







本讲内容:
a. Direct Acess
b. Kafka
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾
上一讲中,我们讲Spark Streaming中一个非常重要的内容:State状态管理
a. 为了说明state状态管理,拿两个非常具体非常有价值的方法updateStateByKey和mapWithState这两个方法来说明sparkstreaming是如何实现对state状态管理的。Sparkstreaming是按照batchduration划分job的,但是有时我们想算过去一个小时或者过去一天的数据,在大于batchduration的时候对数据进行符合业务逻辑的操作,这时候不可避免的要进行状态维护。Sparkstreaming每个batchduration都会产生一个job,job里面都是RDD,所以现在面临的一个问题就是,他每个batchduration产生RDD,怎么对他的状态进行维护的问题(像updateStateByKey)。例如计算一天的商品的点击量,这时候就需要类似于updateStateByKey或者mapWithState这样的方法帮助完成核心的步骤
b. Spark 的状态管理其实有很多函数,比较典型的有类似的UpdateStateByKey、MapWithState方法来完成核心的步骤
updateStateByKey和mapWithState这两个方法在DStream中并不能找到。因为updateStateByKey和mapWithState这两个方法都是针对key-value类型的数据进行操作,也就是pair类型的,和前边讲RDD是一样的,RDD这个类本事并不会对key-value类型的数据进行操作,所以这时候就需要借助scala的语法隐式转换。隐式转换一般放在类的伴生对象中,将DStream转换成PairDStreamFunctions。这是从地狱中召唤出来的功能,使用后又回到地狱。运行机制就是找不到DStream的updateStateByKey和mapWithState,他们是PairDStreamFunctions的方法,就找隐式转换,隐式转换中发现toPairDStreamFunctions这个功能,就使用了implicit功能
最后我们附上代码执行流程图:
(来源:http://blog.csdn.net/hanburgud/article/details/51545414,感谢作者)

开讲
上一讲中主要是使用ReceiverInputDStream,是针对Receiver方式开展的剖析
