






Kafka是一个分布式的流处理平台

Kafka提供封装好的客户端以方便开发者连接服务器,目前常用的客户端有两种:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.10.0.1</version>
</dependency>上面的一种为官方目前推荐的(但貌似很多生产环境是用下边一种的),具体的历史原因第二种2013年就已经问世了,第一种是在2015年的时候才出现的,为了响应官方号召我将主要分析第一种客户端
1. Producers
Producer API 允许应用程序发布一个或多个流式数据给topic, 如果需要使用这个API,你需要在maven的pom配置文件中,增加一个依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>我们会看到客户端(刚才添加这个东西会引入一个kafka客户端)中定义了一个Producer接口,并继承于Closeable接口(这个接口源于JDK1.5,通常用于需要关闭对象的资源,其中有一个close方法用于关闭,并抛出一个IOException),我们简单看一下类图,Apache已经为我们搞定了两个实现,如下:

KafkaProducer
这个是Apache提供的一个Producer接口实现,同时标明了他是单例且线程安全的,使用方法大致如下:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();Properties的配置参数大家可以到 http://kafka.apache.org/documentation.html#producerconfigs 查看手册
MockProducer
这个是apache为开发测试提供的一个实现类,他提供了一些扩展的方便,可以方便我们开发的时候用于调试
2. Consumers
消费者的接口设计稍微复杂一些,应该是为了方便使用,同样apache也提供了两个实现,如果需要使用apache提供的客户端,同样需要引入如下包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.1.0</version>
</dependency>Consumer接口看以下类图:
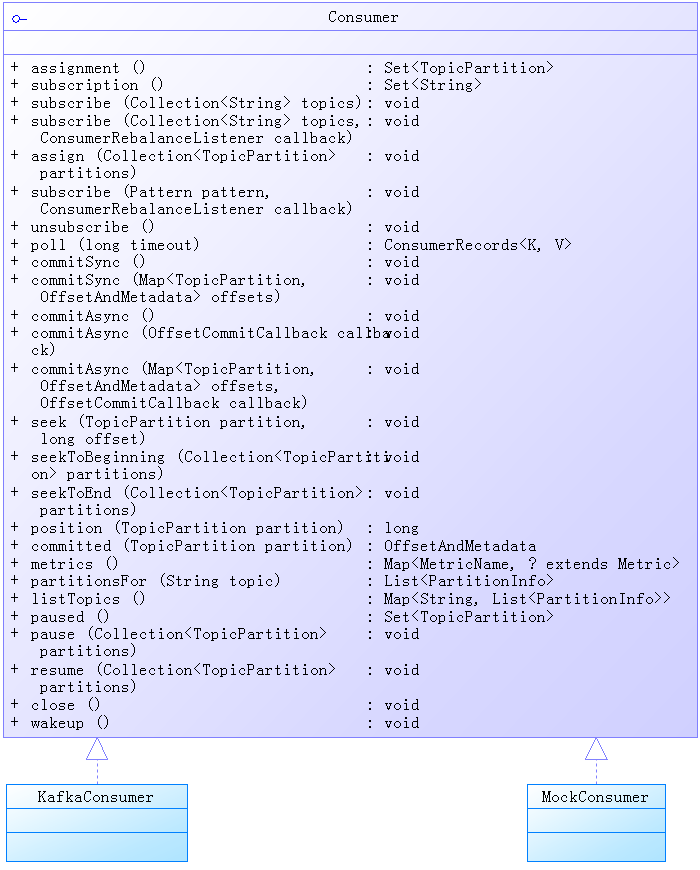
KafkaConsumer
需要注意的一点是这个KafkaConsumer实现,并不是线程安全的,大家在使用过程中,需要保证线程安全,
这个Consumer的实现,我们可以参考如下几种用法:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
while(true){
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset =%d, key =%s, value =%s", record.offset(), record.key(), record.value());
}上面这种用法设置了 enable.auto.commit = true, offsets 将会根据 auto.commit.interval.ms 的值,进行自动提交
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer(props);
consumer.subscribe(Arrays.asList("foo", "bar"));
final int minBatchSize = 200;
List<ConsumerRecord<String, String>> buffer = new ArrayList<ConsumerRecord<String, String>>();
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
buffer.add(record);
}
if (buffer.size() >= minBatchSize) {
insertIntoDb(buffer); //这里插入数据库
consumer.commitSync();
buffer.clear();
}
}以上这种用法关闭了 enable.auto.commit 参数,通过 consumer的commitSync方法来手动commit(Commit操作表示客户端通知服务端,信息已经收到,服务器会标记信息为 commited 状态),同时使用List做了一个缓存,来批量进行数据库写入操作
public class KafkaConsumerRunner implements Runnable {
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.3.37:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "false");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
int totleThread = 5;
CountDownLatch countDown = new CountDownLatch(totleThread);
List<KafkaConsumerRunner> consumers = startServer(props, totleThread, countDown);
Thread.sleep(10000);
stopServer(consumers);
countDown.await();
System.out.println("shutdown all done");
System.exit(0);
}
private static void stopServer(List<KafkaConsumerRunner> consumers) {
System.out.println("start shutdown");
for(KafkaConsumerRunner consumerRunner : consumers){
consumerRunner.shutdown();
}
}
private static List<KafkaConsumerRunner> startServer(Properties props, int totleThread, CountDownLatch countDown) {
ExecutorService threadPool = Executors.newFixedThreadPool(totleThread);
List<KafkaConsumerRunner> consumers = new ArrayList<KafkaConsumerRunner>();
for (int i = 0; i < 5; i++) {
KafkaConsumerRunner consumer = new KafkaConsumerRunner(countDown, props);
threadPool.execute(consumer);
consumers.add(consumer);
}
