






最近闲来无事,搜集一些消息架构方面的资料进行学习,偶然在一个站点发现Kafka还是不错的,故想按着自己研究、学习的经历,写下一篇日记,以便后续在工作中可以 Ctrl + C & Ctrl + V , 嘿嘿
Kafak是谁?
Kafka源自LinkIn,主要支撑分布式日志服务,主要开发语言是Scala+少量的Java,设计目标是一种基于集群可处理流式数据的消息分布式系统,后开源交付给Apache基金会进行维护,目前是该基金会的顶级项目之一,当然还有一款大名鼎鼎消息系统ActiveMQ目前也是Apache基金会进行维护,后续在学习中会逐渐对两款消息机制进行对比
Apache对Kafka的定位
1. Publish & Subscribe (发布&订阅)
Kafka是一种基于发布&订阅(也有称为生产/消费模型)架构的一种消息机制,目前需要大吞吐量的架构大多基于消息机制。
2. Process (数据处理)
Kafka可高效的处理流式数据,并且可以进行实时处理
3. Store (存储)
Kafka的消息数据存储是基于自身一种叫 Isr 的东西来进行安全可靠的分布式存储

快速开始使用Kafka
1. 下载Kafka服务器端
目前Kafka最新版本是0.10.1.0,但坊间流传0.8.x系列才是最为流行的,原因是当时由于storm的流行,造就了目前的Kafka(当然你需要Linux系统来玩Kafka,我用的是Oracle VM VirtualBox)
http://kafka.apache.org/downloads
有多个版本可以(自行)进行选择
wget http://mirror.bit.edu.cn/apache/kafka/0.10.1.0/kafka_2.10-0.10.1.0.tgz如果你这里没有wget工具的话,可以通过yum进行安装
yum install wget解压
tar -zxvf kafka_2.10-0.10.1.0.tgz 将Kafka移动到本地用户目录下面
mv kafka_2.10-0.10.1.0 /usr/local/看一下Kafka里面有什么东西
[root@localhost kafka_2.10-0.10.1.0]# ls
bin config libs LICENSE NOTICE site-docs通过长期对Apache的东西使用,看名字也应该知道目录大概的用途(其实懂计算机的都应该知道)
bin:提供一些写好的脚本文件,用于管理、测试服务器
config:肯定是一堆相关的配置文件
libs:一对libs(依赖)
LICENSE:许可文件说明(开源不等于随便免费使用,各位开发者请注意一下版权)
NOTICE:没什么用的一些内容
site-docs:里面有一个 kafka_2.10-0.10.1.0-site-docs.tgz 压缩包,应该是使用手册的本地版本(API说明之类的)
2. 启动服务器(你没看错、就是这么简单..)
当然Kafka是依赖于zookeeper的(当年面试只知道是动物园管理员 :D),所以需要先启动zookeeper,由于kafka高度依赖zookeeper(目前基本算一个分布式JDNI实现),所以kafka压缩包内自带了一个简易版的zokeeper,使用下便命令启动(前提条件是服务器需要jvm支持,可以安装JDK解决)
bin/zookeeper-server-start.sh -daemon config/zookeeper.propertieszookeeper-server-start.sh 脚本的参数如下:
[root@localhost kafka_2.10-0.10.1.0]# bin/zookeeper-server-start.sh
USAGE: bin/zookeeper-server-start.sh [-daemon] zookeeper.properties-daemon:后台值守模式?(静默模式)反正就是后台启动,需要看到输出的同学可以不加这个参数
zookeeper.properties:properties当然是配置文件,通常会放在config目录下面
验证一下是否启动成功(lsof 也可以直接 yum install lsof)
[root@localhost kafka_2.10-0.10.1.0]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 2236 root 83u IPv6 19048 0t0 TCP *:eforward (LISTEN)如果2181端口处于 LISTEN 状态的话,基本说明zookeeper已经启动完毕了,接下来就可以启动kafka服务器了,脚本看名字就知道是这个,看一下参数,大体和zookeeper一样
[root@localhost kafka_2.10-0.10.1.0]# bin/kafka-server-start.sh
USAGE: bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*启动之
bin/kafka-server-start.sh -daemon config/server.properties查看一下启动情况,(kafka默认服务端口是9092,可以通过看server.properties知道-当然也可以修改)
[root@localhost kafka_2.10-0.10.1.0]# lsof -i:9092
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 2468 root 97u IPv6 19365 0t0 TCP *:XmlIpcRegSvc (LISTEN)
java 2468 root 101u IPv6 19367 0t0 TCP localhost:47108->localhost:XmlIpcRegSvc (ESTABLISHED)
java 2468 root 102u IPv6 19368 0t0 TCP localhost:XmlIpcRegSvc->localhost:47108 (ESTABLISHED)
[root@localhost kafka_2.10-0.10.1.0]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 2236 root 83u IPv6 19048 0t0 TCP *:eforward (LISTEN)
java 2236 root 84u IPv6 19360 0t0 TCP localhost:eforward->localhost:59873 (ESTABLISHED)
java 2468 root 82u IPv6 19357 0t0 TCP localhost:59873->localhost:eforward (ESTABLISHED)如果9092处于LISTEN,说明kafka(单机版)已经可以工作了
3. 创建一个 topic
topic 是一个话题,如果从rpc架构理解有点像接口名,通过kafka-topics.sh这个脚本就可以创建topic了,直接运行可以看到帮助
[root@localhost kafka_2.10-0.10.1.0]# bin/kafka-topics.sh
Create, delete, describe, or change a topic.
