








View Independent Vehicle Make, Model and Color Recognition Using Convolutional Neural Network
Afshin Dehghan, Syed Zain Masood, Guang Shu, Enrique. G. Ortiz
Computer Vision Lab, Sighthound Inc., Winter Park, FL
Winter Park is a suburban city in Orange County, Florida, United States.
Abstract
This paper describes the details of Sighthound’s fully automated vehicle make, model and color recognition system. The backbone of our system is a deep convolutional neural network that is not only computationally inexpensive, but also provides state-of-the-art results on several competitive benchmarks. Additionally, our deep network is trained on a large dataset of several million images which are labeled through a semi-automated process. Finally we test our system on several public datasets as well as our own internal test dataset. Our results show that we outperform other methods on all benchmarks by significant margins. Our model is available to developers through the Sighthound Cloud API at https://www.sighthound.com/products/cloud
1. Introduction
Make, model and color recognition (MMCR) of vehicles [1,2,3] is of great interest in several applications such as law-enforcement, driver assistance, surveillance and traffic monitoring. This fine-grained visual classification task [4,5,6,7,8,9] has been traditionally a difficult task for computers. The main challenge is the subtle differences between classes (e.g BMW 3 series and BMW 5 series) compared to some traditional classification tasks such as ImageNet. Recently, there have been efforts to design more accurate algorithms for MMCR such as those in the works of Sochor et al in [1] and Hsieh et al [2]. Moreover, many researchers have focused on collecting large datasets to facilitate research in this area [4]. However, the complexity of current methods and/or the small size of current datasets lead to sub-optimal performance in real world use cases. Thus, there are still considerable short-comings for agencies or commercial entities looking to deploy reliable software for the task of MMCR. In this paper, we present a system that is capable of detecting and tagging the make, model and color of vehicles irrespective of viewing angle with high accuracy. Our model is trained to recognize 59 different vehicle makes as well as 818 different models in what we believe is the largest set available for commercial or non commercial use.1
law-enforcement:执法
fine-grained:adj. 细粒的,有细密纹理的 adj. 详细的,深入的
subtle ['sʌt(ə)l]:adj. 微妙的,精细的,敏感的,狡猾的,稀薄的
sub-optimal/:adj. 次佳的
irrespective [ɪrɪ'spektɪv]:adj. 无关的,不考虑的,不顾的
1Our system covers almost all popular models in North America.
The contributions of Sighthound’s vehicle MMCR system are listed as follows:
- To date, we have collected what we believe to be the largest vehicle dataset, consisting of more than 3 million images labeled with corresponding vehicle make and model. Additionally, we labeled part of this data with corresponding labels for vehicle color.
- We propose a semi-automated method for annotating several million vehicle images.
- We present an end-to-end pipeline, along with a novel deep network, that not only is computationally inexpensive, but also outperforms competitive methods on several benchmarks.
- We conducted a number of experiments on existing benchmarks and obtained state-of-the-art results on all of them.
2 System Overview
The overview of our system is shown in Figure 1. Our training consists of a 3-stage processing pipeline including data collection, data pre-processing and deep training. Data collection plays an important role in our final results, thus collecting data, which requires the least effort in labeling, is of great importance. We collected a large dataset with two different sets of annotations. All the images are annotated with their corresponding vehicle make and model and part of the data is annotated with vehicle colors2. In order to prepare the final training data we further process the images to eliminate the effect of background. Finally these images are fed into two separate deep neural networks to train the final model.
2Please note the number of color categories is far less than number of vehicle models
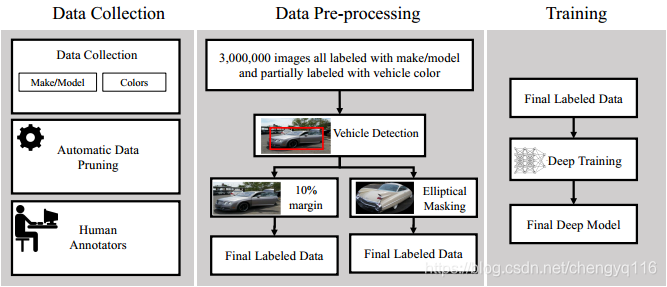
Fig. 1. This figure shows the pipeline of our system. Images are collected from different sources. They are later pruned using a semi-automated process with a team of human annotators in the loop. The images are passed through Sighthound’s vehicle detector and steps are taken to align them. The images are then fed to our proprietary deep network for training.
elliptical [ɪ'lɪptɪk(ə)l]:adj. 椭圆的,省略的
3 Training
Below we describe in more detail different components of our 3-stage training procedure.
-