本讲我们之所以用一节课来讲No Receivers,是因为企业级Spark Streaming应用程序开发中在越来越多的采用No Receivers的方式。No Receiver方式有自己的优势,比如更大的控制的自由度、语义一致性等等。所以对No Receivers方式和Receiver方式都需要进一步研究、思考
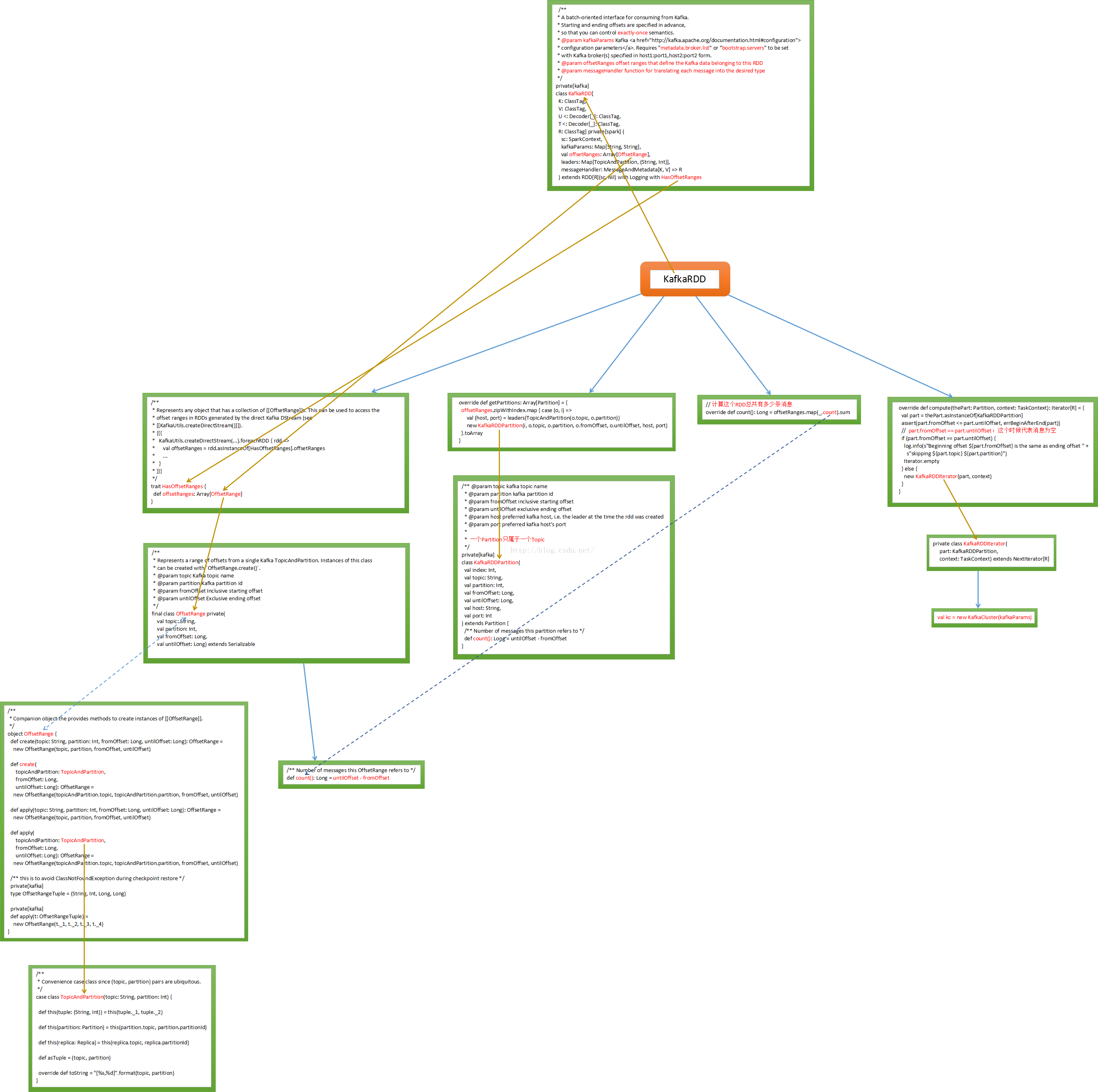
Spark Streaming现在支持两个方式,一种是Receivers的方式来接收数据的输入或者对数据的控制,另一种是No Receivers的方式,也就是directAPI。其实No Receivers的方式是更符合读取数据和操作数据的思路的,因为Spark是一个计算框架,作为一个计算框架底层会有数据来源,如果用No Receivers的方式直接操作数据来源中的数据,这是更自然的一种方式。如果要操作数据来源肯定要有一个封装器,封装器肯定是RDD类型的,所以SparkStreaming为了封装数据推出了一个自定义的RDD叫KafkaRDD
从Kafka中消费数据的一种实现,首先要确定开始和结束的offset来保证exactly-once。
