







NLP研究范式的转化(基本逻辑)
范式转换1.0:从深度学习到两阶段预训练模型
时间范围,大致在深度学习引入NLP领域(2013年左右),到GPT 3.0出现之前(2020年5月左右)。
NLP领域的深度学习,主要依托于以下几项关键技术:以大量的改进LSTM模型及少量的改进CNN模型作为典型的特征抽取器;以Sequence to Sequence(或叫encoder-decoder亦可)+Attention作为各种具体任务典型的总体技术框架。
在这些核心技术加持下,NLP领域深度学习的主要研究目标,是如何有效增加模型层深或模型参数容量。但是从解决具体任务的效果角度看,总体而言,不算很成功,或者说和非深度学习方法相对,带来的优势不算大。原因:1.任务相关训练数据总量有限;2.feature extractor不够强。
Bert/GPT这两个预训练模型的出现代表了NLP领域的一个技术飞跃,并带来了整个领域研究范式的转换。这种范式转换带来的影响,体现在两个方面:首先,是部分NLP研究子领域的衰退乃至逐步消亡;其次,NLP不同子领域的技术方法和技术框架日趋统一,在Bert出现后一年左右,技术栈基本收敛到两种技术模式中。
大多数NLP子领域的研发模式切换到了两阶段模式:模型预训练阶段+应用微调(Fine-tuning)或应用Zero/Few Shot Prompt模式。更准确地说,NLP各种任务其实收敛到了两个不同的预训练模型框架里:对于自然语言理解类任务,其技术体系统一到了以Bert为代表的“双向语言模型预训练+应用Fine-tuning”模式;而对于自然语言生成类任务,其技术体系则统一到了以GPT 2.0为代表的“自回归语言模型(即从左到右单向语言模型)+Zero /Few Shot Prompt”模式。
范式转换2.0: 从预训练模型走向通用人工智能 (AGI,Artificial General Intelligence)
时间范围,大致在GPT3.0出现之后(20年6月左右),一直到目前为止。
过渡期:以GPT 3.0为代表的“自回归语言模型+Prompting”模式占据统治地位(few shot prompting(也被称为In Context Learning))
由bert(encoder架构)到GPT(decoder架构)的必然原因:1.统一了理解和生成(可以把分类问题转换成让LLM模型生成对应类别的字符串)2. zero/few shot prompt必然要采取GPT模式(有相关论文)。
Why zero/few shot prompting is the goal ?
LLM理想的样子:首先,LLM应该具备强大的自主学习能力。其次,LLM应该能解决NLP任何子领域的问题,再者,LLM应该理解人类的命令。
chatGPT改变了过渡期,用instruct取代了prompt,带来新的技术范式转换,并产生若干后续影响
