






通过Resquest或urllib2抓取下来的网页后,一般有三种方式进行数据提取:正则表达式、beautifulsoup和lxml,留下点学习心得,后面慢慢看。
- 正则表达式
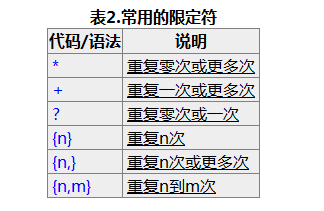
看完文档后理解正则表达式的基本概念就行,然后知道贪婪匹配和懒惰匹配的区别。实际运用过程中用的最多的就两种( .*?) 和 (d+) 分别用来匹配任意字符和数字,?表示懒惰匹配。
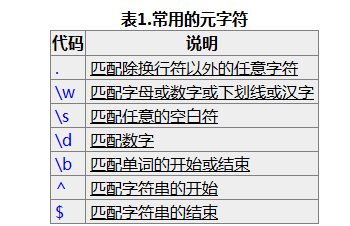
pattern=re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags])
re.search(pattern, string[, flags])
re.split(pattern, string[, maxsplit])
re.findall(pattern, string[, flags])
re.finditer(pattern, string[, flags])
re.sub(pattern, repl, string[, count])
re.subn(pattern, repl, string[, count]
flags:参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M
re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(全拼:MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
re.S(全拼:DOTALL): 点任意匹配模式,改变'.'的行为
re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定
re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
re.X(全拼:VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释
2.beautifulsoup
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment 。主要理解Tag,Tag与html中的tag相同,其有两个最重要的属性name和attribute, 分别通过tag.name和tag.attrs来调用。方法中应用最多的的就是fin() 和find_all()
find_all( name , attrs , recursive , text , **kwargs )
soup.find_all("a")
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
find( name , attrs , recursive , text , **kwargs
soup.find("head").find("title")
# <title>The Dormouse's story</title>
3 lxml
lxml最麻烦的就是安装的时候容易现各种问题,如果pip install lxml 出现问题,推荐安装方法:
(1)安装wheel :pip install wheel
(2)下载与自己系统匹配的wheel(如下),注意别改下载文件的文件名,下载链接http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml

(3) 进入.whl所在的文件夹,执行命令:pip install 带后缀的完整文件名
关于lxml的使用,一般要将抓取的html通过fromstring转换,再进行匹配选择元素
参考文档:http://lxml.de/3.6/lxmldoc-3.6.4.pdf(官方英文)
(1)html转换:fromstring()
import lxml.html
tree=lxml.html.fromstring(tree) #fromstring() 将string转换成xml,tostring()将xml转换成string
(2)元素匹配:元素选择lxml有几种不同的方法,有XPath选择器和类似beautiful soup 的 find()方法,CSS选择器等。
XPath参考:用lxml解析html
CSS参考:CSSSelector















 8883
8883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