Option Description
------ -----------
--alter Alter the number of partitions,
replica assignment, and/or
configuration for the topic.
--config <name=value> A topic configuration override for the
topic being created or altered.The
following is a list of valid
configurations:
cleanup.policy
compression.type
delete.retention.ms
file.delete.delay.ms
flush.messages
flush.ms
follower.replication.throttled.
replicas
index.interval.bytes
leader.replication.throttled.replicas
max.message.bytes
message.format.version
message.timestamp.difference.max.ms
message.timestamp.type
min.cleanable.dirty.ratio
min.compaction.lag.ms
min.insync.replicas
preallocate
retention.bytes
retention.ms
segment.bytes
segment.index.bytes
segment.jitter.ms
segment.ms
unclean.leader.election.enable
See the Kafka documentation for full
details on the topic configs.
--create Create a new topic.
--delete Delete a topic
--delete-config <name> A topic configuration override to be
removed for an existing topic (see
the list of configurations under the
--config option).
--describe List details for the given topics.
--disable-rack-aware Disable rack aware replica assignment
--force Suppress console prompts
--help Print usage information.
--if-exists if set when altering or deleting
topics, the action will only execute
if the topic exists
--if-not-exists if set when creating topics, the
action will only execute if the
topic does not already exist
--list List all available topics.
--partitions <Integer: # of partitions> The number of partitions for the topic
being created or altered (WARNING:
If partitions are increased for a
topic that has a key, the partition
logic or ordering of the messages
will be affected
--replica-assignment A list of manual partition-to-broker
<broker_id_for_part1_replica1 : assignments for the topic being
broker_id_for_part1_replica2 , created or altered.
broker_id_for_part2_replica1 :
broker_id_for_part2_replica2 , ...>
--replication-factor <Integer: The replication factor for each
replication factor> partition in the topic being created.
--topic <topic> The topic to be create, alter or
describe. Can also accept a regular
expression except for --create option
--topics-with-overrides if set when describing topics, only
show topics that have overridden
configs
--unavailable-partitions if set when describing topics, only
show partitions whose leader is not
available
--under-replicated-partitions if set when describing topics, only
show under replicated partitions
--zookeeper <urls> REQUIRED: The connection string for
the zookeeper connection in the form
host:port. Multiple URLS can be
given to allow fail-over. 咱们使用如下命令创建一个测试的topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test创建的时候需要指定 zookeeper 集群的地址,--topice是指定名字test
如果没错会显示 Created topic "test". 说明创建成功
可以通过如下命令验证
[root@localhost kafka_2.10-0.10.1.0]# bin/kafka-topics.sh --zookeeper localhost:2181 --describe
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0可以看到test topic已经创建成功
4. 通过Kafka发送消息
kafka提供命令行输入脚本来测试服务器是否工作正常,可以使用如下命令进行发送(同样方式查看帮助)
[root@localhost kafka_2.10-0.10.1.0]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
kafka is cool--broker-list:指定kafka服务器的信息
5. 接收信息
可以启动一个consumer(消费者,消息接收、处理者)来接收刚才producer(生产者,消息发送者)的消息
[root@localhost kafka_2.10-0.10.1.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
kafka is cool
--bootstrap-server:指定kafka服务器配置
--from-beginning:说明接收所有消息(从开始起)
终于可以开心的玩耍了
为什么要用消息中间件?