kafkaParams 中最关键的是metadata.broker.list,这个broker是kafka中的概念。就是SparkStreaming直接去操作kafka集群,offsetRanges指的是哪一片数据是这个RDD的。Kafka传数据的时候会进行编码所以需要Decoder。直接从kafka中读取数据需要自定义一个RDD,如果想从Hbase中直接读数据也需要自定义RDD
所以Spark Streaming就产生了自定义RDD –> KafkaRDD
源码分析:
走进KafkaRDD开始探秘之旅
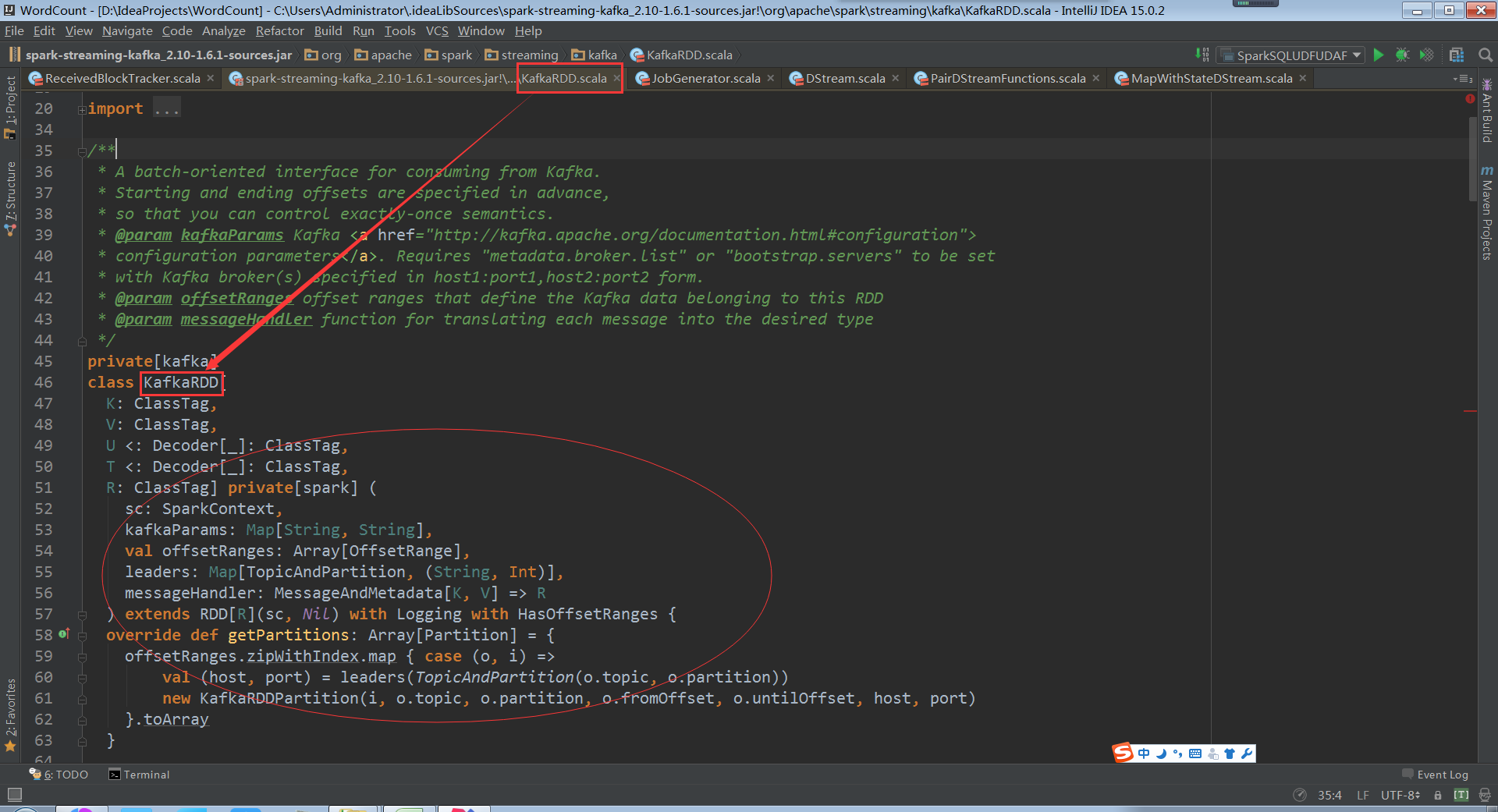
KafkaRDD在继承RDD的时候也继承了HasOffsetOranges,这个是必须的,因为RDD天然的是a list of partitions,基于kafka直接访问RDD时必须是HasOffsetRange类型,代表了来自kafka topicAndParttion,其实力被HasOffsetRange Create创建,从fromOffset到untilOffset ,
分布式传输Offset数据时必须序列化
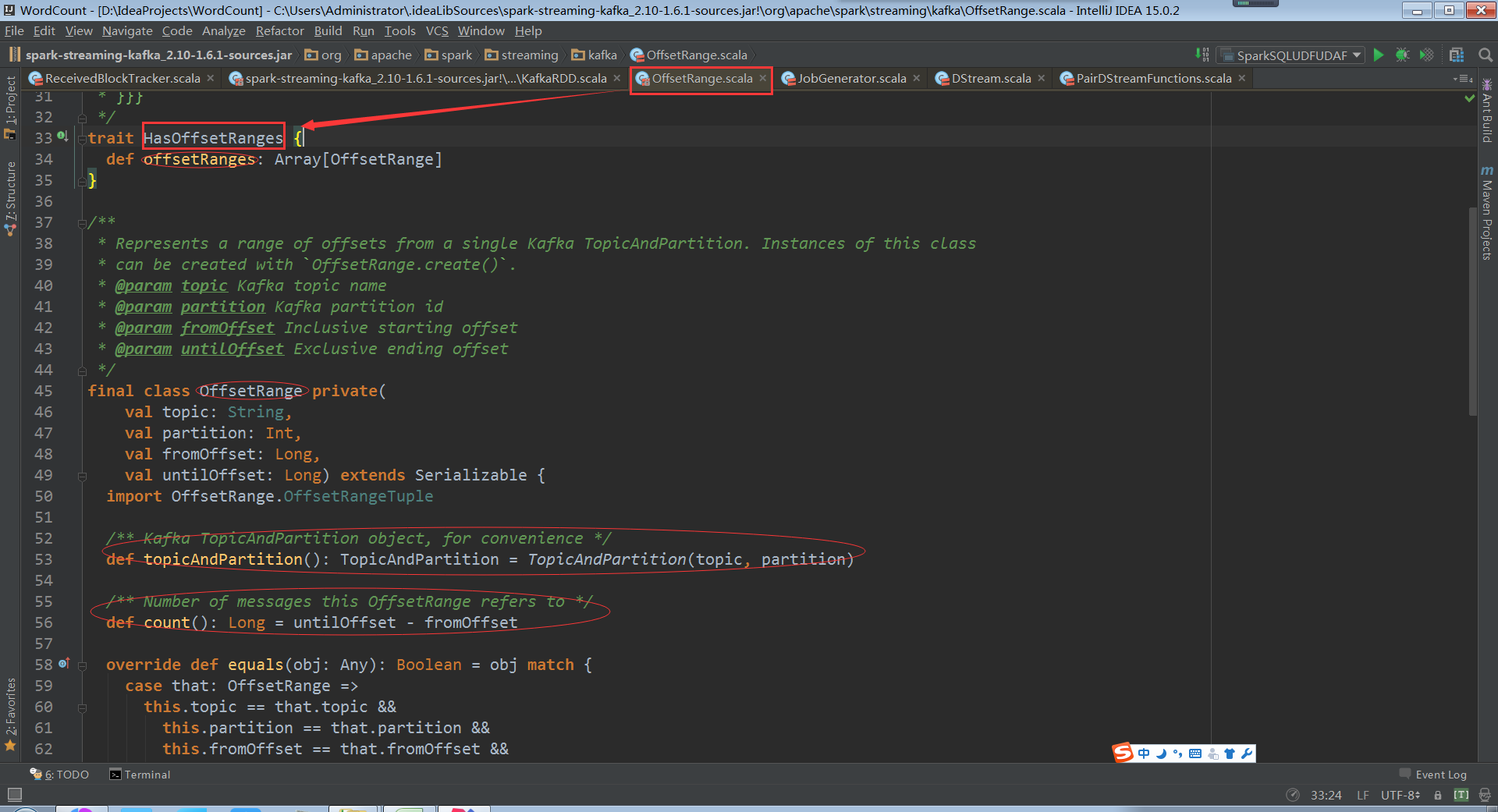
Offset是消息偏移量,假设untilOffset是10万,fromOffset是5万,第10万条消息和5万条消息,一般处理数据规模大小是以数据条数为单位
