






kafka是一种分布式的、基于发布/订阅的消息系统
1、kafka队列为什么吞吐量大
a、生产消息时kafka是顺序写入硬盘
b、Kafka的数据并不是实时的写入硬盘而是使用内存映射文件技术(mmap)
Kafka提供了一个参数——producer.type来控制是不是主动flush 即同步和异步
c、消费者消费消息时读取数据的时候是以文件的方式零拷贝从内核空间直接输入到端口上
d、Kafaka消息存储是基于partiton,可以横行扩展
2、kafaka Broker Server
leader选举
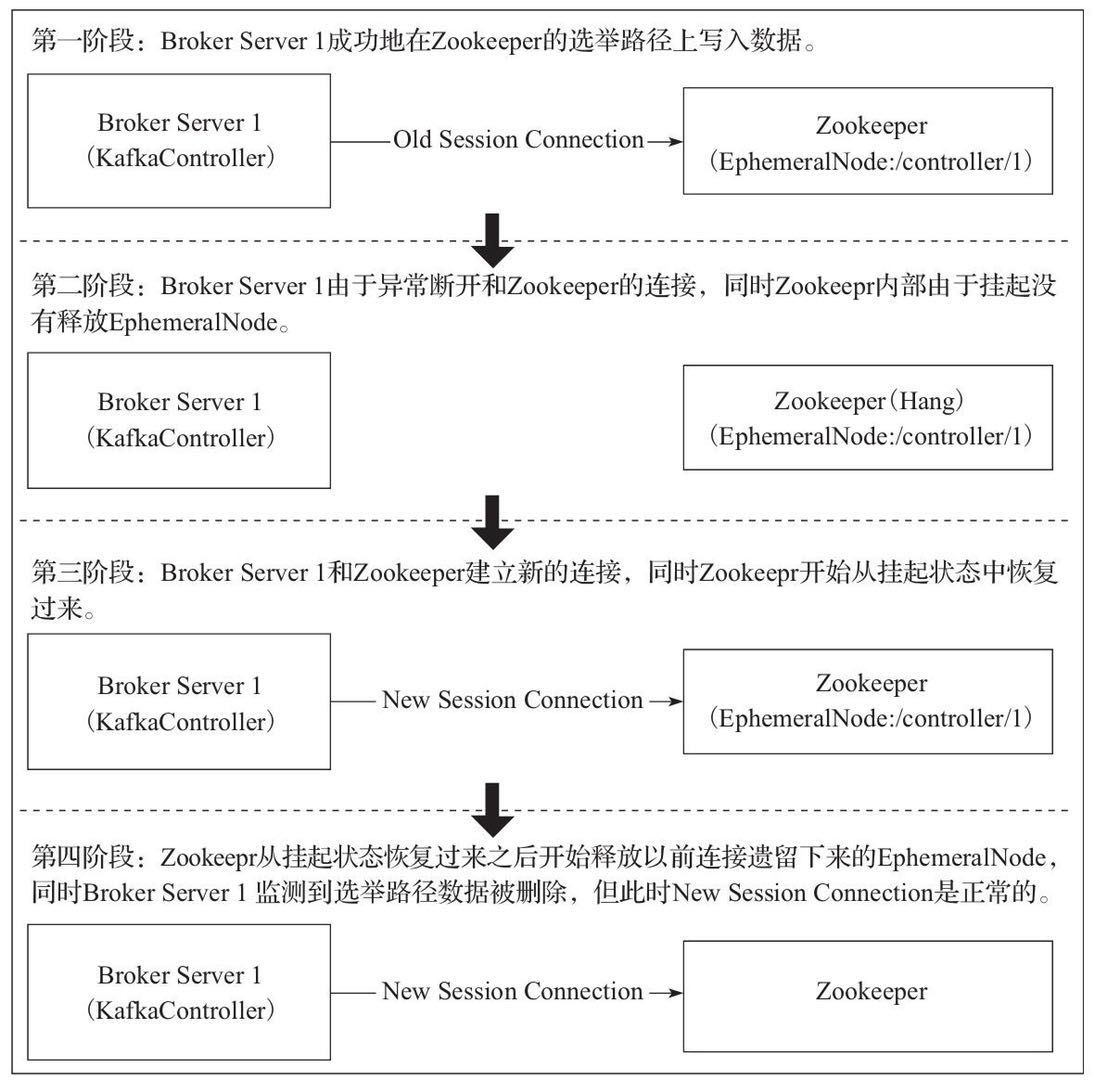
