







1、测试Spark3
(1)官网文档
http://doris.apache.org/master/zh-CN/extending-doris/spark-doris-connector.html#%E7%89%88%E6%9C%AC%E5%85%BC%E5%AE%B9
(2)将doris-spark-1.0.0-SNAPSHOT.jar复制到Spark的jars目录

(3)测试RDD
官方模板
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME"),
cfg = Some(Map(
"doris.fenodes" -> "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT",
"doris.request.auth.user" -> "$YOUR_DORIS_USERNAME",
"doris.request.auth.password" -> "$YOUR_DORIS_PASSWORD"
))
)
dorisSparkRDD.collect()
修改如下
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("tpa.table1"),
cfg = Some(Map(
"doris.fenodes" -> "node3:8030",
"doris.request.auth.user" -> "test",
"doris.request.auth.password" -> "test"
))
)
dorisSparkRDD.collect()
执行结果
[root@node1 spark-3.1.2]# bin/spark-shell
21/08/13 10:57:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = local[*], app id = local-1628823440405).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.doris.spark._
import org.apache.doris.spark._
scala> val dorisSparkRDD = sc.dorisRDD(
| tableIdentifier = Some("tpa.table1"),
| cfg = Some(Map(
| "doris.fenodes" -> "node3:8030",
| "doris.request.auth.user" -> "test",
| "doris.request.auth.password" -> "test"
| ))
| )
dorisSparkRDD: org.apache.spark.rdd.RDD[AnyRef] = ScalaDorisRDD[0] at RDD at AbstractDorisRDD.scala:32
scala> dorisSparkRDD.collect()
java.lang.NoClassDefFoundError: org/apache/spark/Partition$class
at org.apache.doris.spark.rdd.DorisPartition.<init>(AbstractDorisRDD.scala:63)
at org.apache.doris.spark.rdd.AbstractDorisRDD$$anonfun$getPartitions$1.apply(AbstractDorisRDD.scala:36)
at org.apache.doris.spark.rdd.AbstractDorisRDD$$anonfun$getPartitions$1.apply(AbstractDorisRDD.scala:35)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.doris.spark.rdd.AbstractDorisRDD.getPartitions(AbstractDorisRDD.scala:35)
at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:296)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2261)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1030)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:414)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1029)
... 49 elided
Caused by: java.lang.ClassNotFoundException: org.apache.spark.Partition$class
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:338)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 69 more
scala> dorisSparkRDD.count
java.lang.NoClassDefFoundError: org/apache/spark/Partition$class
at org.apache.doris.spark.rdd.DorisPartition.<init>(AbstractDorisRDD.scala:63)
at org.apache.doris.spark.rdd.AbstractDorisRDD$$anonfun$getPartitions$1.apply(AbstractDorisRDD.scala:36)
at org.apache.doris.spark.rdd.AbstractDorisRDD$$anonfun$getPartitions$1.apply(AbstractDorisRDD.scala:35)
at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at scala.collection.TraversableLike.map(TraversableLike.scala:238)
at scala.collection.TraversableLike.map$(TraversableLike.scala:231)
at scala.collection.AbstractTraversable.map(Traversable.scala:108)
at org.apache.doris.spark.rdd.AbstractDorisRDD.getPartitions(AbstractDorisRDD.scala:35)
at org.apache.spark.rdd.RDD.$anonfun$partitions$2(RDD.scala:300)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:296)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2261)
at org.apache.spark.rdd.RDD.count(RDD.scala:1253)
... 49 elided
scala>
2、测试Spark2
原来当前Doris还不支持Spark3(官方文档已经说明了,只能说自己不细心),切换回Spark2版本,测试如下
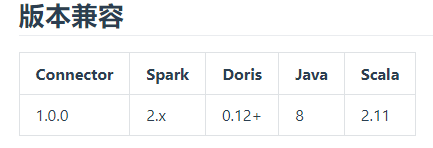
(1)同样将doris-spark-1.0.0-SNAPSHOT.jar复制到Spark的jars目录

(2)测试RDD
[root@node1 spark-2.4.8]# bin/spark-shell
21/08/13 15:04:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1:4040
Spark context available as 'sc' (master = local[*], app id = local-1628838265369).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.8
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.doris.spark._
import org.apache.doris.spark._
scala> val dorisSparkRDD = sc.dorisRDD(
| tableIdentifier = Some("tpa.table1"),
| cfg = Some(Map(
| "doris.fenodes" -> "node3:8030",
| "doris.request.auth.user" -> "test",
| "doris.request.auth.password" -> "test"
| ))
| )
dorisSparkRDD: org.apache.spark.rdd.RDD[AnyRef] = ScalaDorisRDD[0] at RDD at AbstractDorisRDD.scala:32
scala> dorisSparkRDD.count
res0: Long = 5
scala> dorisSparkRDD.collect()
res1: Array[AnyRef] = Array([2, 1, grace, 2], [4, 3, bush, 3], [1, 1, jim, 2], [5, 3, helen, 3], [3, 2, tom, 2])
scala>















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