创建一个offSetrange实例时可以确定从kafka集群partition中读取哪些topic,从foreachrdd中可以获得当前rdd访问的所有分区数据。Batch Duration中产生的rdd的分区数据,这个是对元数据的控制
再看getPartitions方法,offsetRanges指定了每个offsetrange从什么位置开始到什么位置结束
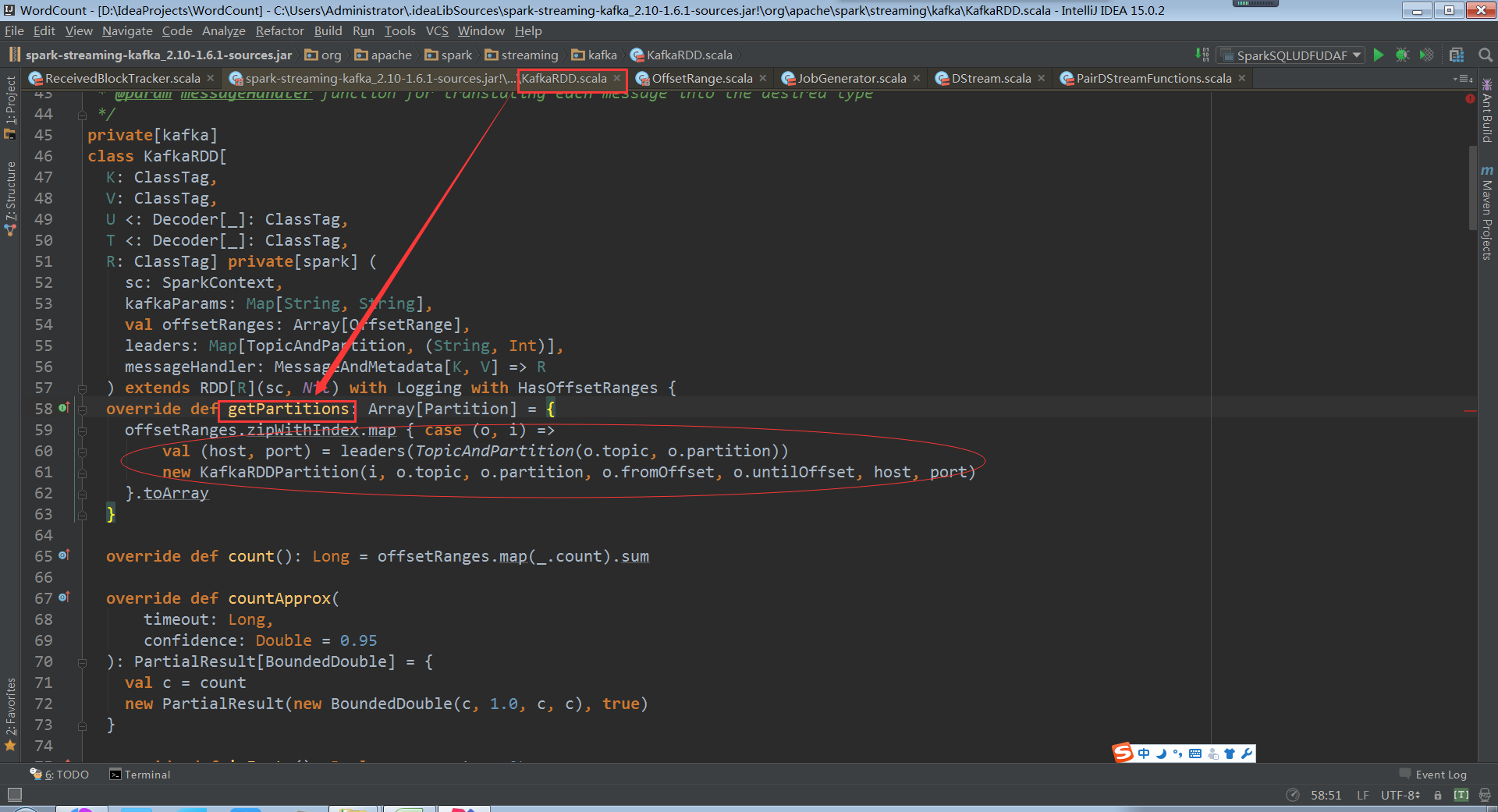
看KafkaRDDPartition类,会从传入的topic和partition及offset中获取kafka数据
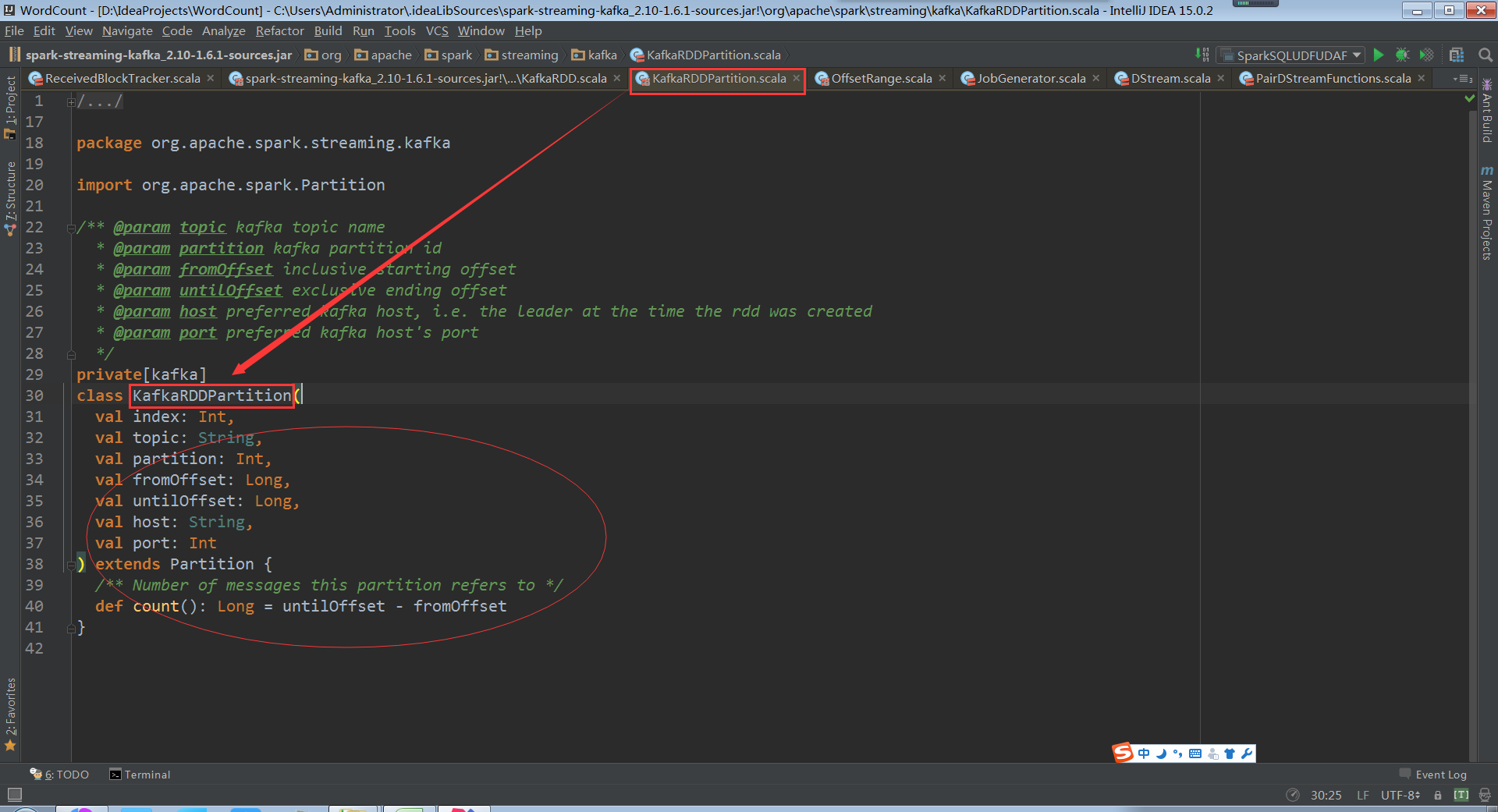
Host port指定读取数据来源的kfakf机器
看kafka rdd的compute计算每个数据分片,和rdd理念是一样的,每次迭代操作获取计算的rdd一部分
操作KafkaRDDIterator和操作rdd分片是一样的,需要迭代数据分片
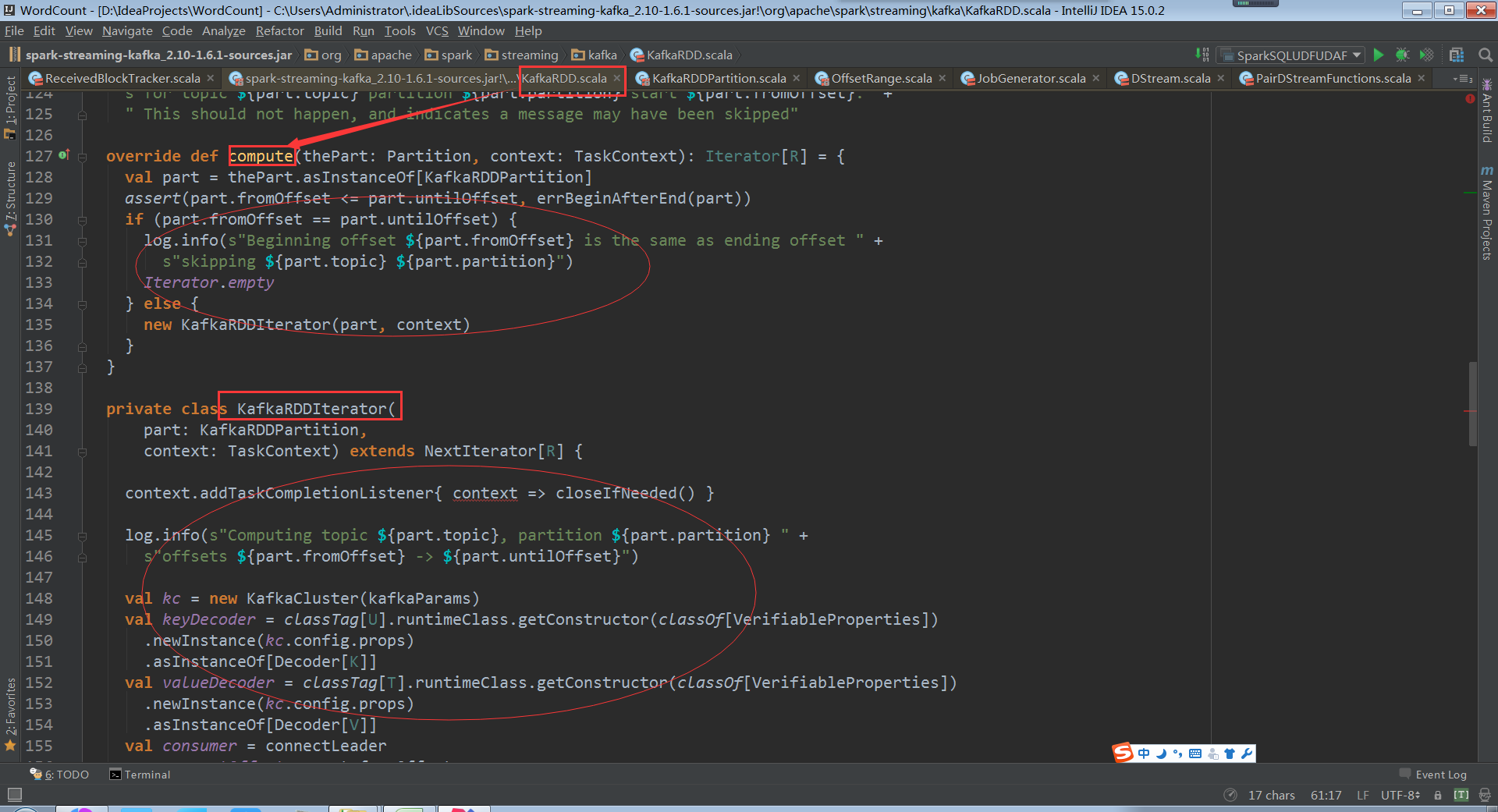
关键的地方kafkaCluster对象时在kafkaUtils中直接创建了directStream,看下之前操作kafka代码发现传入的参数是上下文、 broker.List.topic.list参数