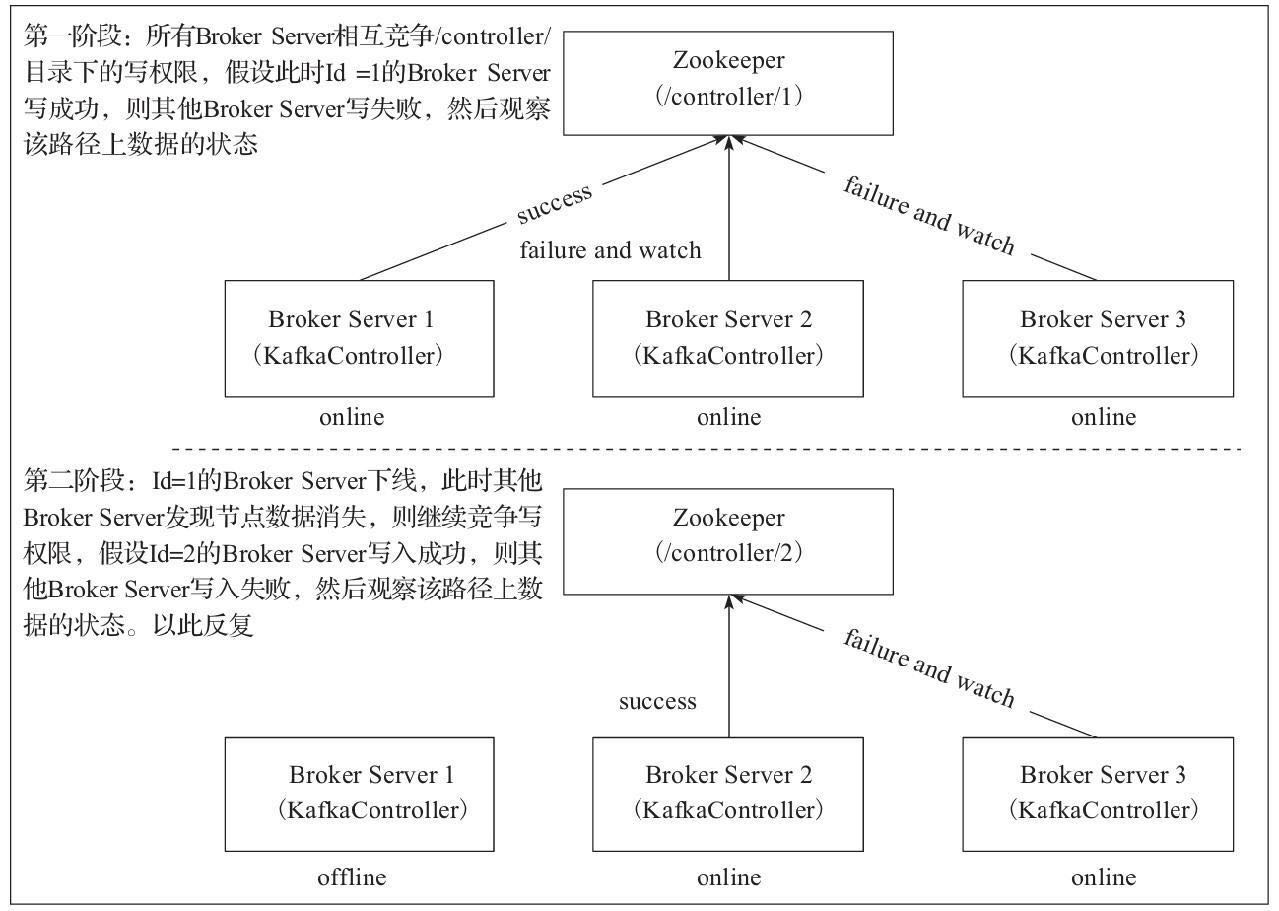
防止kafka丢消息
1、生产端使用同步发送、设置required.acks属性为-1(主从同时确认)
0:不确认,1:主确认
2、设置消息ID保证消息不重复
3、消费端设置delivery属性为at least one 至少消费一次
先消费再确认。通过业务主键保证幂等















 7603
7603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