Data Collection: Data collection plays an important role in training any deep neural network, especially when it comes to fine-grained classification tasks. To address this issue we collected the largest vehicle dataset known to date, where each image is labeled with corresponding make and model of the vehicle. We initially collected over 5 million images from various sources. We developed a semi-automated process to partially prune the data and remove the undesired images. We finally used a team of human annotators to remove any remaining errors from the dataset. The final set of data contains over 3 million images of vehicles with their corresponding make and model tags. Additionally, we labeled part of this data with the corresponding color of the vehicle, chosen from a set of 10 colors; blue, black, beige, red, white, yellow, orange, purple, green and gray.
-
Data Pre-processing: An important step in our training is alignment. In order to align images such that all the labeled vehicles are centered in the image, we used Sighthound’s vehicle detection model available through the Sighthound Cloud API3. Vehicle detection not only helps us align images based on vehicle bounding boxes but also reduces the impact of the background. This is especially important when there is more than one vehicle in the image. Finally we consider a 10% margin around the vehicle box to compensate for inaccurate (or very tight) bounding boxes. For the task of color recognition, we took pains to further eliminate any influence the background may have on the outcome. To achieve this, we further mask the images with an elliptical mask as shown in Figure 1. Note that in certain cases the elliptical mask removes some boundary information of the vehicle. However, this had little effect on the color classification accuracy.
outcome ['aʊtkʌm]:n. 结果,结局,成果
3https://www.sighthound.com/products/cloud
- Deep training: The final stage of our pipeline in Figure 1 involves training two deep neural networks. One is trained to classify vehicles based on their make and model and the other is trained to classify vehicles based on their color. Our networks are designed such that they achieve high accuracy while remaining computationally inexpensive. We trained our networks for four days on four GTX TITAN X PASCAL GPUs. Once the model is trained, we can label images at 150 fps in batch processing mode.
4 Experiments on SIN 2014 Test set
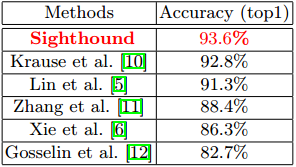
In this section, we report experimental results on two publicly available datasets: the Stanford Cars dataset [10] and the Comprehensive Car (compCar) dataset [4]. The Stanford Cars dataset consists of 196 classes of cars with a total of 16,185 images. The data is divided into almost a 50-50 train/test split with 8,144 training images and 8,041 testing images. Categories are typically at the level of Make, Model, Year. This means that several categories contain the same model of a make, and the only difference is the year that the car is made. Our original model is not trained to classify vehicle models based on the year of their production. However, after fine-tuning our model on the Stanford Cars training data, we observe that we can achieve better results compared to previously published methods. This is mainly due to the sophistication in the design of our proprietary deep neural network as well as the sizable amount of data used to train this network. The quantitative results are shown in Table 1.
sophistication [sə,fɪstɪ'keɪʃn]:n. 复杂,诡辩,老于世故,有教养
Table 1. Top-1 car classification accuracy on Stanford car dataset.
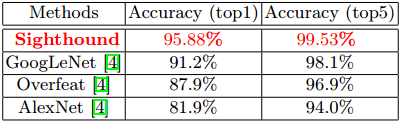
We also report results on the Comprehensive Car dataset which has recently been published. The task here is to classify data into 431 different classes based on vehicle make and model. The data is divided into 70% training and 30% testing. There are a total of 36,456 training images and 15,627 test images. The top-1 and top-5 accuracy are reported in Table 2. We compare our results with the popular deep network architectures reported in [4]. We can clearly see that our fine-tuned model outperforms the existing methods by 4.68% in top-1 accuracy. It is also worth noting that the our model is an order of magnitude faster than GoogLeNet.
Table 2. Top-1 and top-5 car classification accuracy of compCar dataset. We compare our results with popular deep networks of GoogLeNet, Overfeat and AlexNet reported in [4]
Lastly we test the verification accuracy of the proposed method on compCar dataset. The compCar dataset includes three sets of data for verification experiments, sorted by their difficulties. Each set contains 20,000 pairs of images. The likelihood ratio of each image pair is obtained by computing the Euclidean distant between features computed using our the deep network. The likelihood ratio is then compared against a threshold to make the final decision. The results are shown in Table 3. As can be seen our model, fine-tuned on the verification training data of compCar dataset, outperforms other methods. It is worth to mention that, even without fine-tuning our features can achieve a high verification accuracy of 92.03%, 86.52%, 80.17% on different sets of easy, medium and hard respectively.
likelihood ['laɪklɪhʊd];n. 可能性,可能
Table 3. Verification accuracy of three different sets, easy, medium and hard in [4]. Sighthound is our fine-tuned model trained on Sighthound data. It can be seen that the model outperforms previous methods by a large margin.