- 影响一:让LLM适配人的新型交互接口
- 影响二:很多NLP子领域不再具备独立研究价值
- 影响三:更多NLP之外的研究领域将被纳入LLM技术体系(向通用人工智能发展)
学习者:数据到知识(原理理解)
transformer,强大的feature extractor。
在预训练过程中,学到了什么?知识是如何存取的?如何修正错误知识?
学到了什么知识
知识分为:语言类知识和世界知识(事实性知识和常识性知识)。
随着Transformer模型层深增加,能够学习到的知识数量逐渐以指数级增加(可参考:BERTnesia: Investigating the capture and forgetting of knowledge in BERT)
对于Bert类型的语言模型来说,只用1000万到1亿单词的语料,就能学好句法语义等语言学知识,但是要学习事实类知识,则要更多的训练数据(“When Do You Need Billions of Words of Pre-training Data?”)。这个结论其实也是在意料中的,毕竟语言学知识相对有限且静态,而事实类知识则数量巨大,且处于不断变化过程中。而目前研究证明了随着增加训练数据量,预训练模型在各种下游任务中效果越好,这说明了从增量的训练数据中学到的更主要是世界知识。
如何存取知识
对于某条具体的知识,LLM把它存储到了哪里?又是如何提取出来的?这也是一个有意思的问题。
知识一定存储在Transformer的模型参数里。从Transformer的结构看,模型参数由两部分构成:多头注意力(MHA)部分占了大约参数总体的三分之一,三分之二的参数集中在FFN结构中。MHA主要用于计算单词或知识间的相关强度,并对全局信息进行集成,更可能是在建立知识之间的联系,大概率不会存储具体知识点,那么很容易推论出LLM模型的知识主体是存储在Transformer的FFN结构里。
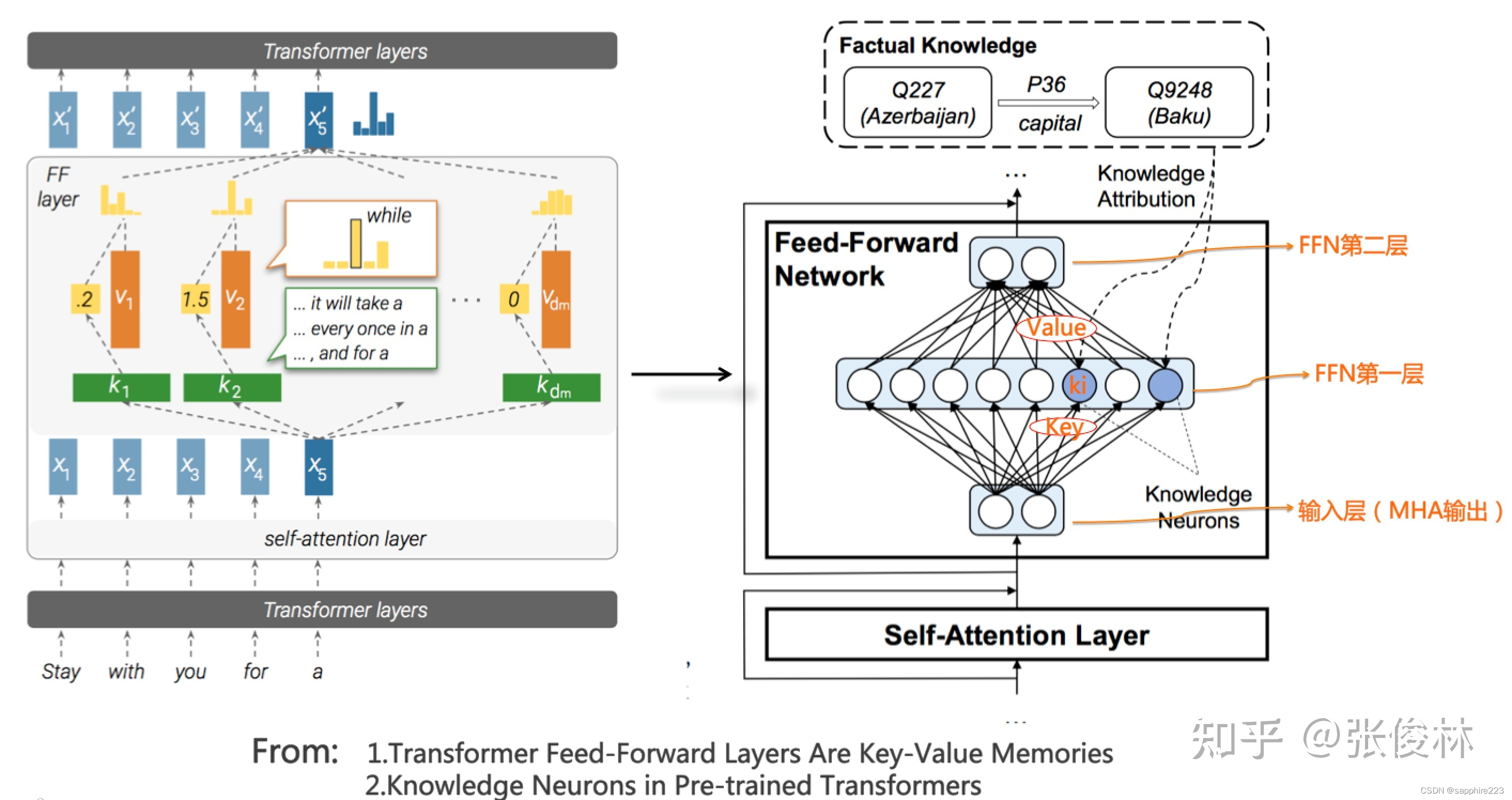
“Transformer Feed-Forward Layers Are Key-Value Memories”给出了一个比较新颖的观察视角,它把Transformer的FFN看成存储大量具体知识的Key-Value存储器。如上图所示(图左是原始论文图,其实不太好理解,可以看做了注释的图右,更好理解些),FFN的第一层是个MLP宽隐层,这是Key层;第二层是MLP窄隐层,是Value层。FFN的输入层其实是某个单词对应的MHA的输出结果Embedding,也就是通过Self Attention,将整个句子有关的输入上下文集成到一起的Embedding,代表了整个输入句子的整体信息。
