






##缓存行填充 关于缓存行填充在我个人的印象里面第一次看到是在Java的java.util.concurrent包中,因为当时很好奇其用法背后的逻辑,所以查了很多资料才明白到底是怎么回事*(也许事实上也不是那么回事)*。这次阅读Disruptor源码的时候又看到类似的用法所以感到很亲切。关于 java.util.concurrent 包的作者大家可以点击链接了解一下这个神奇的老头,他就是在Java并发编程领域大名鼎鼎的Doug Lea。好了我们下面了解一下在Disruptor中是怎么用缓存行填充的。
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
/* volatile 修饰的变量本身就是64个字节的*/
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
{
/* 两个Long类型的变量 INITIAL_VALUE,VALUE_OFFSET*/
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static
{
UNSAFE = Util.getUnsafe();
try
{
VALUE_OFFSET = UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}
catch (final Exception e)
{
throw new RuntimeException(e);
}
}
}
在Disruptor 的RingBuffer的实现中我们可以看到好几处这样的用法,在一个类中声明七个Long类型的变量,但是在整个代码的实现中又不去用它,是不是感觉特别不解?这样用的原理就是一个Java的Long类型是8个字节的长度,7个Long就是56个字节,继续看下面这个Sequence类的实现,它定义了两个Long类型的变量,再加上Value的实现刚好是3个64字节 (关于volatile修饰我们后面会说) ,64字节也是大多数CPU的缓存行长度。
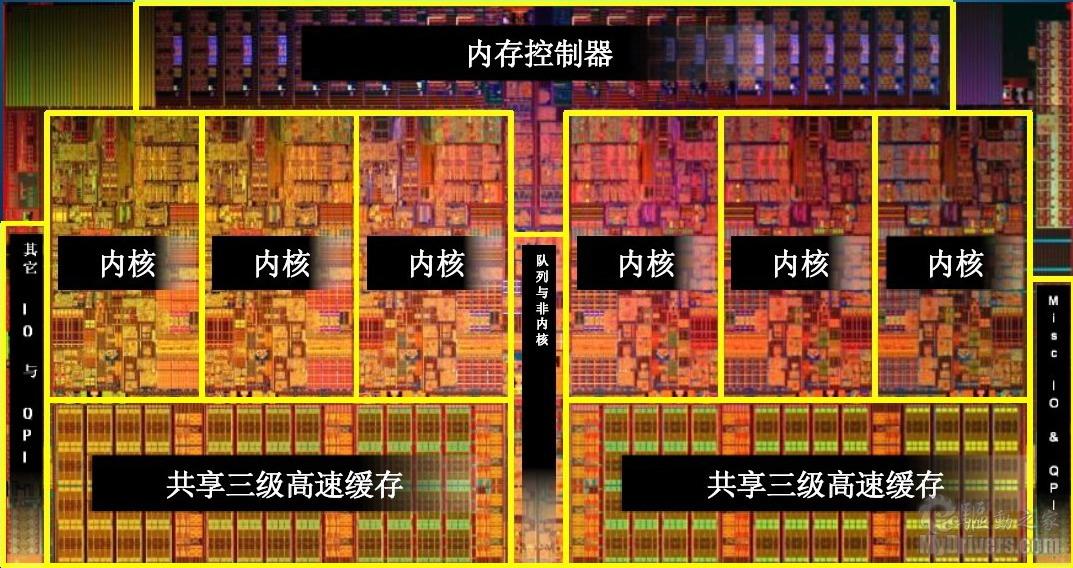
上面这张图是我从网上找的关于CPU内部构造的图片,从这张图片上我们可以看到有6个处理核心和两个三级缓存区
,CPU在运行计算的时候为了能够高效的处理数据会先将数据从内存中加载到缓存区中,这样处理的速度就要比直接从内存中加载数据去处理要快好多,所以就有了缓存区这个设计 (当然还有其他原因)。
除内存外一台计算机还有其他额外的存储区域,比如RAM 一级缓存L1,二级缓存L2和三级缓存L3,其中L1和L2是CPU中最接近内核的缓存区,所以他们的速度更快,但是这两级缓存是本地缓存,不对其他内核共享。关于CPU缓存大家可以查看 CPU缓存 。
缓存数据是存储在缓存行当中的,目前主流CPU的缓存行大小是64个字节,但是问题是我们在程序中使用的变量绝大多数是不够64个字节的,这样带来的问题就是有时候会在同一个缓存行中存储多个变量的值,假如有A,B两个变量,现在CPU要处理变量A,那么它必须将整个缓存行的数据都取出,这样它就“买一赠一”的拿到了另外一个变量B,可是这样做的后果就是内核之间就会发生争吵*(锁竞争,缓存行锁定,我们尽量用通俗易懂的概念来说明)*这会带来系统开销,所以最好的做法就是一个缓存行只保存一个变量,其他的全部填充满,大家每个人住一个房子谁也不妨碍谁,这也就是为什么我们在RingBuffer的实现中看到它会用7个Long值的原因,这样做虽然从微观上来讲效率提升不是特别明显,但是试想一下如果我们每个线程都能快那么一点点那么几百个线程积攒下来的效率也是不少。
原子操作与CAS
原子操作
原子操作*(Atomic operation)*是指不可以被中断的一个或者一系列操作,也就是说这个操作是不可以分割的最小单元,这个概念是CPU计算中的一个概念。比如我们现在要做一个 a=1的赋值操作,那个这个就是原子的,你要不赋值成功要不失败。为了实现这种原子操作CPU会采取一些措施,比如总线锁或者缓存锁。
- 总线锁:当一个处理器在处理数据时,如果处理器A在享受共享内存中的某个值的时候它会通过LOCK#型号来告诉其他处理器:“目前共享内存我正在使用你们先等着”。
- 缓存锁:缓存锁是指缓存行锁定,也就是说它不会在总线上去申明LOCK将整个共享内存锁定*(因为这样做的开销很大)*,而是去锁定缓存行,这样的话当其他处理器访问该缓存行的时候就会失败。值得注意的是目前绝大多数的处理器能够保证在16/32/64位字节的处理上是原子的。
JVM 的 CAS操作
由于Java是跨平台的编程语言,其依靠JVM来与底层硬件交互,所以为了能够在跨平台环境下实现这样的原子操作,Java采用的是CAS策略,也就是compare and swap。这种策略是采用目前大多数CUP支持的CMPXCHG指令来实现。所谓CAS操作就是在操作期间先比较旧值有没有发生变化,如果没有发生变化则将新值赋给它,否则失败(旧制指的是期望操作前的值)。