5 Quantitative Results
We demonstrate some quantitative results in Figures 2 and 3, capturing different scenarios. Figure 2 shows results for images mostly taken by people. Figure 3 shows a surveillance-like scenario where the camera is mounted at a higher distance from the ground. These images are illustrative of the robustness of our large training dataset, captured from different sources, to real world scenarios.

Fig. 2. Quantitative results of the proposed method in surveillance cameras.

Fig. 3. Quantitative results of the proposed method.
6 Conclusions
In this paper we presented an end to end system for vehicle make, model and color recognition. The combination of Sighthound’s novel approach to the design and implementation of deep neural networks and a sizable dataset for training allow us to label vehicles in real time with high degrees of accuracy. We conducted several experiments for both classification and verification tasks on public benchmarks and showed significant improvement over previous methods.
References
A large-scale car dataset for fine-grained categorization and verification.
Fine-grained recognition without part annotations.
WORDBOOK
quantitative ['kwɒntɪ,tətɪv; -,teɪtɪv]:adj. 定量的,量的,数量的
qualitative ['kwɒlɪtətɪv]:adj. 定性的,质的,性质上的
KEY POINTS
Additionally, our deep network is trained on a large dataset of several million images which are labeled through a semi-automated process.
Our model is available to developers through the Sighthound Cloud API at https://www.sighthound.com/products/cloud
Moreover, many researchers have focused on collecting large datasets to facilitate research in this area [4].
However, the complexity of current methods and/or the small size of current datasets lead to sub-optimal performance in real world use cases.
In this paper, we present a system that is capable of detecting and tagging the make, model and color of vehicles irrespective of viewing angle with high accuracy. Our model is trained to recognize 59 different vehicle makes as well as 818 different models in what we believe is the largest set available for commercial or non commercial use.
To date, we have collected what we believe to be the largest vehicle dataset, consisting of more than 3 million images labeled with corresponding vehicle make and model. Additionally, we labeled part of this data with corresponding labels for vehicle color.
We propose a semi-automated method for annotating several million vehicle images.
Our training consists of a 3-stage processing pipeline including data collection, data pre-processing and deep training.
All the images are annotated with their corresponding vehicle make and model and part of the data is annotated with vehicle colors. In order to prepare the final training data we further process the images to eliminate the effect of background.
Data collection plays an important role in training any deep neural network, especially when it comes to fine-grained classification tasks. To address this issue we collected the largest vehicle dataset known to date, where each image is labeled with corresponding make and model of the vehicle.
The final set of data contains over 3 million images of vehicles with their corresponding make and model tags. Additionally, we labeled part of this data with the corresponding color of the vehicle, chosen from a set of 10 colors; blue, black, beige, red, white, yellow, orange, purple, green and gray.
An important step in our training is alignment.
Vehicle detection not only helps us align images based on vehicle bounding boxes but also reduces the impact of the background.
Finally we consider a 10% margin around the vehicle box to compensate for inaccurate (or very tight) bounding boxes. For the task of color recognition, we took pains to further eliminate any influence the background may have on the outcome. To achieve this, we further mask the images with an elliptical mask as shown in Figure 1. Note that in certain cases the elliptical mask removes some boundary information of the vehicle. However, this had little effect on the color classification accuracy.
One is trained to classify vehicles based on their make and model and the other is trained to classify vehicles based on their color.
We trained our networks for four days on four GTX TITAN X PASCAL GPUs. Once the model is trained, we can label images at 150 fps in batch processing mode.
We report experimental results on two publicly available datasets: the Stanford Cars dataset [10] and the Comprehensive Car (compCar) dataset [4].
The Stanford Cars dataset consists of 196 classes of cars with a total of 16,185 images. The data is divided into almost a 50-50 train/test split with 8,144 training images and 8,041 testing images. Categories are typically at the level of Make, Model, Year. This means that several categories contain the same model of a make, and the only difference is the year that the car is made.
Our original model is not trained to classify vehicle models based on the year of their production. However, after fine-tuning our model on the Stanford Cars training data, we observe that we can achieve better results compared to previously published methods.
This is mainly due to the sophistication in the design of our proprietary deep neural network as well as the sizable amount of data used to train this network.
We also report results on the Comprehensive Car dataset which has recently been published. The task here is to classify data into 431 different classes based on vehicle make and model. The data is divided into 70% training and 30% testing. There are a total of 36,456 training images and 15,627 test images.
Each set contains 20,000 pairs of images. The likelihood ratio of each image pair is obtained by computing the Euclidean distant between features computed using our the deep network. The likelihood ratio is then compared against a threshold to make the final decision.
These images are illustrative of the robustness of our large training dataset, captured from different sources, to real world scenarios.














 1984
1984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