假设上图的节点 k_{i}k_{i} 就是记载<北京,is-capital-of,中国>这条知识的Key-Value存储器,它的Key向量,用于检测”中国的首都是…”这个知识模式,它的Value向量,基本存储了与单词“北京”的Embedding比较接近的向量。当Transformer的输入是“中国的首都是[Mask]”的时候, k_{i}k_{i} 节点从输入层探测到这个知识模式,所以产生较大的响应输出。
如何修改存储的知识
这种方法涉及到两项关键技术:首先是如何在LLM参数空间中定位某条知识的具体存储位置;其次是如何修正模型参数,来实现旧知识到新知识的修正。关于这类技术的细节,可以参考“Locating and Editing Factual Associations in GPT”和“Mass-Editing Memory in a Transformer”。
(待补充)
规模效应:LLM越来越大时会发生什么
在预训练阶段,其优化目标是交叉熵,对GPT这种自回归语言模型来说,也就是看LLM是否正确预测到了下一个单词;而场景应用阶段,一般要看具体场景的评价指标。一般我们的直觉是:如果LLM模型在预训练阶段的指标越好,自然它解决下游任务的能力就越强。然而,事实并非完全如此。现有研究已证明,预训练阶段的优化指标确实和下游任务表现出正相关关系,但是并非完全正相关。也就是说,只看预训练阶段的指标,来判断一个LLM模型是否够好,这是不够的。基于此,我们分头来看在这两个不同阶段,随着LLM模型增大,有什么影响。
1. 伸缩法则
OpenAI在“Scaling Laws for Neural Language Models”中专门研究了这个问题,并提出LLM模型所遵循的“伸缩法则”(scaling law)。如上图所示,这个研究证明:当我们独立增加训练数据量、模型参数规模或者延长模型训练时间(比如从1个Epoch到2个Epoch),预训练模型在测试集上的Loss都会单调降低,也就是说模型效果越来越好。
既然三个因素都重要,在实际做预训练的时候,就有一个算力分配的决策问题:假设用于训练LLM的算力总预算(比如多少GPU小时或者GPU天)给定,此消彼长,某个要素规模增长,就要降低其它因素的规模,以维持总算力不变,所以这里有各种可能的算力分配方案。
最终OpenAI选择了同时增加训练数据量和模型参数,但是采用早停策略(early stopping)来减少训练步数的方案。因为它证明了:对于训练数据量和模型参数这两个要素,如果只单独增加其中某一个,这不是最好的选择,最好能按照一定比例同时增加两者,它的结论是优先增加模型参数,然后才是训练数据量。假设用于训练LLM的算力总预算增加了10倍,那么应该增加5.5倍的模型参数量,1.8倍的训练数据量,此时模型效果最佳。
2. 涌现能力Emergent Ability
“涌现能力”,指的是当模型参数规模未能达到某个阀值时,模型基本不具备解决此类任务的任何能力,体现为其性能和随机选择答案效果相当,但是当模型规模跨过阀值,LLM模型对此类任务的效果就出现突然的性能增长。
原因猜想:
