







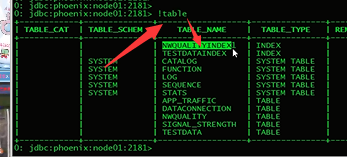
电信号项目中有六张hive原始表,最总要变成五张基于hbase的phoneix表,
编写的自定义字段转换函数,有的函数会有带一个参数和带两个参数,这是因为不同的phoneix表会用到不同的自定义处理方式.
由六张表变成五张表的过程中,涉及到多表关联查询,需要相同的字段连接,然而同一字段表现形式会不同比如:
这里就需要对字段做截取

五张habase中可能存在很多的逗号,这回影响到后面转换成phoneix表,要解决逗号的问题
在文章的上一篇的 知识点33
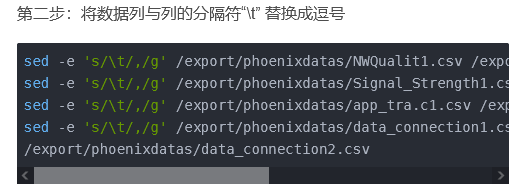
前端项目补充
导入前段页面项目的时候需要本地mysql创建用户登录密码表
这样才能登录成功
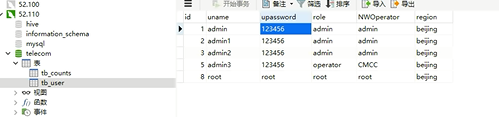
配置前端项目能连接上mysql和phoneix数据库
配好tomcat项目后直接运行即可
第一次提交查询的时候能明显的感觉到速度很慢,大约超过6秒以上
这是矩形图(每次执行都要查询300次)
目前就是有效果但是没有效率.(得加索引)




索引优化
创建索引的首个字段,作为查询条件的首个字段,效率较高。(其他条件的数据也在索引里)
这是比较折中的方法,虽然有更高效的索引方式,但不够性价比,这种方法意味着首索引最总要,索引会有必要的富余,除第一索引外,其后索引顺序不一定完全符合顺序.

解释下上图为啥有的类型没有填写,有的有红色括号:其实只有三种类型,红的括号内容是
查看索引信息
再次查询速度贼快


关于mysql binlog日志配置说明
binlog配置
log-bin = /usr/local/var/mysql/logs/mysql-bin.log #log日志打入的位置
binlog-format=ROW # 必须得有
expire-logs-days = 14 #执行日志的天数
max-binlog-size = 500M #最大日志的大小
server-id = 1 #在集群中的编号
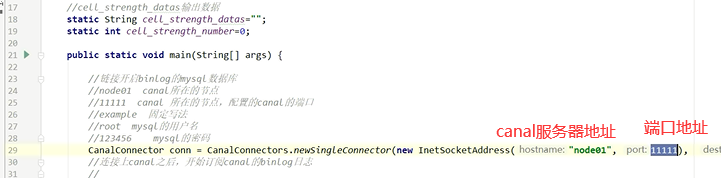
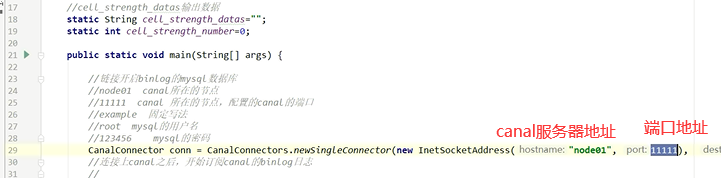
如果重启失败

java连接canal
 >你操作一条 数据,在binglog里会记录下你操作的的类型,字段和对应的值.
>你操作一条 数据,在binglog里会记录下你操作的的类型,字段和对应的值.
flume配置
实时数据经过canal接收后被写入本地相应的目录。Flume负责本地数据的收集及传递,一份数据传递到HDFS,用于离线计算,一份数据传入kafka集群用于实时业务计算。
进入Flume conf目录
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
创建spooldir2kafka.conf配置文件,用于收集canal写出的实时新数据。
vi spooldir2kafka.conf
配置如下
#定义三个source 用于监控三个目录的数据
a1.sources = r1 r2 r3
#定义两个channels 一个存储给kafka 实时计算,一个存储给hdfs 用于离线分析
a1.channels = c1 c2
#定义两个sinks 一个发送给kafka 实时计算,一个发送给下一个flume 用于写入HDFS
a1.sinks = k1 k2
# source r1监控目录/opt/Telecom/Data/cell_strength
a1.sources.r1.type =spooldir
a1.sources.r1.spoolDir=/opt/Telecom/Data/cell_strength
#r1 添加一个static类型的拦截器,key为table,value为cell_strength
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = table
a1.sources.r1.interceptors.i1.value = cell_strength
# source r2监控目录/opt/Telecom/Data/ data_connection
a1.sources.r2.type =spooldir
a1.sources.r2.spoolDir=/opt/Telecom/Data/data_connection
#r2 添加一个static类型的拦截器,key为table,value为data_connection
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = table
a1.sources.r2.interceptors.i2.value = data_connection
# source r3监控目录/opt/Telecom/Data/networkqualityinfo
a1.sources.r3.type =spooldir
a1.sources.r3.spoolDir=/opt/Telecom/Data/networkqualityinfo
#r3 添加一个static类型的拦截器,key为table,value为networkqualityinfo
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = table
a1.sources.r3.interceptors.i3.value = networkqualityinfo
# 设置每个channels的类型
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c2.type = memory
a1.channels.c2.capacity = 20000
a1.channels.c2.transactionCapacity = 10000
#描述sink
# 直接发给kafka内topic名称为Telecom的topic
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = Telecoms
a1.sinks.k1.kafka.bootstrap.servers = node01:9092
#发给下一个flume,这份是用来保存到hdfs的.
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node01
a1.sinks.k2.port = 8989
# Bind the source and sink to the channel
#三个source将数据写入两个channel
a1.sources.r1.channels = c1 c2
a1.sources.r2.channels = c1 c2
a1.sources.r3.channels = c1 c2
#sinks1在channel 1 获取数据
a1.sinks.k1.channel = c1
#sinks2在channel 2 获取数据
a1.sinks.k2.channel = c2
进入Flume conf目录
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
创建spooldir2kafka2.conf配置文件,用于接受前面传过来的数据,将其写入HDFS。
vi spooldir2kafka2.conf
配置如下
# source , channels, sinks
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source,与spooldir2kafka.conf发送数据的端口对接
a1.sources.r1.type = avro
a1.sources.r1.bind = node01
a1.sources.r1.port =8989
#添加时间拦截器,用于解析key,和value
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义sink,将数据写入HDFS
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.52.100:8020/spooldir/Telecom/Data/%{table}
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume会把处理过的数据加上后缀.COMPLETED

spark实时消费kafka数据
初始化读取出历史的,然后读取出新增的(2秒读取一次),将历史的和新增的加在一起,写入mysql表里,就作为历史的待加. 生产数据的jar包不运行就不会看到打印有新增数据的.















 3820
3820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