构建时传入topics为Set,当然可以直接指定ranges,他从kafka集群直接创建了kafkaCluster和集群进行交互,从fromOffset获取数据具体的偏移量
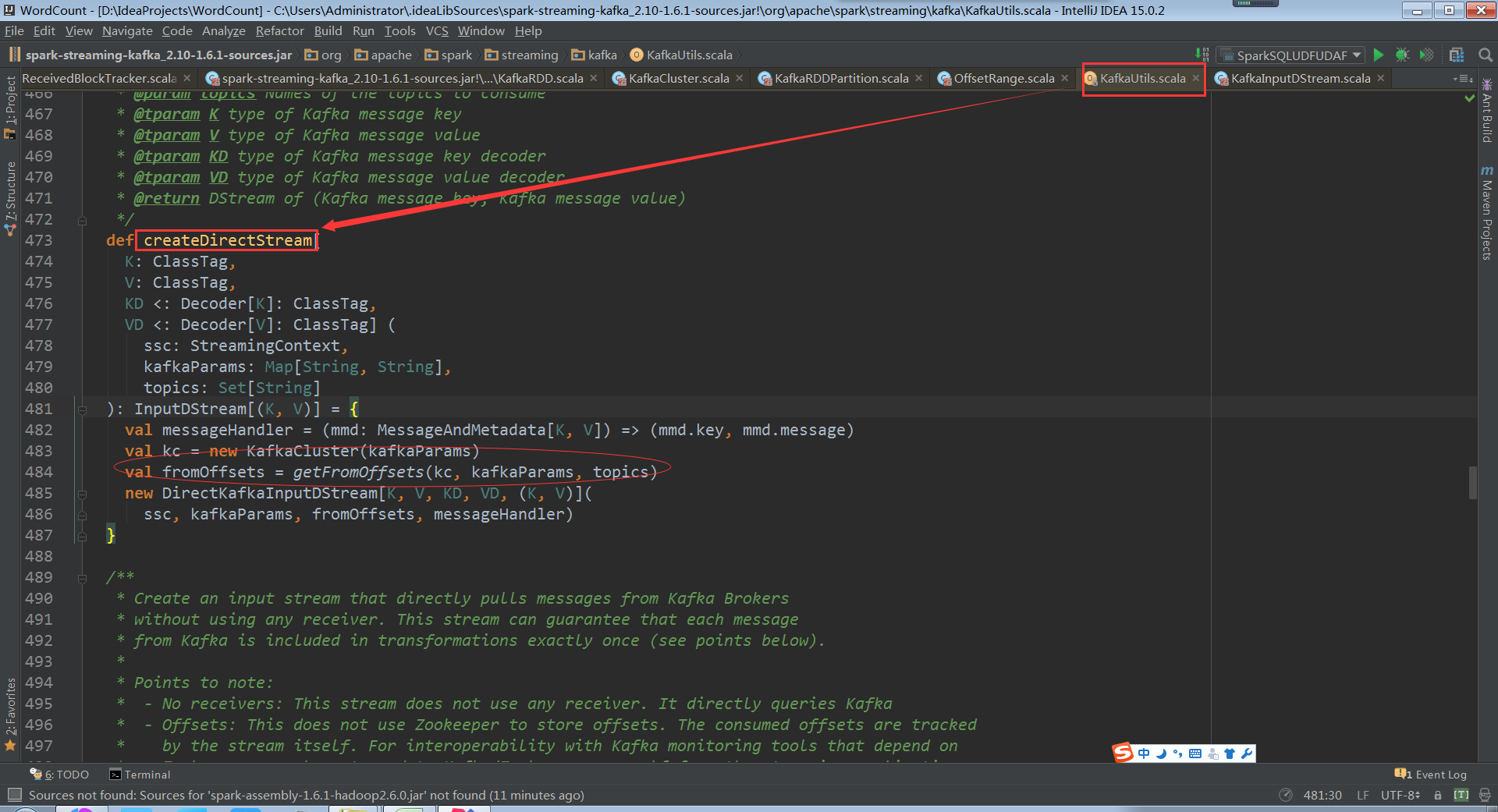
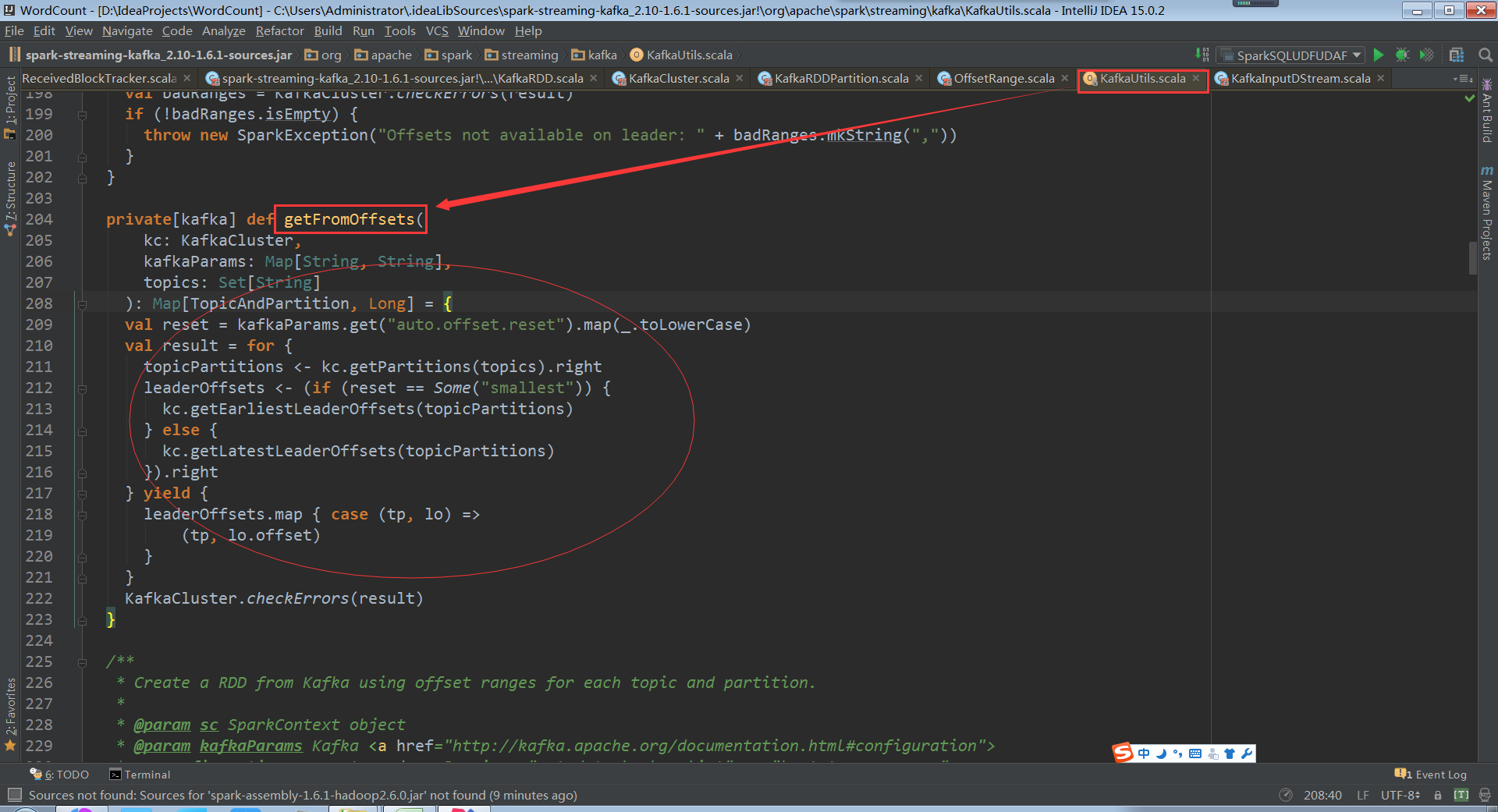
如果不知道fromOffsets的话直接从配置中获取fromOffsets,创建kafka DirectKafkaInputDStream的时候会从kafka集群进行交互获得partition、offset信息,通过DirectKafkaInputDStream无论什么情况最后都会创建DirectKafkaInputDStream
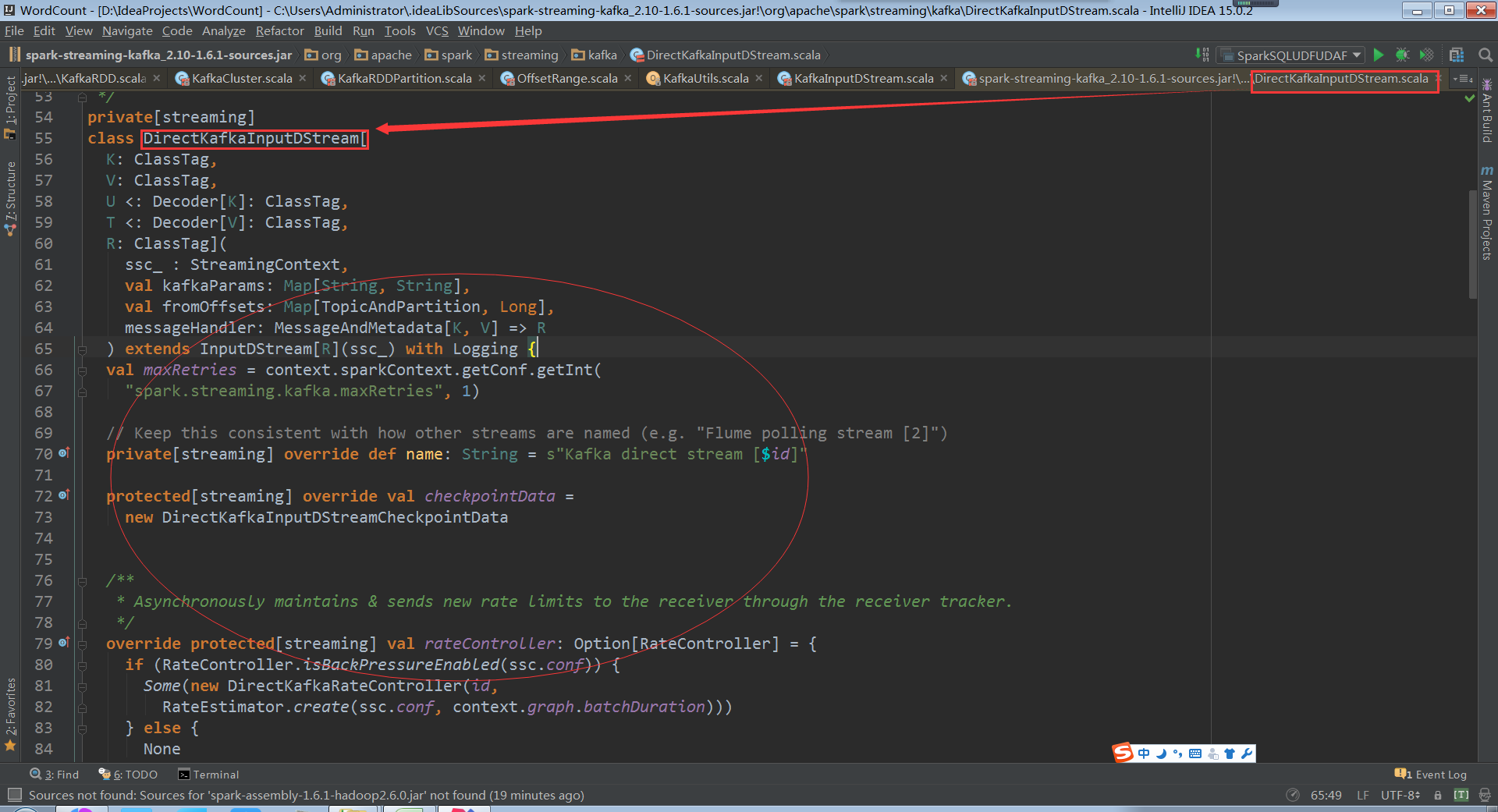
DirectKafkaInputDStream会产生kafkaRDD,不同的topic partitions生成对应的的kafkarddpartitions,控制消费读取速度。操作数据的时候是compute直接构建出kafka rdd,读取kafka 上的数据。确定获取读取数据的期间就知道需要读取多少条数据,然后构建kafkardd实例。