1. 评价指标不够平滑,其实是逐渐提升能力的,表现出来像是突然;
2. 任务由各中间步骤构成,随着模型规模增大,解决步骤的能力增强,最后都正确后,表现出所谓涌现。
智慧之光:如何增强LLM的推理能力
记忆!=聪明,强大的推理能力->聪明。目前思路有以下两大类:
1. 基于prompt的方法
核心思想是通过合适的提示语或提示样本,更好地激发出LLM本身就具备的推理能力,Google在这个方向做了大量很有成效的工作。
这方面的工作又可以分为三条技术路线:
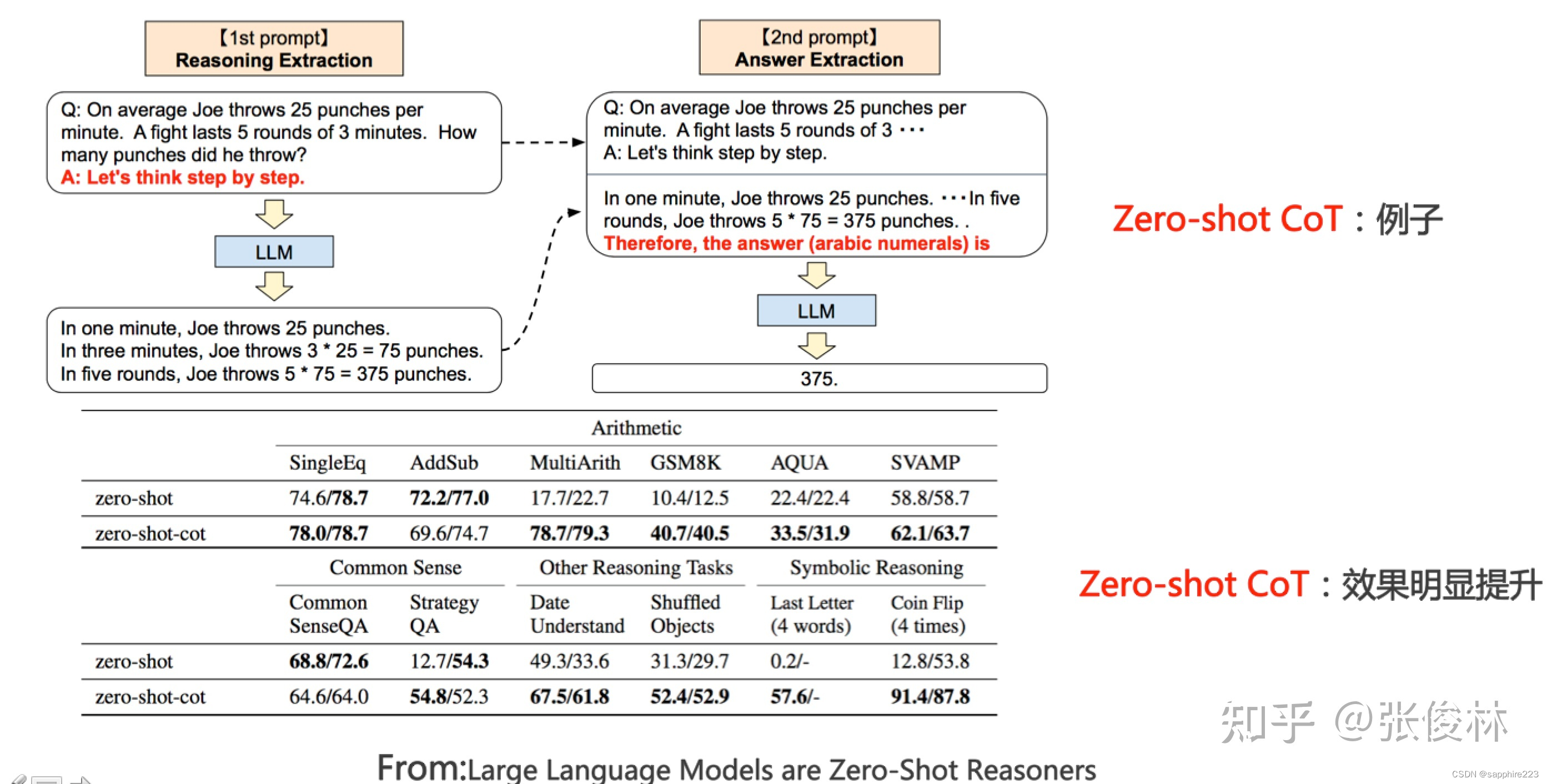
1. 在问题上追加辅助推理prompt;
2. 基于示例的思维链prompt(cot);
3. 分解问题prompt。
2. 代码预训练方法
在预训练过程中引入程序代码,和文本一起参与预训练,以此进一步增强LLM的推理能力,这应该是OpenAI实践出的思路。
来自于论文“On the Advance of Making Language Models Better Reasoners”,其中GPT3 davinci就是标准的GPT 3模型,基于纯文本训练;code-davinci-002(OpenAI内部称为Codex)是同时在Code和NLP数据上训练的模型。如果比较两者效果,可以看出,不论采用具体哪种推理方法,仅仅是从纯文本预训练模型切换到文本和Code混合预训练模型,在几乎所有测试数据集合上,模型推理能力都得到了巨大的效果提升。
为何预训练模型可以从代码的预训练中获得额外的推理能力?确切原因目前未知,值得深入探索。我猜测可能是因为原始版本的Codex(只使用代码训练,可参考文献:Evaluating Large Language Models Trained on Code)的代码训练是从文本生成代码,而且代码中往往包含很多文本注释,本质上这类似于预训练模型做了<文本,Code>两种数据的多模态对齐工作。
未来之路
- LLM规模的天花板?
- 增强LLM的复杂推理能力
- 领域统一和集成
- 更易用的人机接口
- 综合任务评测方法和数据
- 更高质量数据工程
OpenAI&AGI
why OpenAI?
在OpenAI眼中,未来的AGI应该长这个样子:有一个任务无关的超大型LLM,用来从海量数据中学习各种知识,这个LLM以生成一切的方式,来解决各种各样的实际问题,而且它应该能听懂人类的命令,以便于人类使用。其实对LLM发展理念的理解,在前半部分,就是“构建一个任务无关的超大型LLM,让它从海量数据中学习各种知识”,这一点几乎是大家的共识,能体现出OpenAI眼光的其实是后半部分。
OpenAI之所以能作出ChatGPT,胜在一个是定位比较高,另一个是不受外界干扰,态度上坚定不移。
参考资料:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









