









第7章 MapReduce进阶
7.7 MapReduce 全排序
7.7.1 全排序方法介绍
MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序。如果我们将所有的数据全部发送到一个Reduce,那么不就可以实现结果全局有序。所以前文7.6节二次排序已经实现了最终结果有序,也就是全排序。
MapReduce全排序的方法1:
每个map任务对自己的输入数据进行排序,但是无法做到全局排序,需要将数据传递到reduce,然后通过reduce进行一次总的排序,但是这样做的要求是只能有一个reduce任务来完成。
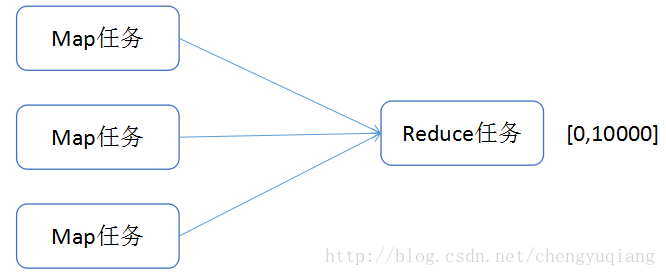
并行程度不高,无法发挥分布式计算的特点。
MapReduce全排序的方法2:
针对方法1的问题,现在介绍方法2来进行改进;
使用多个partition对map的结果进行分区,且分区后的结果是有区间的,将多个分区结果拼接起来,就是一个连续的全局排序文件。
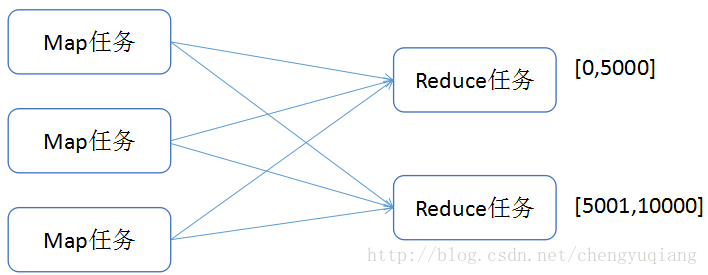
Hadoop自带的Partitioner的实现有两种,一种为HashPartitioner, 默认的分区方式,计算公式 hash(key)%reducernum,另一种为TotalOrderPartitioner, 为排序作业创建分区,分区中数据的范围需要通过分区文件来指定。分区文件可以人为创建,如采用等距区间,如果数据分布不均匀导致作业完成时间受限于个别reduce任务完成时间的影响,该方法需要人工干预,缺少自动化。也可以通过抽样器,先对数据进行抽样,根据数据分布生成分区文件,避免数据倾斜。
常见采样器
- IntervalSampler 以一定的间隔定期从划分中选择key,对有排序的数据来说更好
- RandomSameler 以指定的采样率均匀的从数据集中选择样本
- SplitSampler 只采样一个分片的前n条记录,所以不适合有排序的数据
7.7.2准备数据
编写生成测试数据的脚本
[root@node1 data]# vi genData.sh
[root@node1 data]# cat genData.sh
#!/bin/sh
for i in {1..100000};do
echo -e $RANDOM'\t'$RANDOM
done;其中,$RANDOM 是Shell内置的,用于生成五位内的随机正整数。
执行下面命令生成测试数据
sh genData.sh > genData.txt
[root@node1 data]# sh genData.sh > genData.txt
[root@node1 data]# tail -10 genData.txt
6958 15414
9321 7638
4028 9313
2666 2903
17318 26805
8430 9119
20876 25596
26221 22424
32196 10570
606 6683执行下面命令将生成的数据上传到HDFS
hdfs dfs -put genData.txt input
[root@node1 data]# hdfs dfs -put genData.txt input
[root@node1 data]# hdfs dfs -ls input
Found 5 items
-rw-r--r-- 3 root hbase 333 2017-06-23 16:11 input/books.txt
-rw-r--r-- 3 root hbase 82 2017-06-23 11:04 input/dept.txt
-rw-r--r-- 3 root hbase 513 2017-06-23 11:04 input/emp.txt
-rw-r--r-- 3 root hbase 1332178 2017-06-26 10:15 input/genData.txt
-rw-r--r-- 3 root hbase 871353053 2017-06-23 14:19 input/ncdc.txt
创建分区存放目录
hdfs dfs -mkdir partition
[root@node1 ~]# hdfs dfs -mkdir partition
[root@node1 ~]# hdfs dfs -ls /user/root
Found 3 items
drwxr-xr-x - root hbase 0 2017-06-26 13:49 /user/root/input
drwxr-xr-x - root hbase 0 2017-06-26 15:11 /user/root/output
drwxr-xr-x - root hbase 0 2017-06-26 15:29 /user/root/partition7.7.3 编程
package cn.hadron.mr.sort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class TotalOrder extends Configured implements Tool {
/**
* Mapper
*/
public static class TotalOrderMapper extends Mapper<Text, Text, Text, Text> {
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
//IntWritable intWritable = new IntWritable(Integer.parseInt(key.toString()));
context.write(key, new Text(key+"\t"+value));
}
}
/**
* Reducer
*/
public static class TotalOrderReducer extends Reducer<Text, Text, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values)
context.write(value, NullWritable.get());
}
}
/**
* Comparator
*/
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(Text.class, true);
}
@Override
public int compare(WritableComparable k1, WritableComparable k2) {
return k1.compareTo(k2);