return consumers;
}
private final AtomicBoolean closed = new AtomicBoolean(false);
private final KafkaConsumer consumer = null;
private CountDownLatch countDown;
private Properties props;
private KafkaConsumer<String, String> consumer = null;
public KafkaConsumerRunner(CountDownLatch countDown, Properties props) {
this.countDown = countDown;
this.props = props;
this.consumer = new KafkaConsumer(this.props);
}
public void run() {
try {
consumer.subscribe(Arrays.asList("topic1", "demo"));
while (!closed.get()) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (TopicPartition partition : records.partitions()) {
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
// // Handle new records
System.out.println(record.offset() + ": --" + record.value() + " " + Thread.currentThread().getId());
}
consumer.commitSync();//同步
}
}
} catch (WakeupException e) {
// Ignore exception if closing
if (!closed.get()) throw e;
} finally {
consumer.close();
}
}
// Shutdown hook which can be called from a separate thread
public void shutdown() {
countDown.countDown();
closed.set(true);
}
}一个多线程使用的例子
MockConsumer
这应该还是一个用来测试的实现
更多的配置参数可以看 http://kafka.apache.org/documentation#producerapi , 我们同样可以实现自己的 partition.class 只要实现 Partitioner 接口就可以
public class RandomPartitioner implements Partitioner {
private Random ran = new Random();
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
synchronized (this) {
int partitionerNum = cluster.partitionsForTopic(topic).size();
return ran.nextInt(partitionerNum);
}
}
public void close() {
}
public void configure(Map<String, ?> configs) {
}
}然后通过 Properties 类配置到 Producer 就可以了
props.put("partitioner.class", RandomPartitioner.class.getName());
3. Connectors
Connectors 是Kafka 0.9 版本提供的一种新的工具,他的主要目的是将其他系统(平台)的数据导入、导出到Kafka的集群里,甚至可以把整个数据库导入到Topic中,同时也可以作为数据的二次存储、查询或者批量的进行离线分析
Kafka 已经提供了一个工具给我们玩耍:
第一步:建立一个测试文件
echo "this is large data" > test.txt第二步:查看source的配置文件
vim config/connect-file-source.properties
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=connect-test里面一个file参数是指定source(需要被导入kafka的数据)文件的位置
第三步:查看sink文件配置
vim config/connect-file-sink.properties
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=test.sink.txt
topics=connect-test这里配置了数据从kafka集群导出后需要保存的位置(目前为test.sink.txt)
第四部:运行kafka自带脚本
bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties运行后会看到当前目录多了一个 text.sink.txt, 内容与 text.txt 一致,同时两个文件(数据)可以通过kafka保持同步
同时我们可以自己写一个配置文件链接数据库,例如
name=test-mssql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:sqlserver://127.0.0.1:1433;user=xd;password=xd;databaseName=scratchpad
mode=incrementing
incrementing.column.name=id
topic.prefix=test-mssql-jdbc-
table.whitelist=data01
同时我们可以通过实现 Connector 和 Task 接口来实现自己的应用,但很可惜我在客户端内没有找到这两个接口,只有在kafka源码中有这两个接口,官方的例子如下:
http://kafka.apache.org/documentation#connect_developing
4. StreamProcessors
Stream是一个客户端库,用于处理和分析那些存储在Kafka上的数据,同时可以将结果写回到Kafka集群或者发送到外部的系统,其特点如下:
- 设计一个简单且轻量级的客户端(貌似Stream很多都是用spark),可以方便的嵌入到已有的Java应用当中
- 消息通讯层只依赖Kafka自己(不依赖其他东西),使用Kafka分区模型水平的拆分处理
- 支持本地状态容错(不是十分清楚什么鸟意思)
目前对Stream了解并不多,后续跟进















 6677
6677











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