Kafkardd的实例和DirectKafkaInputDStream是一一对应的,每次compute会产生一个kafkardd,其会包含很多partitions,有多少partition就是对应多少kafkapartition
看下KafkaRDDPartition就是一个简单的数据结构
总结:
而且KafkaRDDPartition只能属于一个topic,不能让partition跨多个topic,直接消费一个kafkatopic,topic不断进来、数据不断偏移,Offset代表kafka数据偏移量指针。
数据不断流进kafka,batchDuration假如每十秒都会从配置的topic中消费数据,每次会消费一部分直到消费完,下一个batchDuration会再流进来的数据,又可以从头开始读或上一个数据的基础上读取数据。
Direct的方式相比Receivers的方式的优势:
a. Direct的方式没有缓存,也就不用担心出现内存溢出的问题。如果是Receivers的方式就存在缓存
b. 如果是Receivers的方式,Receivers是和具体的worker绑定,Receivers的方式不方便做分布式,当然配置一下是可以做分布式的。Direct的方式默认数据就会在多个executor上
c. 数据消费的问题,我们在实际操作的时候,如果是Receivers的方式假如数据来不及处理,数据操作delazy之后,delazy多次的话,sparkstreaming程序就会崩溃。如果是Direct的方式就不存在这种情况
d. Direct的方式完全的语义一致性。不会重复消费,并且确保数据一定被消费。Direct的方式是和kafka进行交互,只有数据被真正的执行成功才会被记录下来
e. Direct的方式比Receivers的方式速度快。对Direct的方式数据流进的速度的配置是对每个partition进行配置
f. Sparkstreaming还有一个配置是backpressure,这个参数可以试探一下数据流进来的速度和处理能力是否一致,如果处理不一致可以动态的进行调整,也就是资源的动态调整
生产环境下强烈建议采用direct方式读取kafka数据
Kafka Direct方式的代码执行流程的源码和重要代码流程图
来源:http://blog.csdn.net/hanburgud/article/details/51545691,感谢作者















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