/* int v1 = Integer.parseInt(k1.toString());
int v2 = Integer.parseInt(k2.toString());
return v1 - v2;*/
}
}
@Override
public int run(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root");
//Configuration config = new Configuration();
Configuration config = getConf();
// 设置fs.defaultFS
config.set("fs.defaultFS", "hdfs://192.168.1.117:8020");
// 设置yarn.resourcemanager节点
config.set("yarn.resourcemanager.hostname", "hds119");
FileSystem fs = FileSystem.get(config);
Job job = Job.getInstance(config);
job.setJarByClass(TotalOrder.class);
// 文件输入格式,第一个\t(tab键)之前的所有内容当做Key(Text),之后全部作为Value(Text)。
job.setInputFormatClass(KeyValueTextInputFormat.class);
job.setSortComparatorClass(KeyComparator.class);
// 输入输出路径
Path inpath=new Path("/user/root/input/genData.txt");
FileInputFormat.addInputPath(job, inpath);
Path outpath = new Path("/user/root/output/");
if (fs.exists(outpath)) {
fs.delete(outpath, true);
}
FileOutputFormat.setOutputPath(job, outpath);
job.setMapperClass(TotalOrderMapper.class);
job.setReducerClass(TotalOrderReducer.class);
job.setNumReduceTasks(3);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置分区文件存放路径
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path("/user/root/myPartition/"));
job.setPartitionerClass(TotalOrderPartitioner.class);
//参数:被选中概论0.1,选择的样本数,最大读取InputSplit数
InputSampler.Sampler<Text,Text> sampler = new InputSampler.RandomSampler<>(0.1, 1000, 10);
//写入分区文件
InputSampler.writePartitionFile(job, sampler);
job.setJobName("TotalOrder");
boolean f = job.waitForCompletion(true);
System.out.println(f);
return f ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new TotalOrder(), args);
System.exit(exitCode);
}
}7.7.4 运行结果
Eclipse运行结果
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
true查看HDFS输出结果
hdfs dfs -ls output
[root@hds117 data]# hdfs dfs -ls output
Found 4 items
-rw-r--r-- 3 root hbase 0 2017-06-26 16:09 output/_SUCCESS
-rw-r--r-- 3 root hbase 390480 2017-06-26 16:09 output/part-r-00000
-rw-r--r-- 3 root hbase 375603 2017-06-26 16:09 output/part-r-00001
-rw-r--r-- 3 root hbase 366094 2017-06-26 16:09 output/part-r-00002hdfs dfs -cat /user/root/output/part-r-00000|head -n 10
hdfs dfs -cat /user/root/output/part-r-00001|head -n 10
hdfs dfs -cat /user/root/output/part-r-00002|head -n 10
[root@hds117 ~]# hdfs dfs -cat /user/root/output/part-r-00000|head -n 10
0 12553
0 11024
0 20589
0 17571
1 32756
1 29087
1 26260
1 4495
cat: Unable to write to output stream.
[root@hds117 ~]# hdfs dfs -cat /user/root/output/part-r-00001|head -n 10
19975 30234
19975 23946
19975 29221
19975 30553
19976 4200
19977 32477
19977 32217
19978 6330
cat: Unable to write to output stream.
[root@hds117 ~]# hdfs dfs -cat /user/root/output/part-r-00002|head -n 10
29601 3263
29601 28477
29601 8625
29601 7689
29601 28880
29602 24693
29602 23077
29602 15098
cat: Unable to write to output stream.













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