指令重排与volatile
现代计算机为了实现效率最大化的目的往往会对计算机指令进行重排序,这也就是我们经常会听到的指令重排。 对于Java来讲我们要注意的是Java程序会经历两次重排序,一次是编译器级别的重排序而另外一个是指令重排序。编译器重排序是在Java编译器中发生的,编译器为了优化执行效率会在编译Java的时候在不影响语义的前提下*(指的是单线程语义)会对语句进行重新排序。而指令级别的重排序是在CPU执行的时候进行的指令重排序(Java语句最终会转换为操作指令)*,如果指令直接不存在数据依赖性那么这些指令有可能被重新排序或者重叠执,下面的代码在执行或者编译的时候很有可能会发生重排现象。
public void reordering(int a , int b){
a = 3;
b = 4;
}
因为他们不存在数据依赖,谁先执行或者重叠执行时没有任何影响的。但是下面这种情况就不会被重排,比如:
public void reordering(int a , int b){
a = 3;
b = a + 2;
c = b;
}
他们不会被重新排序的原因是因为他们之间存在数据依赖关系。编译器或者CPU在执行重排的时候会检查他们之间的依赖关系*(但是有些时候靠机器去检查也是有些不靠谱的地方)*。但是有时候为了避免由于指令重排出错导致的问题,这个时候我们就需要内存屏障来要求CUP在执行的时候哪些指令是不能随便重排的。
讲了这么多什么CAS啊指令重排啊和我们的Discruptor有毛的关系?其实是有关系的,因为在Discroptor中对有些字段进行了volatile申明,而volatile这个修饰背后有很多与指令重排和内存屏障有关,所以为了更好的理解volatile我们需要总结一下这些基础的内容
内存屏障
为了防止不必要的指令重排序以及保证特定内存空间的可见性Java编译器会在特定的位置加入内存屏障 JVM分了四种内存屏障,它们分别是、LoadLoadBarriers、StoreStroeBarries、LoadStoreBarriers和StoreLoadBarriers,这四种内存屏障各有作用。
- LoadLoadBarriers:保证该内存屏障之前的所有Load操作先与之后所有的Load操作
- StoreStroeBarries:保证该内存屏障之前的所有Store先与之后所有Store,也就是说在该内存屏障之前的所有Store数据被刷新到共享内存中之后屏障后面的Store操作才会执行
- LoadStoreBarriers:也就是在该内存屏障之前的所有内核Load完成以后才会执行后面的Store动作
- StoreLoadBarriers:这是一种最通用的屏障,在该屏障后面的所有Load总是能得到最新的值
关于指令重排其实还有很多内容,比如happen-before原则、as-if-serial原则等,由于今天有点累了所以这些内容大家可以自行查阅相关资料去了解,下面给了维基百科的词条内容。 Happened-before from wiki | JSR-133: Java Memory Model and Thread Specification | Java theory and practice: Fixing the Java Memory Model, Part 2 | The Java Language Specification, Third Edition | Programming Language Pragmatics, Third Edition
Volatile 变量与内存屏障
Volatile是一种变量可见性的修饰,它不是锁机制,所以很多人说Volatile是轻量级锁的这个观点是错误的,因为它的实现不是通过锁而是通过内存屏障。当一个变量被Volatile修饰,那么在编译的时候编译器会在这个变量的前后加入内存屏障来阻止重排序从而达到内存的有效共享。所以Volatile是可见性修饰而不是锁。 编译器在编译一个写操作的Volatile变量之前会插入一个StoreStore内存屏障,这样就保障了这个写是在最新的值的基础上的写操作,反过来它在其后面会加一个StoreLoad内存屏障。编译器在一个读的Volatile前面会加一个LoadLoad内存屏障以保证其能读到最新的值,反之会在其后面加一个LoadStore内存屏障。
关于Java多线程的基础知识目前就告一段落,因为这其中很多内容和底层相关所以难免会有一些错误的地方。希望大家能及时指正,关于Volatile大家可以通过网络进一步了解。从下一个章节开始正式进入Discruptor的原理分析与源码探秘。















 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









