics)
new DirectKafkaInputDStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, fromOffsets, messageHandler)
}如果不指定offeset,且auto.offset.reset为true,则从头开始读
private[kafka] def getFromOffsets(
kc: KafkaCluster,
kafkaParams: Map[String, String],
topics: Set[String]
): Map[TopicAndPartition, Long] = {
val reset = kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
val result = for {
topicPartitions <- kc.getPartitions(topics).right
leaderOffsets <- (if (reset == Some("smallest")) {
kc.getEarliestLeaderOffsets(topicPartitions)
} else {
kc.getLatestLeaderOffsets(topicPartitions)
}).right
} yield {
leaderOffsets.map { case (tp, lo) =>
(tp, lo.offset)
}
}
KafkaCluster.checkErrors(result)
}每一个RDD partition对应一个kafka Partition, spark.streaming.kafka.maxRatePerPartition可以配置消费速度
/**
* A stream of {@link org.apache.spark.streaming.kafka.KafkaRDD} where
* each given Kafka topic/partition corresponds to an RDD partition.
* The spark configuration spark.streaming.kafka.maxRatePerPartition gives the maximum number
* of messages
* per second that each '''partition''' will accept.
* Starting offsets are specified in advance,
* and this DStream is not responsible for committing offsets,
* so that you can control exactly-once semantics.
* For an easy interface to Kafka-managed offsets,
* see {@link org.apache.spark.streaming.kafka.KafkaCluster}
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>.
* Requires "metadata.broker.list" or "bootstrap.servers" to be set with Kafka broker(s),
* NOT zookeeper servers, specified in host1:port1,host2:port2 form.
* @param fromOffsets per-topic/partition Kafka offsets defining the (inclusive)
* starting point of the stream
* @param messageHandler function for translating each message into the desired type
*/
private[streaming]
class DirectKafkaInputDStream[其中compute方法中,untiloffsets确定需要获取数据的区间,从而知道要计算多少条数据。DirectKafkaInputDStream每次compute的时候会构建KafkaRDD实例,在一个batch duration中每个DirectKafkaInputDStream都会构建出一个KafkaRDD实例,所以KafkaRDD的实例和DirectKafkaInputDStream是一一对应的。
override def compute(validTime: Time): Option[KafkaRDD[K, V, U, T, R]] = {
val untilOffsets = clamp(latestLeaderOffsets(maxRetries))
val rdd = KafkaRDD[K, V, U, T, R](
context.sparkContext, kafkaParams, currentOffsets, untilOffsets, messageHandler)
// Report the record number and metadata of this batch interval to InputInfoTracker.
val offsetRanges = currentOffsets.map { case (tp, fo) =>
val uo = untilOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo.offset)
}读取数据的时候从KafkaRDD的角度来看,一个KafkaRDDIterator对应一个KafkaRDDPartition,获取数据的过程是lazy级别,有action触发才会真正读取
private class KafkaRDDIterator(
part: KafkaRDDPartition,
context: TaskContext) extends NextIterator[R] {direct方式优点:1,没有缓存,不会出现内存溢出;2, receiver方式与具体的worker/excutor绑定,不方便做分布式(需要配置),direct方式默认会在多个executor上,因为KafkaRDD默认是在多个executor上的; 3,消费的时候Receiver方式如果数据来不及处理,可能会因为来不及消费导致SparkStreaming程序崩溃,而direct方式直接读取kafka数据,delay时就不进行下一个处理;4,完全的语义一致性。
在实际项目中,推荐使用Direct方式。















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