1. 解耦
其实很多架构及编程思想都是解决解耦的问题的,其实这个思想我自认为应该来自与工业制造,假设一台汽车如果没有合理的对发动机、地盘等结构进行解耦,估计是没有办法进行独立生产,然后进行组装的,把这种思想用于软件开发、架构设计里其实是一样的,目的就是让各个零部件(组件)可以单独开发(生产),然后进行拼转,当然如果符合某种制式(标准)的组件是可以随意更换的(其实就是接口的用途)
2. 冗余
电子电路的发明,以及替代了很多机械结构的好处之一就是电子电路很容易做到冗余,传说F22战斗机一般的电子系统都是四路冗余,被击干坏了一部分,并不影响整体的性能(服务),当然消息系统通过制定标准的接口,也可以简单的实现冗余(所有的分布式系统都可以实现冗余好吧)
3. 扩展
说到扩展一般要求是水平扩展能力(加十台服务器即可获得十台服务器的性能),并非垂直扩展(加十台服务器可能只获得两台服务器的能力提升),当然这种水平扩展能力一般都需要无状态的组件设计(通常理解没有SESSION,或者自己封装SESSION),如果没个几百上千万的用户,还是不要劳民伤财了
4. 峰值处理能力
说道峰值处理能力(消峰),也是消息中间件在部分架构中优于RPC(远程方法调用)的原因之一,因为消息中间件可以用一个列队(内存Queue)之类的东西,把所有的业务请求缓存其中,等待业务服务器在列队中自助取用,这个列队(内存)就好比一个请求的缓冲垫,当然只要良好的监控这个内存缓冲垫(不要溢出),并且有良好的机制防止这块内存crash(崩溃),这种方法还是挺安全的,当然还是有一个另外的缺点,就是由于有这个内存的列队,很多请求处理都是异步的,是的如果你用过AJAX,你就会明白所有的业务请求都需要一个回调,同时还要处理这个回调,但JS是在浏览器运行与用户及时交互,但后台架构如果是异步+回调,同时还需要把响应反馈给前端(oh omg),还是不要劳民伤财了
5. 异步通讯
由于有这个内存,当然就可以异步通讯,如果业务没必要需要处理这么大的数据,还是不要劳民伤财了
常用的消息中间件有哪些?
1. RabbitMQ
Erlang语言,支持AMQP、XMPP、SMTP、STOMP,支持负载均衡、数据持久,支持P2P和发布/订阅
2. Redis
基于键值对的NoSql数据库(Map集合能干的事太多了,当然Map就是键值对),同时支持列队服务(据说是轻量级),消息小于10k时性能比RabbitMQ好,大于的时候会比RabbitMQ差(据传说)
3. ZeroMQ
没有服务器中间件,应用程序集成需要通过库(SDK)来集成服务器功能,很明显开发工作量亚历山大
4. ActiveMQ
Apache的又一产品线,据说是最为流行的中间件(为什么没研究它呢?见后面),实现了JMS of J2EE,支持持久化、P2P,传说支持XA事务(二段事务),这个有点牛,就是不知道性能怎么样
5. Kafka
Apache维护的产品线(顶级项目),主要是为高性能而生,据说可以做到O1的性能,宣传是下一代消息中间件(我们要研究下一代,嘿嘿),支持数据持久化、同时支持数据在线、离线处理,不支持XA事务(由于侧重点不同)
Kafka架构简介

1. Producer 生产者
一般理解生产数据的一方,有的时候也可以理解为发起请求需要服务的一方,Kafka中Producer直接访问Kafka集群,并且是数据通过push(推送)的方式,压入到Kafka的列队中,这里采用push的方式可以确保数据及时到达列队中
2. Broker 代理
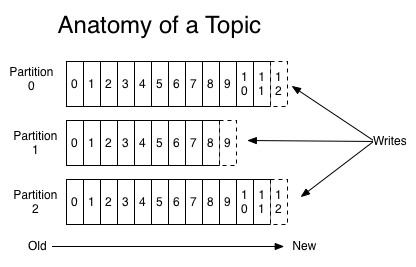
topic是数据保存的名字(文件名),每一个topic对应一个Broker(Broker负责保存Topic的内容),一个Broker由多个Partition组成,每个Partition均匀分布在kafka集群之中(Partition分布于多台服务器,致使Kafka具备冗余)
3. Consumer 消费者
一般消费者指的是提供服务的一方,记录日志、处理业务逻辑之类的,Kafka的Consumer设计通过pull(拉)的方式,到Kafka集群中拉数据,这样的设计可以降低Consumer的压力(吃多少拿多少,当然降低压力)
4. Kafka 与 Zookeeper
Kafka 经历数次改版,老的版本消费者并非从Kafka集群,而是zookeeper集群中直接拿数据,新版本已经修复这个设计问题
结后语
通过对kafka的简单了解,后面就准备开始开发Producer和Consumer拉,动手写代码的感觉总是很好 :D
同时感谢 郭俊 先生的指导,他的博客 http://www.jasongj.com/















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









